
728x90
SMALL

- 오늘은 타이타닉 생존자 데이터를 가지고 의사결정트리, 로지스틱 회귀 분석을 진행해보았고, 후에 통계 지식들을 차례차례 배워보았습니다.
🚢 타이타닉 생존자 예측해보기
✨ 데이터를 불러오고 사전 작업해주자
- 먼저, 원본 타이타닉 데이터를 불러온 후, 분석에 필요한 컬럼만 추출했습니다.
- 'ticket', 'cabin', 'embarked' 등 분석과 무관한 컬럼을 제외시켰고, 가독성과 유지 보수를 위해서 모든 컬럼을 소문자로 통일시켰습니다.
new_columns = ['passengerId', 'survived', 'pclass', 'name',
'sex', 'age', 'sibsp', 'parch', 'ticket',
'fare', 'cabin', 'embarked']
df.columns = new_columns
df1 = df[['survived', 'pclass', 'name', 'sex',
'age', 'sibsp', 'parch', 'fare']]
✨ 범주형 변수랑 파생 변수 잘 만들어주자
💡 성별 컬럼 처리
- 여성은 0, 남성은 1로 변환해서 수치형으로 표현했고,
💡 호칭(title) 컬럼 추출 및 처리
- 이름(name)에서 호칭을 추출해 특수 호칭(Master, Don, Rev)을 Special로 분류해
- 이진 변수로 변환하고 special_title 컬럼을 따로 생성해봤습니다.
💡 가족 수 및 평균 요금 계산하기
- 마지막으로 sibsp(형제자매/배우자 수) + parch(부모/자녀 수)를 합쳐서 sibpar 컬럼을 생성한 뒤에
- 본인을 포함한 n_family 변수로 바꿔주고, 요금을 인원 수로 나눈 avgfare를 계산 후 이 값을 개인당 평균 요금으로 변환해 추가 컬럼으로 생성했습니다.
✨ 학습하기 전에 데이터를 나눠보자
- 전처리한 데이터를 기준으로 학습용과 테스트용 데이터셋으로 분리해주는 작업은 필수죠!
train = np_raw[:100] # 학습용으로 우선 100개만
X_train = [j[1:] for j in train]
y_train = [i[0] for i in train]
✨ 의사결정나무(Decision Tree)로 모델링하기
DecisionTreeClassifier(criterion='entropy', max_depth=3, min_samples_leaf=5)- 의사결정나무는 위와 같이 설정해주었고, 각 파라미터의 의미를 한 번 살펴보겠습니다.
- criterion은 entropy를 기준으로 분할한다는 뜻이고,
- max_depth를 설정한 것은 과적합 방지를 위해서 트리 깊이를 3으로 제한한다는 뜻입니다.
- 마지막으로 min_samples_leaf은 최소 샘플 수의 조건을 5로 설정한다는 것입니다.
💡 모델 학습 및 정확도 평가
- 모델 훈련 후에는 score()를 통해 학습/테스트 정확도를 확인해주었고,
- Graphviz를 통해 트리 구조를 PNG 파일로 저장해서 트리의 구조를 직관적으로 확인할 수 있었습니다.
✨ 혼동 행렬(Confusion Matrix)은?
- 예측 결과를 혼동 행렬로 나타내서 정확한 분류 결과를 확인하는 작업을 거쳤는데,
- 행렬은 [[18, 1], [2, 5]]과 같이 나타나, 정확도 85%를 보였습니다.
- 좌측 상단 값은 TP(True Positive)로, 생존자 중 생존이라고 예측한 값,
- 우측 하단 값은 TN(True Negative)으로 사망자 중 사망이라고 예측한 값,
- 우측 상단 값은 FP(False Positive)로 사망자 중 생존이라고 잘못 예측한 값,
- 마지막으로 좌측 하단 값은 FN(False Negative)로 생존자 중 사망이라고 잘못 예측한 값을 의미합니다.
✨ 이번엔 로지스틱 회귀 분석!
