
728x90
SMALL

- 오늘은 초반부에 통계에서 기본적인 가설 검정(t-검정, 상관 분석)을 배우고, plotly 모듈로 간단히 인터렉티브 시각화를 진행해본 뒤, 마지막으로 어제 사용한 데이터를 가지고 자체 분석해보는 시간을 가졌습니다.
🧑🏻⚖️ 가설 검정
- 통계 분석은 크게 기술 통계와 추론 통계로 분류됩니다. 그 중에서도 기술 통계는 데이터를 요약해서 설명하는 통계 분석 기법을 의미합니다.
- 예를 들어, 월급을 집계해서 월급의 평균을 계산하는 기법이 기술 통계라고 할 수 있습니다.
- 이에 비해, 추론 통계는 어떤 값이 발생할 확률을 계산하는 통계 분석 기법입니다.
- 예를 들어, 성별에 따른 월급 차이가 있는 것으로 나타났을 때, 이 차이가 우연히 발생할 확률을 계산하는 기법입니다.
- 만약에 이 차이가 우연히 발생할 확률이 적다면, '성별에 따른 월급 차이가 통계적으로 유의하다' 라고 결론내릴 수 있습니다.
- 이와 같이 데이터를 이용해 신뢰할 수 있는 결론을 내리려면 유의 확률을 계산하는 통계적 가설 검정 절차를 거쳐야 합니다.
✨ 통계적 가설 검정
- 유의 확률을 이용해 가설을 검정하는 방법으로,
- 여기서 유의 확률은 실제로 집단 간의 차이가 없는데, 우연히 차이가 있는 데이터가 추출될 확률을 의미합니다.
- 통계 분석 결과, 유의 확률이 크게 나타났다면 집단(변수) 간의 차이가 통계적으로 유의하지 않다는 것을 의미합니다.
✨ 가설 검정 방법
- 가설을 검정하는 방법은 우선 2가지가 있는데, t-검정과 상관 분석입니다.
- t-검정은 두 집단 간의 평균 차이가 있는지 검정하는 것이고,
- 상관 분석은 두 집단 간에 상관(관련)이 있는지 검정하는 방법입니다. 하나씩 살펴봅시다.
✨ t-검정
- 파이썬에서는 scipy 모듈, 그 중에서도 stats() 함수로 t-검정을 진행할 수가 있습니다.
- t-검정을 하는 이유는 두 집단의 평균값이 우연히 나타난 차이인지, 아니면 실제로 의미 있는 차이가 있는지 판단하기 위해서 진행합니다.
💡 stats.ttest_ind(a, b, axis=0, equal_var=True)
- a와 b에는 검정할 두 집단(변수)을 넣어주시고, equal_var 옵션을 True로 놓게 되면, 집단의 분산이 같다고 설정할 수도 있습니다.
- 결과값은 "TtestResult(statistic=~, pvalue=2.3909550904711282e-21, df=~)"와 같이 나타나는데,
- 여기서 pvalue는 유의 확률을 말하고, 일반적으로 유의 확률 5%를 판단 기준으로 삼게 됩니다.
- 그래서 이 pvalue가 0.05 미만이면, 집단 간의 평균 차이가 통계적으로 유의하다고 판단할 수 있습니다.
✨ 상관 분석
- 상관 분석은 두 변수의 관계를 분석하는 기법이고, 상관 분석을 통해 도출된 상관 계수 값으로 두 변수의 관련성 여부를 판단할 수 있습니다.
- 상관 계수는 -1~1 사이의 값으로 나타나고 1에 가까울수록 양의 상관성, -1에 가까울수록 음의 상관성을 나타냅니다. 0은 두 변수가 상관 없다는 것을 의미합니다.
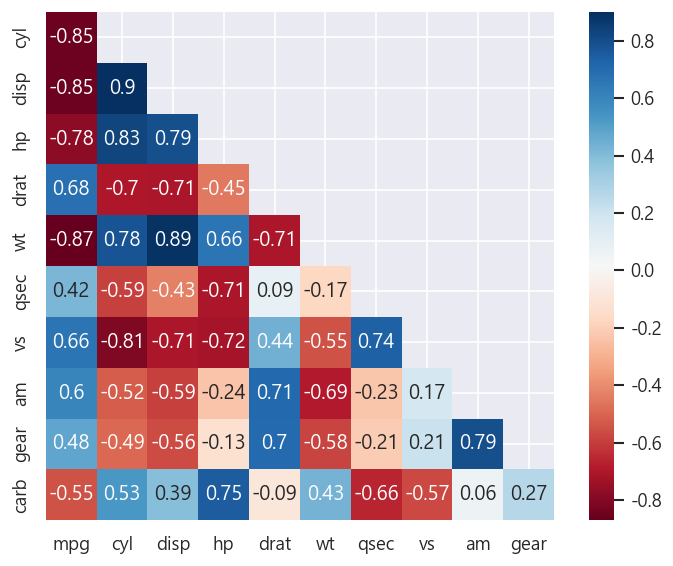
💡 df.corr()
- 상관 행렬을 만들어주는 함수로, 일부 변수들 대상으로 만들 수도 있고, 전체 데이터셋에 대한 행렬도 만들 수가 있습니다.
- 이 행렬을 토대로 히트맵(sns.heatmap()) 함수로 시각화도 할 수 있습니다.
💡 sns.heatmap(data, cmap=None, annot=None, mask=None)
- 상관 계수를 히트맵에 표시하고 싶으면, annot 옵션을 True로 설정하면 됩니다.
- mask를 설정하려면 mask 행렬을 자체적으로 생성(np.zeros_like(corr), np.triu_indices_from(mask) 등을 사용해서!) 후, mask에 넣어주면 된답니다!
💡 stats.pearsonr(x, y)
- 두 변수의 상관 계수와 유의 확률을 동시에 반환해주는 함수입니다.
- 반환 값은 요런 식! 'PearsonRResult(statistic=~, pvalue=6.773527303289964e-61)'
😃 인터렉티브 시각화
- plotly의 express 모듈은 파이썬 코드의 인터렉티브 시각화를 도와주는 역할을 해줍니다.
- plotly에서 만들어지는 차트는 기본적으로 html 파일로 생성되기 때문에 브라우저 상에서 보여져야 합니다.
- 그래서 write_html()를 통해 해당 차트들을 html로 생성한 뒤, webbrowser 모듈의 open_new() 함수를 사용하면 ! 해당 html을 브라우저로 볼 수 있게 됩니다.

