
728x90
SMALL
- 우리가 데이터를 분석할 때, 전체 데이터를 확인하는 것이 가장 정확하고, 좋다고 여기는 경향이 있습니다. 하지만 세상 모든 데이터를 확인하고 모으는 건 거의 불가능이라고 생각합니다.
- 그래서 통계학은 이 문제를 '부분으로 전체를 추정하는' 표본 조사라는 방식으로 풀어줍니다. 이전 글에서도 언급했듯 통계학의 핵심은 표본에서 모집단으로 가는 과정입니다.
표본 조사는 왜, 어떻게 하나요?
- 최종 데이터 분석에는 전체 데이터를 사용하더라도, 분석 모델이 완성될 때까지는 표본 데이터를 활용하는 것이 경제적으로, 시간적으로 훨씬 유리합니다.
- 일반적으로 최소 200개 이상의 표본이 확보되면 분석이 가능하다고 합니다. 하지만 변수의 개수나 표본 분산에 따라서 더 많은 표본이 필요할 수도 있습니다. 통계적으로 변수 하나당 최소 30개의 관측치가 필요합니다.
- 데이터 가공과 변환이 수없이 일어나는 예측 및 분류 모델링 단계에서는 적절한 표본을 추출해서 진행하고, 전체 프로세스가 완성되었을 때 전체 데이터를 사용해서 최종적인 모델 성능을 확인한 뒤 예측 및 분류를 하는 것이 좋습니다.
- 그럼 제목에 나와있듯 서울시 길고양이가 총 몇 마리인지 알아내기 위해 사용하는 표본 조사 방법인 표지 재포획법에 대해서 정의보다는 예시로 더 이해하기 쉽게 설명해보겠습니다.
표지 재포획법은 뭔가요?
- 조사 순서는 다음과 같습니다.
- 서울시 길고양이 중 예를 들어 100마리를 먼저 포획합니다. (실제로는 더 많이 포획해야 할 것 같습니다. 서울시가 워낙 넓으니...)
- 그리고 포획했던 100마리를 알아볼 수 있는 표식(표지)을 남기고 다시 길에 풀어줍니다.
- 그리고 며칠 정도 시간이 지나고, 다시 무작위로 길고양이 100마리를 포획합니다. 그렇게 되면 일부는 저번에 남겼던 표식이 있을 겁니다.
- 이렇게 표식이 있는 길고양이의 비율을 통해 서울시의 길고양이 모집단 수를 추정할 수 있습니다.
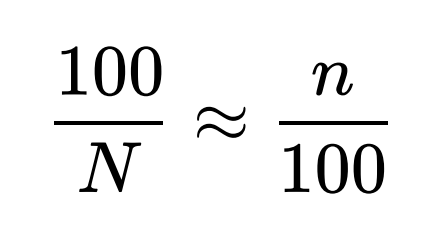
- 왼쪽 분수는 전체 모집단 N마리 중에서 처음 포획해 표식을 남겼던 100마리 길고양이를 뜻하고, 오른쪽은 두 번째로 포획했던 100마리 길고양이 중에서 표식이 남아있는 n마리의 길고양이를 뜻합니다.
- 그래서 만약 두 번째 포획했을 때 표식이 남아있는 고양이가 10마리라고 한다면 서울시 길고양이는 1000마리라고 추정할 수 있는 것입니다.
- 이런 분석처럼 표지 재포획법은 서식지에 사는 생물들의 군집 밀도를 파악하거나, 유동 인구를 추정할 때 사용하는 기법입니다.
편향은 뭔가요?
- 모집단과 표본의 자연적(우연)으로 발생하는 변동(차이)을 표본 오차라고 합니다. 같은 모집단에서 표본을 여러 번 뽑게 되면, 매번 조금씩 다른 결과가 나오게 됩니다. 이것은 뽑는 사람의 실수(?)가 아니라 표본이 무작위로 선택되었기 때문입니다.
- 이렇게 표본을 달리했기 때문에 자연스럽게 생기는 차이를 표본 오차라고 합니다.
- 그리고 이 표본 오차를 제외한 변동(차이)을 비표본 오차라고 합니다. 여기 이 비표본 오차의 한 원인이 바로 편향입니다. 다시 말해, 편향은 표본에서 나타나는 모집단과의 체계적인 차이입니다. 즉, 무작위가 아니라 일정한 방향으로 왜곡된 차이를 말합니다.
- 예를 들어, 평일 중 낮에 설문을 하게 되면 직장인은 대부분 못할 가능성이 크고, 이외 사람들 위주로 표본이 구성되게 됩니다. 그래서 조사 방식 자체가 특정 집단에 유불리하게 작용할 수 있게 됩니다.