- 이진 분류 문제에서 널리 쓰이는 로지스틱 회귀 모델도 함께 적용해보았습니다.
💡 비표준화된 데이터 사용
- LogisticRegression(C=10., solver='liblinear')으로 모델을 생성하고 학습시켰더니 테스트 정확도가 약 85%가 나왔습니다.
- 여기서 C에는 정규화 강도(10은 약한 정규화)를 의미하고, solver는 최적화에서 사용할 알고리즘을 지정해줍니다.
💡 그럼 표준화된 데이터 사용할 때는? (MinMaxScaler, StandardScaler)
- 표준화라는 것은 특성의 단위 차이를 제거하고 모델의 성능을 안정화시키는 역할을 해줍니다.
scaler = StandardScaler()
X_ss = scaler.fit_transform(X)
- 위와 같이 MinMax와 Standard 모두 사용해보았는데, 결과적으로 표준화 후 성능이 소폭 개선되거나 모델의 해석력이 향상됨을 확인할 수 있었습니다.
💡 회귀 계수를 해석해보자
- 로지스틱 회귀에서의 회귀 계수는 각 특성의 영향력을 보여주는데,
- 양수로 나타나는 계수는 해당 특성(컬럼)이 생존 확률을 높인다는 뜻이고,
- 음수로 나타나게 되면, 해당 특성(컬럼)이 생존 확률을 낮춘다는 뜻입니다.
🪵 통계를 쉽게 이해해보자!
- 통계 용어를 공부하다 보면 여러 용어들이 한꺼번에 등장해서 헷갈릴 때가 많은 것 같습니다.
✨ 벡터 연산에는 내적을 주로 사용한다!
- 먼저, 내적은 두 벡터의 각 원소를 곱한 뒤 모두 더해서 하나의 숫자로 만드는 연산입니다.
- 이 숫자는 두 벡터가 얼마나 같은 방향을 바라보고 있는지를 나타내줍니다.
- 예를 들어, 두 친구가 같은 방향을 바라본다면 서로 생각이 맞는 것처럼 큰 양수로 나타나고, 반대 방향을 바라본다면 큰 음수로 나타나게 됩니다.
- 만약 두 벡터가 90도처럼 서로 직각이라면, 서로 영향을 주지 않는 독립적인 관계로 0이 나오게 됩니다.
✨ 데이터 산포를 나타낼 때는 분산과 표준편차
- 데이터가 얼마나 흩어져 있는지, 즉 평균에서 얼마나 떨어져 있는지를 알아보려면 분산과 표준편차를 사용합니다.
- 분산은 각 데이터가 평균에서 떨어진 정도를 제곱한 후 평균을 내어 구하는데, 값이 크다면 데이터가 평균에서 멀리 흩어져 있다는 뜻이고, 작다면 평균 주변에 몰려 있다는 뜻입니다.
- 표준편차는 분산의 제곱근을 구한 것으로, 원래 데이터와 같은 단위로 흩어짐 정도를 나타내주기 때문에 직관적으로 이해하기 쉬울 수 있습니다.
- 또한, 모든 데이터를 사용할 수 있는 경우와 일부 표본만 사용할 때의 차이를 이해하는 것도 중요합니다.
- 모분산은 전체 집단의 데이터를 사용해 계산하고,
- 표본 분산은 전체 데이터 중 일부를 뽑아서 계산하는데, 이때는 약간의 보정을 위해 분모를 n이 아니라 n-1로 나눠서 사용하게 됩니다.
✨ 변수 간 관계를 살펴볼 때는 공분산과 상관계수
- 두 변수 사이에 어떤 관계가 있는지 알고 싶다면 공분산과 상관계수를 보면 좋습니다.
- 공분산은 두 변수의 값들이 평균으로부터 얼마나 함께 떨어지는지를 계산해 줍니다. 두 변수가 같이 증가하면 양의 값을, 한 변수가 증가할 때 다른 변수가 감소하면 음의 값을 나타내게 됩니다.
