
728x90
SMALL

- 오늘은 Selenium 패키지를 이용해서 동적인 페이지(스트리밍 사이트, 유튜브 랭킹 페이지 등)를 크롤링하고 관련 시각화를 진행해보았습니다. 후반부에는 여러 엑셀 파일들을 통합해보는 실습도 추가적으로 완료했습니다.
🗞️ Selenium
- Selenium 패키지는 chromedriver를 제어하거나 원하는 정보(동적 HTML)를 크롤링하기 위해서 사용됩니다.
- 또한, 코드로 브라우저를 제어하고, 웹 애플리케이션을 테스트하거나 데이터를 스크래핑할 수도 있습니다.
- 그 중에서도 Selenium의 webdriver 모듈은 웹 브라우저를 자동화하는 역할을 합니다.
🌐 Webdriver
- webdriver.Chrome()
- 크롬 브라우저를 실행해주는 Selenium WebDriver 객체를 생성할 때 사용되는 클래스입니다.
- driver.get(url)
- get() 함수는 WebDriver를 통해 브라우저를 실행하고, 해당 URL에 접속해주는 역할을 합니다.
- driver.page_source
- 해당 URL에 있는 모든 HTML을 읽어들이는 역할을 해줍니다.
👉🏻 CSS 선택자
- Selenium에서 특정 ID 값을 가진 요소를 선택할 때는 '#'을 사용합니다. 이 선택자는 HTML에서 id="..." 속성을 가진 요소를 가리킬 수 있습니다.
- 한 가지 유의할 점은 HTML 문서 내에서는 동일 ID 값을 중복해서 가질 수가 없다는 것입니다.
- 또한, 특정 클래스 값을 가진 요소를 선택할 때는 '.'을 사용하고, 이 선택자는 HTML에서 class="..." 속성을 가진 요소를 찾을 때 활용됩니다.
- BeautifulSoup 내 select() 함수에도 이 CSS 선택자를 이용해 아래와 같이 특정 태그들을 가져올 수 있습니다.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
# class가 name인 span들을 모두 찾아라!
tags_span = soup.select('span.name')
print(tags_span)
# 출력값
'''
[<span class="name"> 바나나 </span>,
<span class="name"> 파인애플 </span>]
'''
# id가 fruits2인 친구가 class가 name인 span 자식을 가지고 있으면 찾아라!
tags_p = soup.select('#fruits2 > span.name')
print(tags_p)
# 출력값
# [<span class="name"> 파인애플 </span>]
# div.sale의 내부에서 span.name을 찾아라!
tags_banana = soup.select('div.sale span.name')
print(tags_banana)
# 출력값
# [<span class="name"> 바나나 </span>]- 특히 a 태그 내 href 속성을 가져오려면 간단히 select('a')를 호출한 다음, 요소의 .text에서 ['href']를 인덱싱해주면 해당 link를 가져올 수도 있게 됩니다.
🗞️ 동적 페이지 크롤링 해보기
🎶 스트리밍 사이트 크롤링

- 멜론의 Top 100 페이지는 대략적인 구조가 위와 같이 나타납니다.
- 따라서, 먼저 tr 태그까지 탐색(soup.select('table > tbody > tr'))을 하고 난 후,
- 그 안에서 각각의 div로 들어가 해당 텍스트(제목과 아티스트명)를 추출해낼 수 있었습니다.
- 결과적으로 다음과 같은 구조의 데이터프레임을 생성했습니다!
| 서비스명 | 순위 | 타이틀 | 아티스트 |
| Melon | 1 | REBEL HEART | IVE (아이브) |
| Melon | 2 | HOME SWEET HOME (feat. 태양, 대성) | G-DRAGON |
| Melon | 3 | 나는 반딧불 | 황가람 |
| ... | ... | ... | ... |
- 위와 같은 과정을 멜론, 벅스, 지니에서도 동일하게 수행한 다음, 각각의 데이터프레임을 엑셀 파일로 저장하였고,
- 각 파일들을 하나의 파일로 연결하기 위해 pd.concat([merged_data, df], ignore_index=True) 함수를 사용해서 통합 파일로 만들어내기 성공!