하나만 있진 않을 것 같은데, 또 어떤 종류의 편향이 있나요?
- 표본 추출 편향
- 표본을 추출하는 과정에서 체계적인 경향이 개입되어 모집단에서 편향된 표본만 추출되는 경우입니다.
- 미국에서 루즈벨트 전 대통령이 출마했을 당시, 전화번호부 주소를 이용해서 여론 조사를 시행했는데, 당시에는 전화 보급이 완전히 이루어지지 않아서 표본이 부유한 가정 위주로 이뤄지게 되었다고 합니다.
- 가구 편향
- 모집단의 부분 집단 단위에서 하나의 관측치씩 추출할 때, 작고 많은 집단보다, 크고 적은 집단이 적게 추출되는 경우를 뜻합니다.
- 각 가구의 집 전화(요즘엔 잘 이뤄지지 않겠지만)로 여론 조사를 하게 될 경우, 가족 구성원이 적은 가정보다 가족 구성원이 많은 가정이 추출된 확률이 줄게 되는 경우를 예로 들 수 있습니다.
- 무응답 편향
- 설문에 응답하지 않는 사람들과 응답하는 사람들 간에 체계적인 차이가 있는 경우 나타나는 편향입니다.
- 지지하는 정당 관련한 설문을 할 경우, 시간이 있어서 응답하는 사람과 그냥 끊어버리는 사람들 간 지지 정당의 차이가 있게 되면 표본에 편향이 발생하게 됩니다.
- 응답 편향
- 응답자의 심리적인 이슈에 의해 표본이 영향을 받는 경우에 나타납니다.
- 출구 조사에서 설문자가 사회적 시선이나 여론 분위기 때문에 조사원들의 답변에 일부러 거짓을 얘기해 편향이 발생하게 되는데, 이를 브래들리 효과라고도 합니다.
- 이러한 표본 편향들은 데이터를 수집하는 과정에서 생기게 되는데, 확률화 등의 방법을 통해 최소화하거나 제거할 수 있습니다.
- 여기서 확률화는 표본이 특정 조건이나 사람의 의도대로 선택되지 않고, 무작위로 선택되도록 하는 과정을 의미합니다.
수집 말고 데이터를 해석할 때에도 편향이 생길 수 있나요?
- 데이터를 수집한 이후에도 편향이 생길 수 있습니다. 보통 분석을 담당해야 하는 데이터 분석가에게 생기는 편향이라고 할 수 있는 이 인지적 편향은 많이들 들어봤을 법한 편향들이 포함됩니다.
- 확증 편향
- 자신이 원래 믿고 있는대로 정보를 선택적으로 받아들이고 임의로 판단하는 편향입니다.
- 처음부터 생각했던 가설에 유리한 방향으로 정보를 수집하고 해석하는 것은 명백한 오류이고, 분석의 신뢰성을 떨어뜨립니다.
- 그래서 이 편향을 방지하기 위해 두 명 이상의 분석가가 크로스 체크하거나, 블라인드 분석을 수행하기도 합니다.
- 기준점 편향
- 가장 처음 접하는 정보에 지나치게 매몰되는 편향입니다.
- 예를 들어 연봉 협상을 할 때, 처음으로 제안받는 금액이 협상의 기준점으로 자리잡아, 그 범위 내에서 연봉을 협상하게 하는 상황이 있습니다.
- 선택 지원 편향
- 본인이 의사결정하는 순간, 그 선택의 긍정적인 부분에 대해 더 많이 생각하고, 그 결정에 반대되는 증거를 무시하게 되는 편향입니다.
- 주어진 정보들을 통해 의사결정이 이루어진 순간부터 편향성을 띠게 됩니다.
- 분모 편향
- 분수 전체가 아닌 분자에만 집중해 현황을 왜곡하고 판단하게 되는 편향입니다.
- 생존자 편향
- 소수 성공 사례를 일반화된 것으로 인식함으로써 나타나는 편향입니다.
- 취업하는 이들이 가진 스펙(고학점, 어학 성적, 인턴 경험, 수상 경력 등)만이 성공의 유일한 길인 것처럼 비춰질 수 있지만, 비슷한 스펙을 가졌음에도 불구하고 탈락하는 수많은 지원자들의 존재는 쉽게 잊혀지게 됩니다.
- 이로 인해 취준생들은 자신에게 부족한 스펙을 채우는 데에만 매몰되어, 정작 중요한 직무 역량이나 자신만의 강점을 발견하고 발전시킬 기회를 놓칠 수도 있게 됩니다.