☘️ 일과 삶의 균형 - (근로 조건이 삶에 어떤 영향을 미칠까)
- 어제 분석을 진행했었던 한국복지패널조사 데이터를 가지고 오늘은 자체적으로 주제와 하위 목표를 세워 분석을 진행해보았습니다.
- 저는 여러 근로 조건이 삶(건강, 근로 지속, 안정성)에 어떤 영향을 미칠까에 대한 내용을 주제로, 관련 다양한 하위 목표를 통해 변수들의 관계를 파악하고 시각화로 이들을 나타냈습니다.
🎯 하위 목표별 분석
💡 1. 근로시간 유형과 건강 상태의 관계
과연 장시간 근로자가 건강이 더 안 좋을까?
건강이 좋지 않은 사람들이 시간제 근로를 선택하는 경향이 있을까?

- 시간제 근로자(파트 타임)의 경우 건강 상태가 나쁠 확률이 전일제 근로자(풀타임)보다 높다는 것을 알 수 있었습니다. ('unhealthy'한 비율이 19.7% vs 5.7%)
- 전일제 근로자(풀타임)는 건강 상태가 상대적으로 양호하게 보입니다. ('healthy'의 비율이 78.5% vs 51.0%)
- 장시간 근로자가 반드시 건강이 나쁜 것은 아니지만, 건강이 좋지 않은 사람들이 시간제 근로를 선택하는 경향이 있습니다. 아마도 건강 문제로 인해서 풀타임 근무를 하기 어려운 경우가 많을 것으로 예상됩니다.
💡 2. 비경제활동 사유와 건강검진 횟수의 관계
경제 활동을 하지 않는 사람들이 건강 검진을 더 적게 받을까?

- 전반적으로 봤을 때, 애초에 비경제활동 집단에서 건강 검진 횟수가 낮은 편으로 나타났습니다.
- 특히 교육이나 취업을 준비하는 그룹이 건강 검진을 가장 적게 받았고,
- 건강 문제, 돌봄/가사 노동에 종사하는 사람들은 상대적으로 건강 검진을 더 자주 받는 것으로 보입니다.
- 결과적으로 경제 활동을 하지 않는다고 해서 반드시 건강 검진을 덜 받는 것은 아니라고 봅니다. 건강 상태와 생활 패턴에 따라 차이가 있다고 판단됩니다.
💡 3. 사업장 규모와 근로 지속 가능성의 관계
대기업일수록 근로에 대한 안정성이 높아질까?

- 예상대로 대기업일수록 근로 안정성이 높아지는 경향이 나타납니다.
- 소규모 사업장에서는 해고율과 구조 조정 가능성, 고용 불안정성 등이 증가한다고 보고,
- 대기업은 상대적으로 고용 보호가 강화되어 있어 근로 지속 가능성이 큰 편이라고 생각됩니다.
💡 4. 고용 관계와 근로계약기간 설정 여부의 관계
어떤 고용 방식에 정규직(무기계약)이 더 많을까?
계약 기간이 없는 근로자가 더 안정적인 고용 형태일까?