🥇 유튜브 랭킹 페이지 크롤링
- 저희가 크롤링한 페이지의 URL은 다음과 같았습니다.
- https://youtube-rank.com/board/bbs/board.php?bo_table=youtube
- 여기서 youtube-rank.com는 root 폴더를 뜻하고,
- 그 아래 board, bbs 폴더가 있고, 그 안에 board.php 파일이 존재한다는 뜻입니다.
- board.php?의 ?는 파일과 파라미터를 구분해주는 구분자이고,
- bo_table은 파라미터명, 마지막으로 =youtube는 파라미터에 입력되는 값을 의미합니다.
- https://youtube-rank.com/board/bbs/board.php?bo_table=youtube&page=2
- 위 URL은 2페이지 즉, 101위부터 200위까지 나타나있는 페이지의 URL로 우선 이 URL에서의 &는 각 파라미터를 구분하는 구분자입니다.
- 이 페이지들에서 가져올 정보는 랭크되어있는 채널의 카테고리, 채널명, 구독자 수, 총 view 수, 그리고 보유하고 있는 비디오 개수입니다. 해당 정보들을 1위부터 1000위까지 가져와야합니다.
⚠️ IllegalCharacterError?
- 과정이 순조롭게 진행되고 있던 찰나에...! 갑자기 IllegalCharacterError 오류가 발생했습니다.
- 타이틀 중에서 이모지를 포함하고 있는 타이틀이 있었는데, 이것을 엑셀 워크시트에서 허용하지 않아서라고 합니다.
- 엑셀 파일을 구성하고 있는 XML 포맷에서는 제어문자나 특정 특수문자를 사용할 수 없기에 이 문자를 처리해줘야 했습니다.
- 그래서 저는 데이터를 엑셀 파일로 저장하기 전에 정규 표현식을 사용해서 해당 타이틀에서의 이모지를 제거했고, 이후 파일로 저장하게 되었습니다.
- 사용된 정규 표현식 함수는 다음과 같습니다.
import re
def clean_text(text):
return re.sub(r'[\x00-\x08\x0B-\x0C\x0E-\x1F]', '', text)- 여기서 사용된 re.sub(pattern, repl, string, count=0, flags=0) 함수에는 먼저 찾고자 하는 패턴(pattern), 패턴에 매칭된 부분을 대체할 문자열(repl), 대체 작업을 수행할 대상 문자열(string) 등이 들어가게 됩니다.
- 이 re.sub()을 사용해서 해당 타이틀을 걸러냈더니 아주 깔끔✨하게 엑셀로 저장되었습니다.
- 아니면 .replace('\x08', '')를 이용해서 문자열을 대체시키는 방법도 있고, 엑셀 파일로 저장할 때 엔진을 바꿔(engine='xlsxwriter') 저장하는 방법도 있었습니다!
🎨 카테고리별 시각화
- 먼저 크롤링된 Subscriber는 모두 문자열이기 때문에 이를 시각화하기 위해서 '9590만'과 같은 값을 95,900,000와 같이 int형으로 변경(astype)해 새로운 컬럼으로 저장했습니다.
- 첫 시각화 목표는 카테고리별 구독자 수를 구해 파이 차트를 만드는 것이었습니다.
- 관련해서 피벗 테이블을 만들기 위해 pd.pivot_table(values='subscriber', index='category', aggfunc=['sum', 'count']) 함수를 사용했는데,
- 데이터프레임의 '카테고리'를 기준으로 그룹을 만든 후, 각 그룹에서 '변경된 구독자 수' 열에 대해 sum과 count를 구해, 각 카테고리별로 '구독자 수'의 총합과 항목의 개수를 보여주는 피벗 테이블을 만들 수 있었습니다.
- 그 후 reset_index()로 인덱스 다시 설정도 하고~ sort_values()로 구독자 수 기준 내림차순 정렬도 수행했습니다!
- 시각화한 차트가 시각적으로 이쁘지(?)가 않아서 살짝 수정을 거쳐 아래와 같이 몇 개 카테고리에 대해서만 시각화를 해보았습니다.
