
728x90
SMALL

- 오늘은 오전에 데이터 전처리와 관련하여 총 정리해보는 시간을 가져보았고, 병원 No-show 환자 데이터, 그리고 시계열 데이터인 애플 주식 데이터를 가지고 분석해보았습니다!
- No-show 데이터 관련하여 분석한 과정은 다음 글에 기술되어 있습니다!
[Data Analysis] 병원 No-Show 데이터
이번에는 특정 병원에서의 No-show 데이터로 분석했던 내용들을 정리해보고자 합니다. 🏥 No-show 환자를 줄이자! 프로젝트특정 A 병원에서는 예약한 환자들이 오지 않아 진료가 원활히 이루어지
injoycode.tistory.com
🤨 데이터 전처리를 하는 이유
- 데이터 전처리 과정에 따라 분석 결과가 유의미하거나 무의미한 결과를 도출할 수 있습니다.
- 그리고 전처리는 자동화하기 어려워서 거의 다 코드(수작업)로 진행해야 한다는 특징이 있습니다.
- 일반적으로 분석 프로세스의 전체 실행 시간 중 60~70%를 전처리에 쓴다고 합니다. 이렇게나 전처리가 중요했네요.
- 그래서 여러 분석이 가능하도록 데이터(특성, 요소, 변수)를 추출하고, 결측치를 처리하고, 이상치를 제거하고,
- 더 나아가서 분포를 변환하고, 표준화, 카테고리화 등을 진행하고, ML 쪽에서는 차원 축소 등의 작업도 필요하게 된 것입니다.
🪞 데이터 왜곡
- 데이터셋의 결측치나 이상치 등이 발생되면 분석 결과가 왜곡이 될 수가 있습니다.
- 결측치가 발생했을 때에는 해당 데이터를 제외하고 분석하는 것이 일반적이지만, 결과적으로는 부정확한 예측이나 결론을 가질 수도 있기 때문에 신중하게 판단하는 것이 좋습니다.
- 또한, 이상치는 수집한 데이터에서 다른 관측치들과 비교했을 때, 상당히 극단적인 값을 나타내기 때문에 이상치가 존재할 경우, 원인 분석 후 결측치와 유사하게 제거를 할지, 대체를 할지를 신중히 결정해야겠습니다.
- 마찬가지로 중복된 데이터 역시, 분석 결과에 대한 신뢰도를 떨어뜨릴 수 있습니다.
🙅🏻 모델 정확도 저하 방지를 위해서는?
💡 데이터 타입의 일관성을 유지하자!
- pandas를 이용할 경우, 데이터 타입의 형 변환을 통해 일관성을 유지해주는 것이 좋습니다.
- 관련하여 별 건 아닐 수 있지만, data.astype(int)는 int32비트로 형 변환을 시켜주고,
- data[['A', 'B', 'C']].apply(pd.to_numeric) 이런 식으로 to_numeric()을 사용해준다면 int64비트로 변환이 됩니다.
💡 결측치는 반드시 처리하자!
- 결측치는 처리할 수 있는 방법이 아래와 같이 여럿 있는만큼 반드시 처리해주고 넘어가주는 것이 좋습니다.
- 결측값이 있는 행/열을 제거하는 방법은 data.dropna(axis={0/1}) 사용하기!
- 그리고 결측치를 대체하는 방법에 좀 여러 가지가 존재하는데,
- 0으로 대체: fillna(0)
- 평균값으로 대체: fillna(data.mean())
- 카테고리형 데이터에서 최빈값으로 대체: data.apply(lambda x: x.fillna(x.mode()[0]))
- apply(): 각 열에 대해 특정 내용을 적용시켜주는 함수
- mode(): 각 열의 최빈값을 구해주는 함수
- 수치형 데이터에서 최빈값으로 대체: data.fillna(data.mode().iloc[0])
- 'NaN' 값을 다른 컬럼값으로 대체: data.fillna({'A':'a', 'B':'d', 'C':'i'})하는 방법들이 있겠습니다.
💡 이상치도 반드시 처리해주자!
- 이상치는 boxplot(plt.boxplot())으로 시각화해보시면, 간단히 찾아낼 수 있습니다.
- 발견된 이상치는 그 비율에 따라 제거하거나 대체하면 되겠습니다.
🌟 목적에 맞는 특징을 추출하자!
- 상관 분석과 주성분 분석으로 목적에 맞는 특징을 추출할 수 있습니다.
- 상관 분석에서는 상관 계수를 이용해 변수 간의 상관 관계가 높은 것을 찾아낼 수 있고,
- 주성분 분석은 차원을 축소해 잠재적인 변수를 추출해낼 수 있습니다. 이 주성분 분석은 추후 ML 파트에서 진행될 예정입니다.
