
728x90
SMALL
- 각 사람마다 MBTI로 표현되는 성향이 존재하듯이, 데이터에도 각자의 성격이 있습니다.
- 어떤 데이터는 계산이 가능하기도 하지만, 그저 구분만 가능한 데이터들도 있습니다. 이렇게 데이터의 성격을 구분하는 기준이 바로 '변수와 척도'입니다.
변수는 무엇인가요?
- 모든 데이터는 변수라는 이름 아래, 서로 다른 특징과 역할을 가지고 있습니다. 변수는 이처럼 데이터의 기본 단위 역할을 해줍니다.
- 데이터 과학과 데이터 분석은 이 변수와 변수 간의 관계를 밝혀내는 활동이라고 할 수 있습니다.
- 보통 연산을 하는 것이 의미가 있는지 없는지에 따라 양적 변수와 질적 변수로 구분이 됩니다.
- 여기서 양적 변수는 정숫값만 취할 수 있는 이산 변수와 연속적인 모든 실숫값을 취할 수 있는 연속 변수로 나뉩니다.
- 그리고 질적 변수는 속성을 숫자로 변환하더라도 수치적인 의미를 가지고 있지는 않습니다.
- 변수의 관계적인 측면에서 보면, 독립 변수와 종속 변수가 관계의 핵심이라고 할 수 있습니다. 이 둘은 원인과 결과의 인과 관계입니다.
- 특히 패턴 인식이나 ML 분야에서는 독립 변수를 Feature라고 부릅니다.
- 그리고 독립 변수와 종속 변수는 기본적으로 상관 관계를 가지고 있습니다.
- 마지막으로 통제 변수는 실험이나 설문 조사를 할 때 종속 변수에 영향을 줄 수 있는 외부 요소를 통제하기 위해서 사용되는 변수입니다. (고등학교 생물 시간에 배웠던 것 같습니다...)
변수끼리는 어떤 관계를 가지나요?
인과 관계
- 앞서 말했듯이 독립 변수와 종속 변수의 기본적인 관계를 의미합니다.
- 말 그대로 변수가 다른 변수의 원인이 되는 영향을 미치는 관계입니다.
상관 관계
- 변수 간에 관련성이 존재하는 관계입니다. 인과 관계보다 상위 개념으로 볼 수도 있습니다.
독립 관계
- 추후에 언급될 상관 계수가 0인 관계입니다.
- 독립 변수의 이름에 '독립'이라는 단어가 포함된 것도, 원칙적으로 독립 변수들 간에는 상관성이 없는 독립 관계이기 때문입니다.
의사 관계
- 변수 간에 상관성은 존재하지만, 그 상관성이 다른 변수 때문에 나타나는 관계입니다.
- 예를 들면, 일별 아이스크림 판매량과 익사 사고 발생 수에 높은 상관 관계가 나타났을 때, 이 관계의 원인은 '기온'이라는 제3의 변수와의 관계 때문이라고 볼 수 있습니다.
양방향적 인과 관계
- 두 변수가 서로 간에 인과적인 영향을 미치는 관계입니다.
- 초기 투자가 매출액 증가의 원인이 될 수 있고, 매출액 증가가 재투자의 원인이 될 수 있는, 그렇고 그런 관계입니다.
조절 관계
- 독립 변수와 종속 변수 사이의 관계가 상황(조절 변수)에 따라 달라지는 경우를 의미합니다.
- 예를 들어 햇볕(독립 변수)이 식물의 성장(종속 변수)에 영향을 준다고 할 때, 토양의 종류(조절 변수)에 따라 햇볕의 효과가 달라지는 경우라고 보시면 됩니다.
- 같은 햇볕이라도 좋은 흙에서는 잘 자라고, 척박한 흙에서는 덜 자라는 !
매개 관계
- 중간에 매개 변수가 개입되어 독립 변수의 영향을 종속 변수에게 전달하는 관계입니다.
- '학력이 소득에 영향을 주긴 하지만, 그 영향은 결국 나중에 직업을 통해 전달된다'는 구조와 같은 것입니다.
- '학력 → 직업 → 소득'과 같은 시간적인 차원이 이 관계에 포함될 수도 있습니다.
- 정리해보자면, 조절 변수는 독립 변수와 종속 변수 간 관계의 강도를 조절해주는 역할을 하고, 매개 변수는 독립 변수의 영향을 종속 변수로 전달해주는 역할을 해줍니다.

그럼 척도는 무엇인가요?
- 변수로 데이터의 성격을 알아봤다면, 그 성격을 어떻게 측정할지를 정해야 합니다.
- 데이터의 특성을 표현하는 방법도 여러 가지인데, 이를 구분해주는 것이 바로 척도입니다.
- 변수가 질적인가 양적인가에 따라 질적 척도(범주형 척도)와 양적 척도(연속형 척도)로 분류가 됩니다.
- 질적 척도는 속성 값을 범주로 나타내는지 순위로 나타내는지에 따라 다시 명목 척도와 서열 척도로 분류됩니다.
- 그리고 양적 척도는 절대적 기준인 영점이 존재하는지에 따라 등간 척도와 비율 척도로 나뉘게 됩니다.
- 명목 → 서열 → 등간 → 비율 척도는 뒤로 갈수록 포함하고 있는 정보의 양이 점점 많아집니다.
명목 척도
- 다른 척도들보다 정보량이 가장 적고, 숫자로 변환한다 해도 순서나 크기에 의미가 없습니다.
- 예를 들면 운동 선수의 등 번호라든지 혈액형 등이 이에 속합니다.