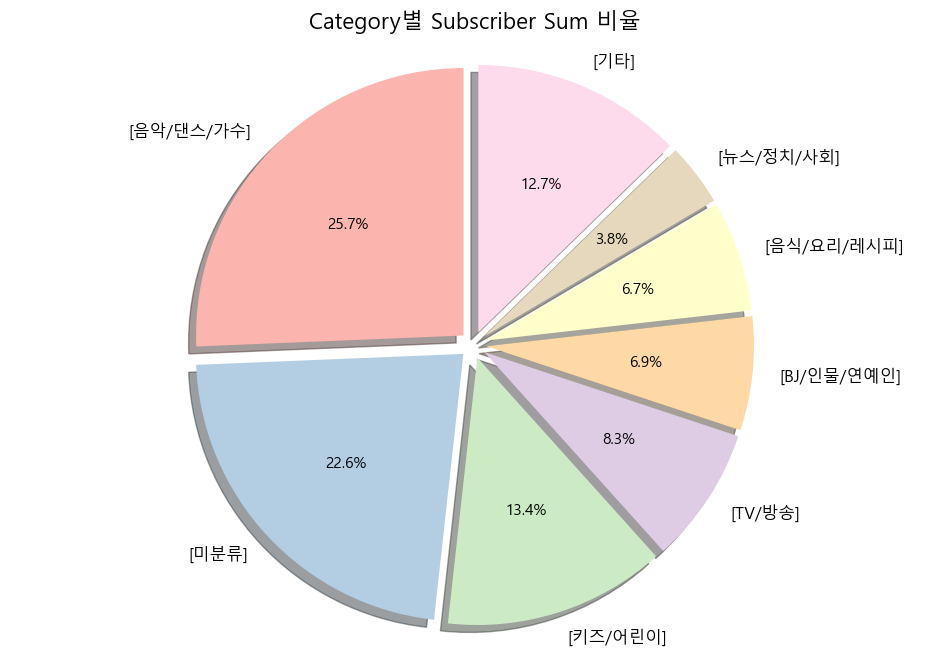
- 이어서 정렬 방식을 다르게 하여 이와 유사한 카테고리별 카테고리 수의 차트도 하나 더 만들어낼 수 있었습니다.

🫱🏻🫲🏻 다량의 엑셀 데이터 통합
- 통합하기 전에 먼저 하나의 데이터만 살펴보기로 했습니다. 데이터는 월별 외국인 관광객 데이터입니다.
- 파일이 kto_201001.xlsx부터 시작해 kto_202005.xlsx까지 제공되어 있었는데, 각 파일에는 국적, 관광, 상용, 공용 등의 컬럼이 포함되어 있었습니다.
- 국적에는 대륙 목록(아시아주, 미주, 대양주, 교포소계 등)에 해당되는 곳이 몇 군데 있었기에 이 목록들을 unique()로 확인 후,
- "df.국적.isin(continents) == False"와 같은 조건을 걸어 제외시켰습니다.
- 이를 저장하기 위해 reset_index(drop=True)로 인덱스를 초기화했는데, 여기서 drop=True를 써줘야 기존 인덱스를 새로운 컬럼으로 추가하지 않고 인덱스가 세팅됩니다.
- 그리고 다시 어떤 국적이 어떤 대륙에 포함되는지를 알아내고 추후 그룹화하기 위해서 '대륙' 컬럼을 추가해 수작업으로 대륙도 넣어줬습니다.
- 관광객의 비율을 알아내기 위해서, 아래와 같은 코드를 통해 또 다시 새로운 비율 컬럼을 추가했습니다.
df['관광객_비율(%)'] = round(df['관광'] / df['계'] * 100, 1)
- 위 과정은 데이터를 전처리하는 과정이었고, 뭔가 주저리주저리 길어지는 것 같기도 하고... 가독성도 떨어지는 것 같으니 이를 함수화해서 일괄적으로 125개의 파일에 적용해봅시다!