📉 애플 주식 데이터 분석해보기
- 우선 주식 데이터를 분석하기 전에 시계열 데이터 관련한 지식부터 먼저 배우고! 실습을 진행했습니다.
⌚ 시계열 데이터?
- 시계열 데이터는 특정 시간 간격으로 기록된 데이터로, 보통 일정한 주기로 측정이 되는 데이터입니다.
- 이 시계열 데이터를 가지고 예측, 분류, 군집화, 이상 탐지 등을 수행할 수 있다고 합니다.
💡 시계열 데이터의 패턴
- 시계열 데이터는 총 4가지의 패턴을 가지고 있습니다.
- 추세(Trend): 시계열 데이터가 시간에 따라서 증가하거나 감소하는 경향을 보이는 패턴입니다.
- 계절성(Seasonality): 시계열 데이터가 일정한 주기를 가지고 반복되는 패턴입니다.
- 순환성(Cyclical): 추세와는 달리, 일정한 주기를 가지고 반복되지만 주기의 길이가 일정하지 않은 패턴입니다.
- 불규칙성(Irregular): 지진, 홍수, 파업, 코로나와 같은 특수한 요인에 의해 발생하는 불규칙한 패턴입니다.
💡 시계열 데이터 분석의 이해
- 시계열 데이터는 크게 두 가지 방법으로 분석을 진행할 수가 있습니다.
- 분해법: 시계열 데이터가 가지는 추세(Trend), 계절성(Seasonality), 주기(Cycle) 및 불규칙성(Irregularity)과 같은 구성요소를 분해하여 분석하는 방법입니다.
- 시간 영역 분석법: AR(Auto Regressive Model) 모형, MA(Moving Average) 모형, ARMA 모형, ARIMA(Autoregressive Integrated Moving Average)가 있는데, 이는 추후에 시계열을 더 깊게 다룰 때 다시 가져와보겠습니다.
✨ 그럼 어떻게 전처리하나?
- 먼저 시계열 데이터를 분석하겠다!! 라고 마음 먹었다면, info()를 통해 날짜 컬럼의 타입이 object인 경우에는 datetime 형으로 변환시켜주는 것이 우선입니다.
- 그리고 set_index()로 이 변환된 컬럼을 인덱스로 설정해놓고 분석을 시작하시면, 추후에 시각화할 때에도 편할 것입니다. 👍🏻
💡 결측치 처리
- 일반 데이터와 다를 게 없이 fillna() 함수를 사용하면 되는데, 이때 method='ffill'과 같이 method를 지정해주시면 되겠습니다!
- 근데 살펴보니 이 방식 말고, ffill() 함수, bfill() 함수가 따로 있더라구요. 이거 쓰면 될 것 같아요...!
- 또한, drop() 함수를 사용해서 아예 날려버리는 수도 있고, interpolate() 함수를 사용해서 대체 값을 집어넣을 수도 있습니다.
- 처음 보는 이 interpolate() 함수는 선형 보간법을 사용해서 값을 대체해주는데, 시간에 따라 시스템이 동작하는 방식을 미리 알고 있을 때,
- 또 예를 들어, 연도에 따른 온도 변화에 대한 추세를 미리 알고 있을 때와 같은 상황에서 유용하게 사용될 수 있습니다.
- 그러니 이 방법은 추세를 미리 알아야하기 때문에, 산점도로 미리 분포와 추세를 확인해 본 다음에 interpolate()를 사용하는 것이 바람직합니다.
💡 빈도 설정
- 빈도 설정이라는 것은 데이터의 최소 시간 단위를 일, 주, 월, 분기, 년 등으로 맞추는 것을 의미합니다.
- 그래서 만약 아래와 같은 데이터프레임(df)이 있을 때,
x1
date
2019-01-03 0.1
2021-11-22 2.0
2021-12-01 NaN
2023-01-05 1.2- df.asfreq('Y', method='ffill') 함수를 사용하게 되면, 매년('Y')의 마지막 날 기준으로 리샘플링해주어 다시 데이터프레임을 생성하게 됩니다.
- 그럼 데이터프레임이 요렇게 변하게 됩니다.
x1
date
2019-12-31 0.1
2020-12-31 0.1
2021-12-31 NaN
2022-12-31 NaN- asfreq() 함수는 먼저 매년 마지막 날짜(12/31)로 인덱스를 재조정하고, 재조정된 날짜에 원본 데이터에서 '정확히 일치하는 날짜'가 있는지 확인합니다.