- 상관계수는 공분산을 각 변수의 표준편차로 나누어 -1부터 +1 사이의 값으로 정규화한 결과로,
- 이 값이 1에 가까우면 강한 양의 선형 관계, -1에 가까우면 강한 음의 선형 관계, 0에 가까우면 서로 큰 관련이 없다고 볼 수 있습니다.
✨ 선형 회귀 분석에서의 최소자승법(OLS)
- 선형 회귀에서는 최소자승법을 통해 데이터와 가장 잘 맞는 직선을 찾게 됩니다.
- 최소자승법은 각 데이터 점과 직선 사이의 차이를 제곱해서 모두 더한 값(SSE)을 최소화하는 방향으로 회귀선을 결정합니다.
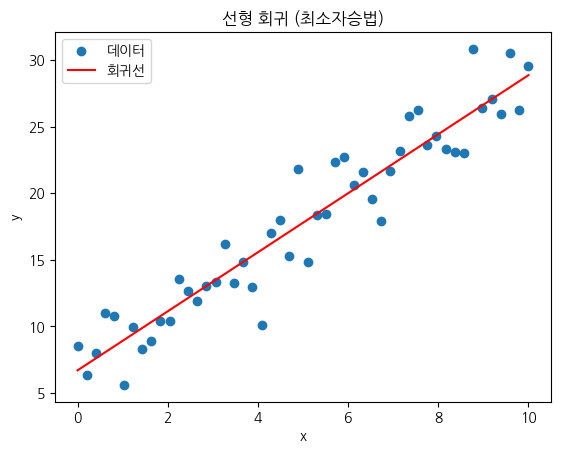
- 이때 회귀 계수는 독립변수가 한 단위 증가할 때 종속변수가 평균적으로 얼마나 변화하는지를 알려주는 지표입니다.
- 선형 회귀에서는 모델의 성능을 평가하는 것도 중요한데, 그 평가 요소 중 SST(총 제곱합)은 전체 데이터가 평균에서 얼마나 떨어져 있는지를 나타내는 값입니다.
- SSE와 SST, 이 두 값을 이용해 계산하는 결정계수(R Squared)는 모델이 전체 변동성 중 얼마나 설명하고 있는지를 0과 1 사이의 값으로 나타내 주어, 1에 가까울수록 좋은 모델이라고 할 수 있습니다.
🤔 42일차 회고
- 어제까지 1차 프로젝트를 진행하고, 오늘 다시 교육으로 넘어왔습니다.
- 저희는 도로 결빙과 관련해 공모전까지 준비하고 있는 터라 시간이 그리 넉넉치는 않았지만, 1차 결과물로써는 나름 구체적으로 작성되었고, 준비도 많이 된 것 같아 뿌듯했습니다.
- 오늘은 간만에 실습을 따라가며 여러 ML 알고리즘들과 관련 지식들을 배웠는데,
- 앞으로 데이터 분석을 하면서도 나름 자주 사용될 로지스틱에 대한 자세한 내용과 여러 평가 지표들을 충분히 익힌 것 같습니다.
- 저희의 1차 프로젝트는 여기서 확인하실 수 있습니다!
GitHub - whynotsw-camp/wh05-1st-teamS-JungSung: LG 유플러스 Why Not SW Camp 5기 S(정성)팀 1차 프로젝트입니다.
LG 유플러스 Why Not SW Camp 5기 S(정성)팀 1차 프로젝트입니다. Contribute to whynotsw-camp/wh05-1st-teamS-JungSung development by creating an account on GitHub.
github.com
728x90
LIST
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 Flask에 스타일 입혀주기 (1) | 2025.04.01 |
|---|---|
| 🤔 이게 Flask였던가... (0) | 2025.03.31 |
| 🤔 요즘 어떤 강의가 가장 핫해...? (1) | 2025.03.19 |
| 🤔 RNN과 LSTM 그리고 BiLSTM (6) | 2025.03.18 |
| 🤔 형태가 바뀌면 의미도 바뀔까? (0) | 2025.03.17 |