✨ 전처리 과정을 함수로 선언
- 위에 적어놓은 과정들을 함수로 만들어보니 다음과 같이 만들 수 있었습니다. 훨씬 보기 편한 것 같네요 :)
def create_kto_data(yy, mm):
# 1. 불러올 Excel 파일 경로를 지정
file_path = f'./data/kto_{yy}{mm}.xlsx'
# 2. Excel 파일 불러오기
df = pd.read_excel(file_path, header=1, skipfooter=4, usecols='A:G')
# 3. "기준년월" 컬럼 추가
df['기준년월'] = f'{yy}-{mm}'
# 4. "국적" 컬럼에서 대륙을 제거하고 국가만 남기기
# 대륙 컬럼 생성을 위한 목록
ignore_list = ['아시아주', '미주', '구주', '대양주', '아프리카주', '기타대륙', '교포소계']
# 대륙 미포함 조건
condition = (df['국적'].isin(ignore_list) == False)
df_country = df[condition].reset_index(drop=True)
# 5. "대륙" 컬럼 추가
continents = ['아시아'] * 25 + ['아메리카'] * 5 + ['유럽'] * 23 \
+ ['오세아니아'] * 3 + ['아프리카'] * 2 + ['기타'] + ['교포']
df_country['대륙'] = continents
# 6. 국가별 "관광객 비율(%)" 컬럼 추가
df_country['관광객_비율(%)'] = round(df_country['관광'] / df_country['계'] * 100, 1)
# 7. "전체 비율(%)" 컬럼 추가
tourist_sum = sum(df_country['관광'])
df_country['전체_비율(%)'] = round(df_country['관광'] / tourist_sum * 100, 1)
# 8. 만들어진 데이터프레임 반환
return df_country- 테스트까지 완벽하게 통과했으니 이제 for 문으로 전체 데이터에 적용해본 후, 통합해봅시다!
✨ 통합 과정
- 실제로 함수에 기준년월을 넣어줄 때에는 create_kto_data(str(yy), str(mm).zfill(2))와 같이 zfill(2)을 사용했는데,
- 그 이유는 mm이 1~9의 값일 때, 이를 01~09로 처리하기 위해서입니다.
- 반복문을 돌며 하나의 데이터프레임에 모든 데이터들을 concat() 시켜주면 통합 데이터가 완성! (try-except 문도 사용!)
🌟 국적별로 파일을 분리하려면?
for nation, temp in df.groupby('국적'):
filename = f'[국적별 관광객 데이터] {nation}.xlsx'
temp.to_excel(f'./국적별/{filename}', index=False)
🤔 16일차 회고
- selenium을 활용한 크롤링 작업은 사실 학부 수업 내 진행되는 프로젝트에서 주로 활용된 작업이었습니다.
- 졸업 작품을 구현할 때에도 멜론에서 가사를 크롤링할 때, 음악 정보들을 크롤링할 때에도 역시 selenium을 사용했었습니다.
- 그 당시에는 구현하기에 급급해서 크롤링하는 구조가 어떤지도 제대로 살펴보지 못했고, 절차적이지도 못했었는데 오늘 이 시간을 통해서 조금은 더 깔끔하게 스크래핑할 수 있게 되었습니다!
- 후반부의 데이터 통합 과정에서도 함수로 가독성있게, 그리고 효율적으로 처리하는 것을 쭉쭉 따라가보며
- "앞으로도 일관된 데이터를 처리하고 통합할 때는 이렇게 처리해야겠구나"를 배운 오늘인 것 같습니다.
- BeautifulSoup이나 Selenium 교육 과정은 오늘로써 마무리되지만, 추후 프로젝트를 진행할 때 능숙하게 다룰 수 있도록 사전 연습을 많이 해둘 필요가 있겠습니다!
728x90
LIST
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 My 돌고래 (2) | 2025.02.25 |
|---|---|
| 🤔 그 많던 사과는 누가 다 먹었을까 (2) | 2025.02.21 |
| 🤔 심부전 데이터와 BeautifulSoup (6) | 2025.02.17 |
| 🤔 가설 검정과 plotly 그리고 '워라벨' (0) | 2025.02.14 |
| 🤔 Iterator와 Generator 그리고 한국인의 삶 (2) | 2025.02.12 |