
728x90
SMALL

- 오늘은 심부전 관련 의료 데이터를 가지고 전처리, 통계 처리 및 연관된 여러 시각화 작업을 진행했습니다. 또 오후에는 야후 파이낸스 페이지를 크롤링하며 실시간 데이터를 가지고 간단한 시각화도 해보았습니다!
- 심부전 데이터를 통한 분석 프로젝트는 아래 글에 자세히 작성되어 있습니다.
[Data Analysis] 심부전 데이터
해당 글에서는 전에 진행되었던 심부전 데이터로 분석했던 내용들을 정리해보고자 합니다. 🏥 심부전 데이터 분석 프로젝트 🩺 심부전 데이터셋 변수 파악변수명변수 설명Age나이Sex성별Ches
injoycode.tistory.com
🗞️ 크롤링 데이터 분석 프로젝트
✨ 크롤링과 스크래핑
- 크롤링이 데이터를 찾는 작업이라면, 스크래핑은 데이터를 추출하는 작업을 뜻합니다.
- 크롤링과 스크래핑은 "원하는 데이터를 모을수 있다"는 점에서는 유사하지만, 웹 크롤링은 웹 페이지 링크(URL)를 타고 계속해서 탐색을 이어나가는 방식이고, 웹 스크래핑은 데이터 추출을 원하는 대상이 명확해서 특정 웹사이트만을 추적한다는 차이점이 존재합니다.
🤖 robots.txt
- 웹 사이트 소유자가 크롤러에게 제공하는 지침서로, 크롤러가 접근할 수 있는 영역과 접근할 수 없는 영역을 명확하게 정의해놓은 파일입니다.
💡 robots.txt의 역할
- 크롤링을 제한하거나, 서버의 부하를 감소시키거나 사이트 맵을 제공하는 등의 역할을 수행합니다.
- User-agent : 크롤러를 식별하는 부분으로, 특정 크롤러 또는 모든 크롤러에 대한 지침을 제공
- Disallow: 크롤링을 금지할 디렉토리나 페이지를 지정합니다.
- Allow: 크롤링을 허용할 디렉토리, 페이지를 지정합니다. (Disallow와 함께 사용될 때)
- Sitemap: 사이트 맵 파일의 위치를 제공합니다.
🧼 웹 스크래핑을 위한 BeautifulSoup
- 웹페이지의 HTML을 구조적으로 분석하고 원하는 데이터를 추출하는 데 사용되는 Python의 라이브러리입니다.
- 객체에는 두 가지 변수가 입력되어야 하는데, 하나는 읽은 html 문자열, 그리고 하나는 파싱하는 parser를 입력해주어야 합니다.
- 여기서 parser에는 html이나 xml을 읽을 수 있는 parser가 포함됩니다.
- 처음에 BeautifulSoup 객체를 변수에 저장한 뒤, 이후 객체의 메서드를 이용해 데이터의 추출이 가능해집니다.
- html 문서는 시작과 끝이 구분이 안 되는 단순 문자열 데이터이지만, parser로 읽어온 html 문자열은 각각의 요소를 구분할 수 있는 문서로 변환됩니다.
💡 제공되는 기능
- soup.stripped_strings
- 텍스트(태그 사이의 글)들을 추출할 수 있는 키워드입니다.
- find(id='id') / find_all(class_='class')
- find('태그명') 함수는 동일 태그가 여러 번 반복해 있을 경우에, 맨 처음 1개만 추출하여 문자열(bs4.element.Tag 타입)로 반환해주는 아이이고,
- find_all() 함수는 동일 태그가 여러 번 있을 때 모두 추출하여 리스트(bs4.element.ResultSet 타입)로 반환해주는 친구입니다.
- attrs (속성 검색)
- find() 또는 find_all()에 사용할 수 있는 옵션입니다.
- 특정 속성을 기준으로 검색할 때 attrs={'속성명': '값'} 형태로 지정해서 원하는 요소를 필터링할 수 있게끔 해줍니다.
✨ 야후 파이낸스 데이터 크롤링
- URL을 requests에게 넘겨줄 때에는 반드시 프로토콜을 포함하여 넘겨주어야 합니다.
- 웹 페이지를 요청하기 위해서는 requests 모듈의 get() 함수를 이용하고,
- 응답받은 값에서 HTML 문서만 가져오기 위해 requests.text를 사용하면 됩니다.
- 가져올 때 'Edge: Too Many Requests' 와 같은 오류가 발생할 수도 있기 때문에 아래와 같이 따로 header를 설정 후, 포함해서 요청을 해준다면 응답을 잘 받아올 수 있을 것 같습니다!
headers = {
'User-Agent': 'Mozilla/~ AppleWebKit/~ Chrome/~ Safari/~',
'accept': 'text/html,...,application/xml;...,image/webp,image/apng,...'
}
response = requests.get(url, headers=headers)- 이렇게 야후 파이낸스 페이지에 접속해 HTML 코드를 응답으로 받아오게 되면,
- BeautifulSoup은 받아온 HTML을 트리 구조로 파싱하게 됩니다.
- 추가적으로 저희는 해당 페이지에서 날짜와 종가를 가져온 뒤 시각화 과정을 하기 위해, <tr> 태그를 찾아 반복문으로 <td>들을 확인하고, 해당 데이터를 골라내어 가져왔습니다.