- 그리고 method='ffill'를 주게 되면, 2019-12-31은 2019-01-03의 0.1로 채워지고, 2020-12-31도 그 전년도의 값인 0.1로 채워집니다.
💡 특징량 만들기
- rolling() 함수는 일정 개수(또는 일정 기간)씩 데이터를 묶어서 평균, 합계, 표준편차 등을 구할 수 있게 해줍니다.
- 예를 들어, 이런 식의 데이터프레임(df)이 있을 때,
x1
date
2021-01-06 5
2021-01-13 4
2021-01-20 3
2021-01-27 2
2021-02-03 7- df.rolling(2).mean()을 이용하게 되면 이전의 2개 관측치를 이용해서 이동 평균을 구해주게 됩니다.
x1
date
2021-01-06 NaN
2021-01-13 4.5
2021-01-20 3.5
2021-01-27 2.5
2021-02-03 4.5- 이런 식으로! 그래서 rolling() 함수는 시계열 분석에서 단기적인 추세를 파악하거나, 신호에 있는 노이즈를 줄이는 용도로 많이 쓰이게 됩니다.
- x1 컬럼의 첫 번째 값이 NaN이 찍히는 이유는 당연하게도 이전의 관측치가 없기 때문에 결측치가 생기는 것입니다!
💡 이전 값과의 차이 계산
- diff() 함수는 현재 시점의 값에서 직전 시점의 값을 뺀 결과를 구합니다.
- 시계열 분석에서 증가 / 감소량, 변화의 폭을 알아보고 싶을 때 매우 유용하게 사용됩니다.
💡 지연값을 추출할 때는?
- shift(n) 함수는 데이터를 n칸 위로 혹은 아래로 이동해서 지연값(Lagged value) 또는 선행값(Leading value)을 쉽게 만들 수 있는 함수입니다. 이 함수는 과거 시점의 값을 현재 시점의 설명 변수로 활용할 때 자주 쓰인다고 하네요.
- shift(n)를 사용하면 n칸씩 데이터가 밀리기 때문에 결측치가 반드시 생기기 마련입니다!
- 따라서 후에 결측치 처리가 필수적으로 요구되는 아이입니다.
🌟 원-핫 인코딩
- 시계열 데이터에서도 카테고리 변수를 수치 형태로 변환해야 할 때가 많습니다.
- 예를 들어서 요일이나 계절(봄, 여름, 가을, 겨울), 특정 이벤트 여부(유/무) 등을 변환할 때가 있는데,
- 이때 쓰이는 원-핫 인코딩은 각 범주를 열로 만들고, 해당 범주에 속하면 1 아니면 0을 넣는 방식입니다. pandas에서는 pd.get_dummies() 함수를 이용해서 변환이 쉽게 가능합니다.
✨ 실제로 주식 데이터 읽어오기
- 주식 데이터를 불러오기 위해 FinanceDataReader 라이브러리를 설치(pip install)한 후에 fdr.StockListing('KRX'), 그 중에서도 fdr.DataReader('AAPL', '2024')를 호출해서 애플 주식 데이터를 가져왔습니다.
- 가져온 뒤에 우선 애플의 주식 가격을 시각화 !

💡 샘플링
- 데이터 샘플링은 데이터의 시간 간격을 변경해서 데이터를 집약하거나 세분화하는 과정입니다.
- 샘플링에는 다운샘플링, 그리고 업샘플링이 존재하는데, 여기서 다운샘플링은 매일 기록되는 데이터를 특정 간격 데이터로 줄이는 것을 의미합니다.
- 이 샘플링으로 단기적인 변동성을 줄이고, 장기적인 추세를 파악하기 쉬워질 수 있습니다.
- pandas에서는 resample() 함수를 사용하여 시간 기반의 데이터를 쉽게 재구성할 수 있습니다.
- 그래서 저희는 df.resample('BME').mean()를 사용해 한 달 간격으로 데이터를 평균시켜 줄였고, 그 데이터로 수익률((매도 가격 - 매수 가격) / 매수 가격)을 계산해 시각화해보았습니다.
- 수익률은 pct_change()를 이용해 임의의 매도, 매수 가격을 지정해 계산하였습니다.