- 정규직(무기계약)의 비율은 직접고용 > 특수고용 > 간접고용 순서로 감소합니다.
- 간접고용은 대부분이 계약직 근로자(기간제)로, 정규직의 비율이 가장 낮은 것을 확인했습니다.
- 특수고용(프리랜서 등)은 무기계약 비율이 높지만, 법적 보호가 부족해서 고용 안정성을 보장하기 어려울 수도 있다고 봅니다.
- 고로, 직접고용이 가장 안정적인 고용 형태로 판단되며, 간접고용은 고용 불안정성이 가장 높다고 데이터가 말해주고 있었습니다.
💡 5. 경제활동 참여 상태와 의료 이용 횟수의 관계
경제활동 상태별로 의료기관 방문 횟수 차이가 있을까?
경제활동을 하지 않는 사람(비경제활동인구)이 의료기관을 더 자주 방문할까?
안정적인 직업과 불안정한 직업(임시직, 실업자 등) 간 의료 이용 패턴이 다를까?

- 비경제활동 상태일수록 의료 이용(외래진료 및 입원) 횟수가 많은 것을 볼 수 있습니다.
- 또한, 안정적인 경제활동(정규직) < 불안정한 경제활동 < 비경제활동 순으로 의료 기관의 방문 횟수가 증가하는 것을 확인할 수 있었습니다.
- 데이터를 보면 외래 진료가 많다고 반드시 입원이 증가하는 것은 아니지만, 외래 진료를 많이 받는 그룹이 입원 가능성도 조금 더 높다는 것을 볼 수 있었습니다.
✨ 최종적인 결론
- 근로 조건과 삶은 밀접한 관계가 있고, 다양한 근로 조건이 개인의 건강, 경제적 안정, 의료 이용 행태 등에 영향을 미치게 됩니다.
- 건강이 좋지 않은 사람들이 시간제 근로를 선택하는 경향이 있으며, 건강 상태가 근로 선택에 영향을 주는 방향성을 고려해볼 수도 있습니다.
- 대기업 근로자는 고용 안정성이 높은 반면, 소규모 사업장의 근로자는 해고 위험이 상대적으로 큽니다.
- 그래서 고용 안정성을 높이기 위한 정책적인 지원이 필요합니다.
- 간접 고용은 정규직의 비율이 낮고 고용 안정성이 가장 낮은 형태를 띠기 때문에,
- 고용 보호나 안정성을 강화하는 제도적인 장치가 필요한 것으로 나타납니다.
- 의료 이용 패턴을 고려할 때, 불안정한 고용 형태를 가진 근로자와 비경제활동인구가 의료 서비스를 충분히 받을 수 있도록 정책적인 배려가 필요하다고 봅니다.
- 일반적으로 안정적인 고용 형태와 적절한 근로 시간은 건강과 삶의 질을 향상시키는 요인이 되어주지만, 불안정한 고용 상태나 열악한 근로 환경은 건강 악화 및 의료 이용 증가와 연관성이 높은 것을 확인할 수 있었습니다.
🤔 13일차 회고
- 오늘은 기초적인 통계 지식들(가설 검정 등)을 배우고, 개인 미니 프로젝트를 진행해보았습니다.
- 우선 가설 검정을 파이썬 코드로 작성해본 것은 처음이었고, scipy 모듈을 쓰기보다는 R 언어를 통한 가설 검정을 했었는데 '이제 파이썬으로도 충분히 이런 가설 검정들을 할 수 있구나'를 경험한 오늘이네요.
- 오후에는 쭉 프로젝트를 진행했는데, 저는 데이터 공모전에 출전할 때에도 항상 오래 걸렸던 작업이 주제 선정이었던 것 같습니다.
- 오늘도 마찬가지로 주제 선정하는 데에 시간을 조금 썼는데, 앞으로 교육을 들으며 최대한 많은 인사이트를 얻고, 그에 따른 주제 선정도 조금 더 폭 넓게 되었으면 하는 바람입니다.
- 그리고 시각화한 그래프들을 보면, 대부분이 비슷한 막대 그래프나 boxplot만이 나타나고 있습니다.
- 하위 목표를 범주형 변수들로만 구성해놔서 이런 불상사(?)가 발생했는데, 다음에 목표 설정할 때에는 연속형 변수들도 많이 포함시켜놔야겠습니다.
- 내일은 다른 데이터를 가지고 또다른 분석 프로젝트를 진행해 볼 예정입니다!
728x90
LIST
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 Selenium은 어디까지 크롤링할 수 있을까? (0) | 2025.02.18 |
|---|---|
| 🤔 심부전 데이터와 BeautifulSoup (6) | 2025.02.17 |
| 🤔 Iterator와 Generator 그리고 한국인의 삶 (2) | 2025.02.12 |
| 🤔 Python 이론 살짝 업글해보기 (4) | 2025.02.11 |
| 🤔 Numpy와 Seaborn 그리고 또다시...각화 (0) | 2025.02.07 |