# 첫 번째 tr 태그인 헤더를 제외하기 위해 1부터 시작
for i in range(1, len(rows)):
cells = rows[i].find_all('td')
# 야후 파이낸스에서 일자 + 종가를 포함하는 tr 구조: 7개의 td
if len(cells) == 7:
# 날짜는 pandas의 to_datetime() 함수로 변환
date = pd.to_datetime(cells[0].text, format='%b %d, %Y')
close_price = cells[4].text.replace(',', '').replace('.00', '')
dates.append(date)
prices.append(int(close_price))
🎨 스크랩핑된 데이터 시각화
- 최종적으로 가져온 데이터인 날짜별 종가 데이터를 선 그래프로 표현하며 마무리했습니다.
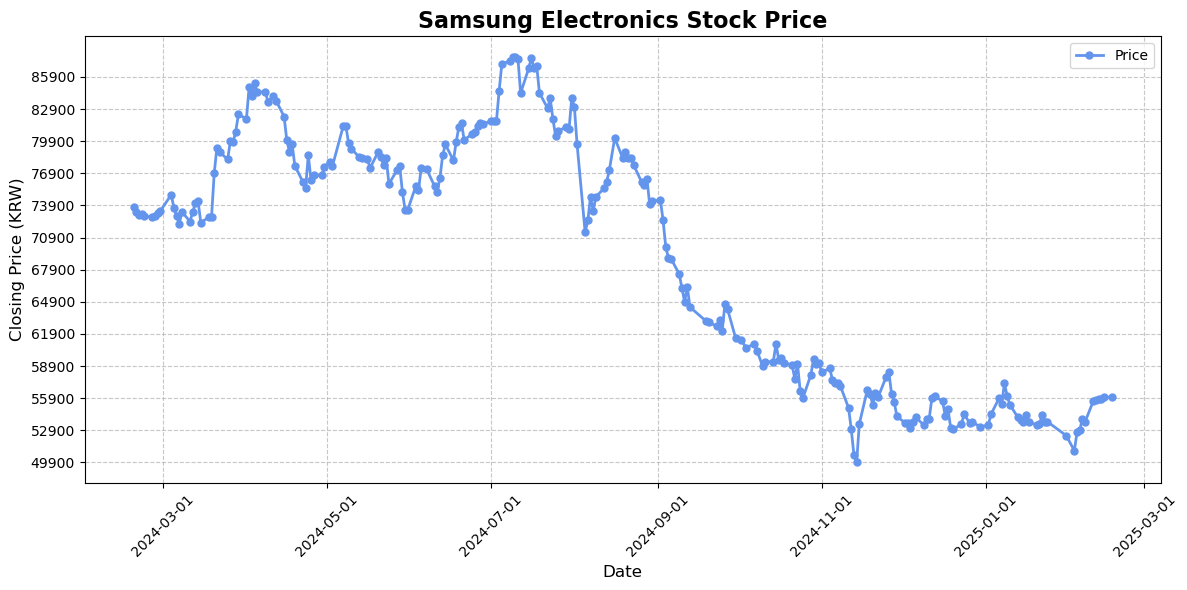
💡 pd.read_html()
- 간혹 테이블 구조가 명확한 페이지라면, pandas 라이브러리의 read_html() 함수를 통해 코드 몇 줄로 간단히 표 데이터를 불러올 수도 있습니다.
from io import StringIO
response = requests.get(url, headers=headers)
data = pd.read_html(StringIO(str(response.text)), header=0)[0]- read_html()은 HTML 내 <table> 태그를 자동으로 찾아 파싱해 DataFrame을 생성합니다.
- 다만, 클래스나 속성이 동적으로 수시 변경되는 웹페이지(특히, 야후 파이낸스 같은 페이지)에서는 원하는 표를 제대로 읽지 못할 때도 있기 때문에, 상황에 따라 BeautifulSoup과 병행해서 사용하는 것이 좋습니다.
🤔 15일차 회고
- 하루 만에 정말 많은 것들을 한 기분입니다. 저번 주에 넷플릭스 데이터를 분석할 때에는 하루 동안 하나의 데이터만을 붙들고 분석을 진행했었는데, 속도가 붙으니 하루에도 2~3개 정도의 데이터 분석이 가능해진 것 같습니다.
- 물론 상세히 들어간다면 더욱 오래 걸리는 작업들이 많겠지만, 하나하나씩 코드를 심화시켜가며 데이터 분석에 박차를 가하는 제 모습이 너무나도 뿌듯하고, 배우는 보람을 충분히 느끼고 있습니다.
- 데이터 분석을 하기에 앞서 변수들(컬럼들)을 아주 상세히 알고 있어야겠다는 마음이 들었습니다. 먼저 데이터를 알아야 어떤 방향으로 분석을 진행할지도 명확해지고, 그에 따른 시각화도 보기 좋게 만들 수 있을 것 같습니다.
- 제가 여태 프로젝트를 진행하며 크롤링을 수행했을 당시에는 robots과 header가 어떤 역할을 하는지도 제대로 몰랐어서 무차별적으로 크롤링을 해댄 적이 있었습니다. 그런 과거의 저를 반성하며 현재의 저는 더욱 꼼꼼히 그런 제한 사항들을 살펴볼 필요가 있다고 생각했습니다.
- 오늘은 정적인 HTML을 BeautifulSoup으로 건드려봤다면, 내일은 Selenium으로 동적인 HTML을 한 번 건드려보고자 합니다 !!
728x90
LIST
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 그 많던 사과는 누가 다 먹었을까 (2) | 2025.02.21 |
|---|---|
| 🤔 Selenium은 어디까지 크롤링할 수 있을까? (0) | 2025.02.18 |
| 🤔 가설 검정과 plotly 그리고 '워라벨' (0) | 2025.02.14 |
| 🤔 Iterator와 Generator 그리고 한국인의 삶 (2) | 2025.02.12 |
| 🤔 Python 이론 살짝 업글해보기 (4) | 2025.02.11 |