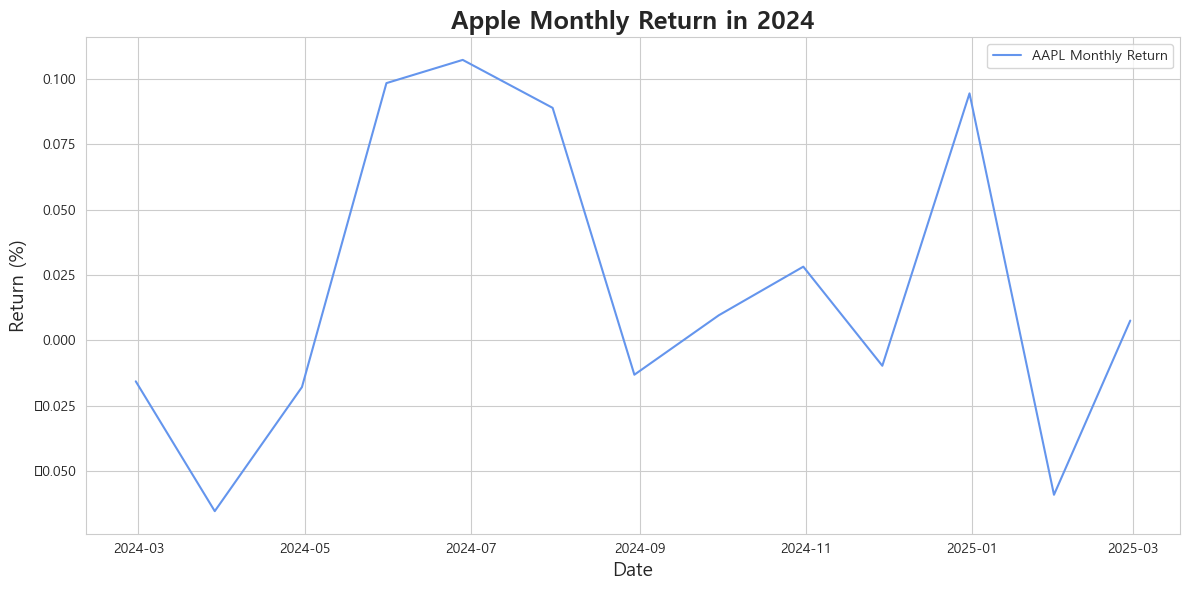
🎨 주가 흐름 파악
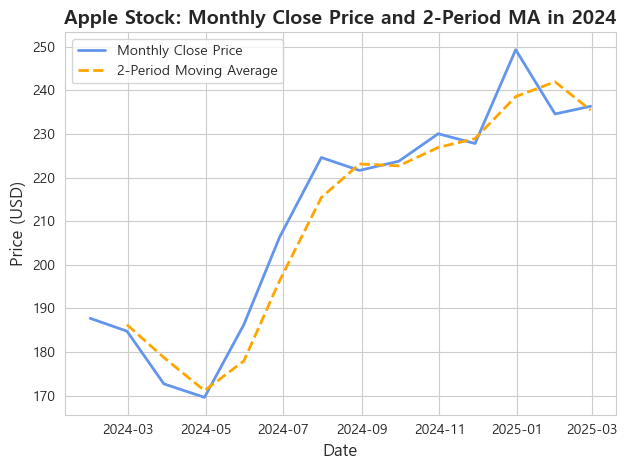
- 여기서는 2개월 단위로 종가를 rolling(2).mean()를 사용해서 평균내어 계산 후 시각화하였습니다.
- 이 차트를 통해서 주식의 월간 가격 흐름과 단순 이동평균선을 통해 전반적인 추세를 보다 명확하게 파악할 수 있었습니다.
🤔 19일차 회고
- 드디어 오늘 대망의 시계열 데이터 분석을 마지막으로 전반적인 파이썬 데이터 분석 교육은 마무리되었습니다.
- 오전에 전처리가 데이터 분석에서 90% 정도까지도 차지할 수 있다고 말씀하신 내용을 듣고 나니, 전처리에 엄청난 노력과 시간을 들여야겠다는 생각이 문득 들었습니다.
- 이전 프로젝트에서의 전처리 과정은 대충 훑고 지나가고, 시각화에만 초점을 둔 경우가 많았었는데,
- 앞으로는 데이터의 성격, 데이터가 만들어진 분야와 그 외 외부적인 변수들까지도 조금씩 고려해보며 전처리를 하고자 합니다.
- 다음 주부터는 SQL을 다뤄볼 예정이고, 주말에도 ADsP 자격증 시험과 과제도 있는만큼 오늘과 주말을 완전히 불태워야겠습니다. 🔥
728x90
LIST
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 SQL의 꽃 🌼 (0) | 2025.02.26 |
|---|---|
| 🤔 My 돌고래 (2) | 2025.02.25 |
| 🤔 Selenium은 어디까지 크롤링할 수 있을까? (0) | 2025.02.18 |
| 🤔 심부전 데이터와 BeautifulSoup (6) | 2025.02.17 |
| 🤔 가설 검정과 plotly 그리고 '워라벨' (0) | 2025.02.14 |