머신러닝에서도 편향이라는 단어가 자주 쓰이는데, 이것도 비슷한가요?
- 통계적 의미와는 다르게 머신러닝에서는 예측값들이 정답과 일정하게 차이가 나는 정도를 편향이라고 합니다.
- 그리고 이와 관련해서 분산은 주어진 데이터 포인트(예를 들어 평균)에 대한 모델 예측의 가변성을 의미합니다. 즉, 같은 문제를 다른 데이터로 학습시켰을 때, 예측이 얼마나 달라지는가를 보는 값입니다.
- 주어진 학습 데이터에 잘 맞도록 모델을 만들수록 편향은 줄어들고, 분산은 증가할 수 밖에 없습니다.
- 분산이 적지만, 편향이 큰 경우는 정답 값을 제대로 설명할 수 있는 변수가 부족한 상태라고 볼 수 있습니다. 그렇기에 표본 추출 방법을 바꾸거나 새로운 변수를 탐색하거나, 고도화된 데이터 가공 방식을 적용해야 합니다.
표본 편향을 최소화하려면 어떤 방법을 써야 하나요?
- 표본 추출을 두 가지 관점에서 바라볼 수 있습니다. 첫 번째는 데이터 수집 단계의 표본 추출이고,
- 두 번째로는 기업에서 이미 가지고 있는 몇 천만 건의 고객 정보 데이터, IT 기업의 웹 로그 데이터 등과 같은 빅데이터 분석 모델링을 위한 적절한 크기의 표본 데이터를 추출하는 것입니다.
- 첫 번째인 데이터 수집 단계에서의 표본 추출은 다음과 같이 진행됩니다.
- 먼저 모집단을 확정시킵니다. 조사 대상이 되는 사람, 사물, 조직, 지역 등의 전체 집합을 구체적으로 정의합니다.
- 모집단에 포함되는 조사 대상의 목록(표본의 프레임)을 설정해줍니다.
- 구체적인 표본 추출 방법을 결정합니다. 확률∙비확률 표본 추출, 복원∙비복원 추출 중에서 적절한 방법을 선택합니다.
- 조사의 유형, 시간, 예산 등을 고려해서 추출할 표본의 크기를 결정합니다.
- 선정된 조사 대상들(표본)을 추출합니다.
- 두 번째 관점에서의 표본 추출(이미 보유하고 있는 빅데이터에서 표본 추출)은 다음과 같이 진행됩니다.
- 이미 모집단과 조사 대상의 목록은 결정되어 있기 때문에 넘어갑니다.
- 모집단이 분석 목적에 맞게 세팅이 되어 있는지 확인합니다.