서열 척도
- 서열 척도는 말 그대로 서열 ! 한 학급의 성적 1등과 2등은 순서에 대한 정보는 가지고 있지만, 구체적인 점수 차이에 대한 정보는 가지고 있지 않습니다.
등간 척도
- 상대적 크기의 차이를 비교할 수 있는 정보도 함께 가지고 있습니다.
- 대신 곱하기나 나누기를 할 수는 없습니다. 쉽게 말해서 영상 20도가 영상 10도의 두 배라고 할 수 없습니다.
비율 척도
- 절대 기준인 0kg가 존재하기 때문에, 100kg이 50kg의 두 배라고 할 수 있습니다. 이처럼 비율 척도는 가감승제가 모두 가능합니다.
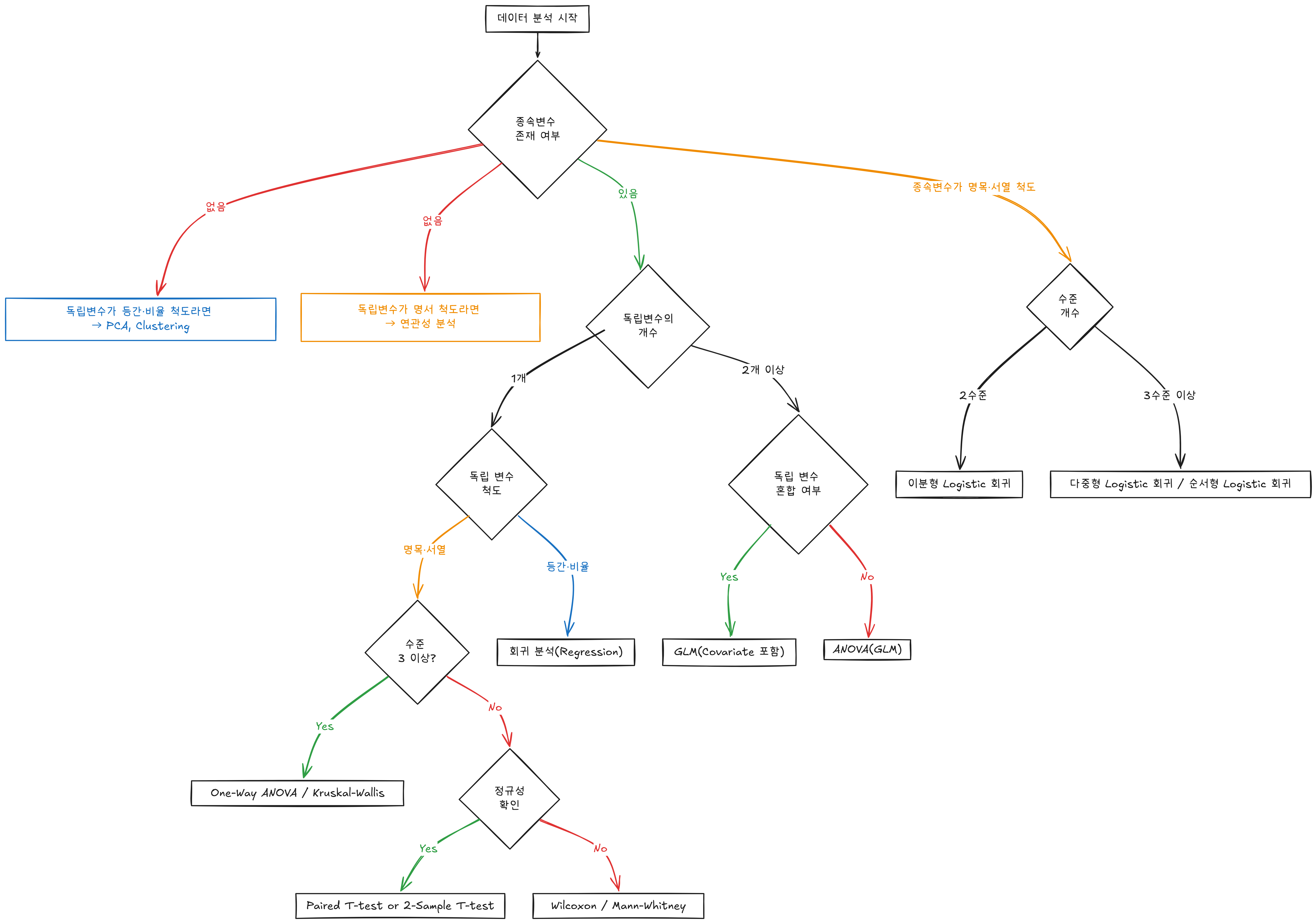
- 독립 변수와 종속 변수의 개수, 척도의 종류에 따라서 사용할 수 있는 검정이나 분석 기법이 달라집니다.
- 위 다이어그램이 변수의 척도와 관계에 따라 어떤 분석 방법을 선택해야 하는지 나타내고 있는데, 일단은 참고만 해두면 좋을 것 같습니다 ! (작아서 보이지도 않네)
참고 도서
- 『데이터 분석가가 반드시 알아야 할 모든 것』, 저자 황세웅, 위키북스
728x90
LIST
'데이터 분석 > 이론' 카테고리의 다른 글
| 데이터는 우연 속에서 패턴을 찾는다 (0) | 2025.12.03 |
|---|---|
| 데이터는 우연을 계산한다 (0) | 2025.10.21 |
| 평균은 시작일 뿐이다 (0) | 2025.10.20 |
| 고양이 100마리로 서울의 모든 고양이 수를 알 수 있을까? 🐈 (0) | 2025.10.15 |
| 데이터를 다룬다면 통계학은 선택이 아니라 '기본'이다 (2) | 2025.10.14 |