- 구체적인 표본 추출 방법을 결정합니다. (위와 동일) 대신 이 관점에서는 거의 대부분 확률 표본 추출을 사용합니다. 모든 분석 대상이 무작위로 추출될 확률을 미리 알 수 있을 때 사용되고, 편향을 최대한 제거할 수 있어 표본의 신뢰도가 높습니다.
- 4번과
- 5번은 위와 동일하게 진행합니다.
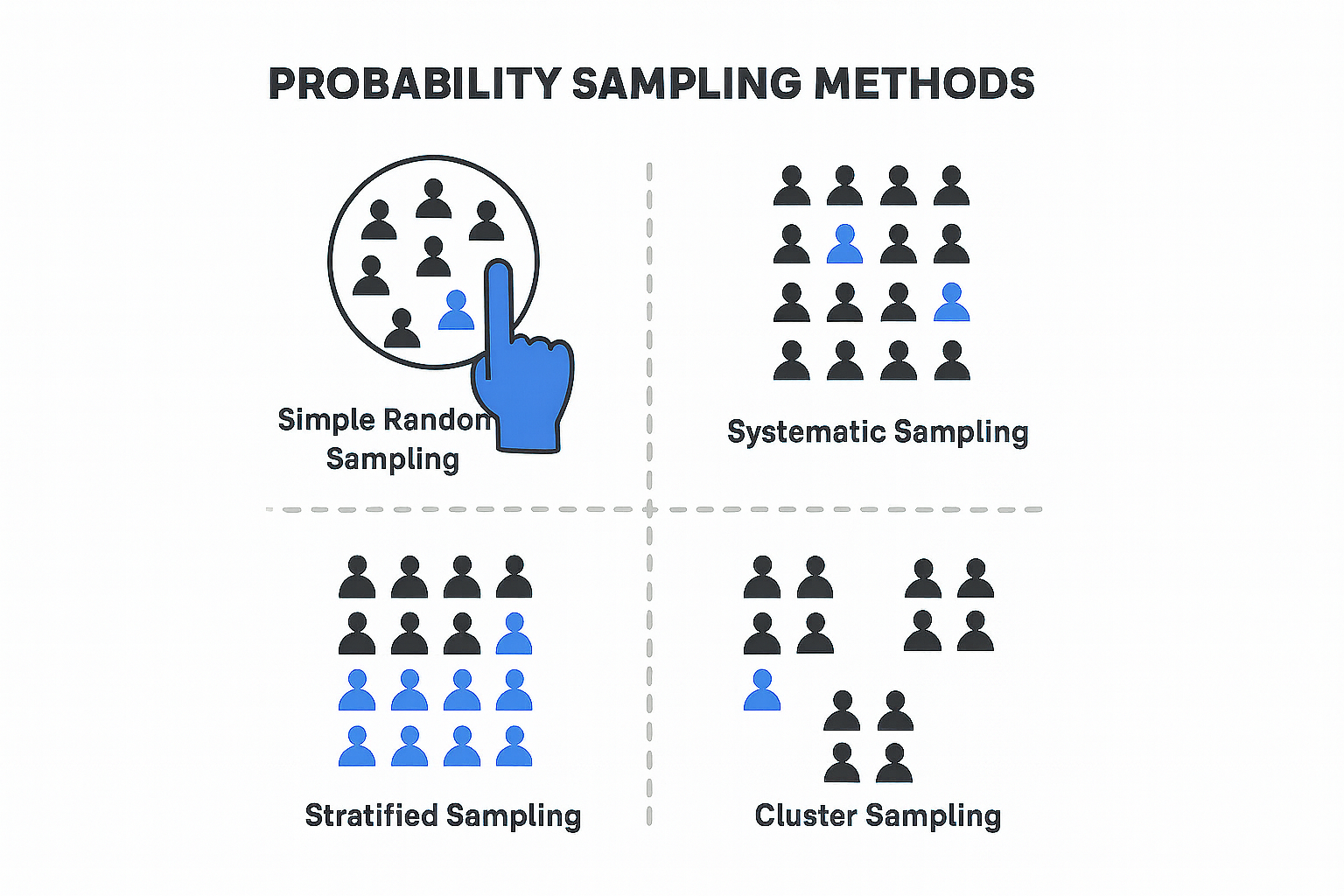
그럼 확률 표본 추출 방법에는 어떤 것들이 있나요?
- 제비뽑기나 로또 당첨 번호를 선정하듯이 하는 단순 임의 추출 방법이 있습니다. 모집단에 대한 사전 지식이 없는 경우에 유용하게 사용됩니다.
- 모든 구성 단위에 일련번호를 부여한 뒤에 일정 간격으로 표본을 선택하는 계층적 표본 추출 방법이 있습니다.
- 모집단이 특정한 기준으로 분류가 가능할 때 쓰이는 층화 표본 추출 방법이 있습니다. 표본이 편중될 수 있는 위험을 보완해줍니다.
- 층화 표본 추출처럼 모집단을 특정 기준으로 분류한 뒤, 그 중 하나의 소집단을 선택해 분석하는 군집 표본 추출 방법이 있습니다. 모집단이 방대한 상황에서 표본 추출이 쉽지 않을 때 유용하게 사용됩니다. 대신 모수를 반영하지 못할 수도 있습니다.
- 이런 확률 표본 추출 방법들은 각 상황에 맞게 활용되는데, 표본을 실제로 추출할 때는 복원∙비복원 추출 중 어떤 방식을 택할지도 함께 고려해줘야 합니다.
- 모집단의 크기가 별로 크지 않거나 추출하는 표본이 20% 이상으로 많은 경우에는 복원 추출 방식이 편향을 더 줄일 수 있습니다.
참고 도서
- 『데이터 분석가가 반드시 알아야 할 모든 것』, 저자 황세웅, 위키북스
728x90
LIST
'데이터 분석 > 이론' 카테고리의 다른 글
| 데이터는 우연 속에서 패턴을 찾는다 (0) | 2025.12.03 |
|---|---|
| 데이터는 우연을 계산한다 (0) | 2025.10.21 |
| 평균은 시작일 뿐이다 (0) | 2025.10.20 |
| 데이터한테도 MBTI가 있다...? (0) | 2025.10.16 |
| 데이터를 다룬다면 통계학은 선택이 아니라 '기본'이다 (2) | 2025.10.14 |