
728x90
SMALL

- 오늘은 비지도학습인 클러스터링을 통해 인프런 댓글 데이터를 분석해보며, 여러 기법들을 탐색해보는 시간을 가졌습니다.
🙂↕️ 인프런 댓글 군집화로 고객의 관심사 파악해보기!
- 온라인 쇼핑몰이나 이벤트에 달린 수백, 수천 개의 댓글을 일일이 읽기란 현실적으로 어렵습니다.
- 대신 군집화(클러스터링) 기법을 사용하면, 비슷한 댓글들을 그룹으로 묶어서 고객들이 어떤 주제에 관심이 있는지 쉽게 파악할 수 있습니다.
- 그래서 이번에는 인프런 댓글 데이터를 전처리하고, 단어 빈도 기반의 BoW와 TF-IDF를 적용한 후에
- KMeans 및 MiniBatchKMeans 알고리즘으로 비지도학습인 군집화를 진행해 주요 관심 키워드와 그룹을 도출하는 과정을 진행해보았습니다.
✨ 데이터 불러온 후, 전처리하기
- 먼저 댓글 데이터를 CSV 파일에서 불러오고, 중복 댓글을 제거해서 정확한 빈도 분석이 가능하도록 준비해줍니다.
import pandas as pd
# 데이터 불러오기
df = pd.read_csv('./data/event_text.csv')
# 중복 댓글 제거 (마지막 입력 유지: keep='last')
df = df.drop_duplicates(['text'], keep='last')
# 원본 보존을 위해 'origin_text' 생성
df['origin_text'] = df['text']- 전처리 과정에서는 댓글을 소문자로 변환해 대소문자 차이를 없앴고, 'python', 'pandas' 등 주요 용어를 한국어로 통일해 분석의 일관성을 높였습니다.
✨ 관심 강의 정보를 추출해주고 키워드도 표시하기
- 댓글에는 '관심강의'(혹은 '관심 강의', '관심 강좌')라는 단어 뒤에 강의명이 적힌 경우가 많았습니다.
- 그래서 이 강의명 부분을 잘라내 새로운 변수(course)로 저장하고,
- 특정 키워드(머신러닝, 파이썬 등)의 포함 여부를 각 컬럼에 True/False로 기록했습니다.
- 그 후에는 문자열을 분리해주고, replace를 사용해 불필요한 기호를 제거해주었습니다.
- 마지막으로는 반복문을 통해 각 관심 키워드의 포함 여부까지 추가했습니다.
✨ 이제는 필수 과정인 BoW, TF-IDF 벡터화
- 댓글 텍스트를 수치형 데이터로 변환하기 위해 CountVectorizer를 사용하여 단어 빈도 기반의 벡터(BoW)를 생성하고,
- TfidfTransformer를 통해 TF-IDF 가중치를 부여했습니다.
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
# n-gram 범위를 3~6으로 지정해 단어 조합을 분석
vectorizer = CountVectorizer(min_df=2, ngram_range=(3, 6), max_features=2000)
feature_vector = vectorizer.fit_transform(df['course'])
# TF-IDF 가중치 적용
tfidftrans = TfidfTransformer(smooth_idf=False)
feature_tfidf = tfidftrans.fit_transform(feature_vector)- BoW 방식은 각 댓글마다 등장하는 단어의 빈도수를 희소 행렬 형태로 표현하고,
- TF-IDF는 각 댓글 내에서 중요한 단어에 더 높은 가중치를 부여해, 단순 빈도 수보다 의미 있는 분석을 가능하게 해줄 수 있습니다.
✨ 이번엔 KMeans로 군집화 진행해보기
💡 먼저 KMeans를 이용해보자!
- KMeans의 엘보우(Elbow) 기법을 활용해서 최적의 군집 수를 결정한 후, 각 댓글이 어떤 클러스터에 속하는지 예측했습니다.
from sklearn.cluster import KMeans
from tqdm import trange
import matplotlib.pyplot as plt
# k값에 따른 이너셔(각 군집 내 오차 제곱합) 계산
inertia = []
for i in trange(10, 70):
kmeans = KMeans(n_clusters=i, random_state=42)
kmeans.fit(feature_tfidf)
inertia.append(kmeans.inertia_)
plt.plot(range(10, 70), inertia)
plt.title('KMeans 클러스터 수 비교')
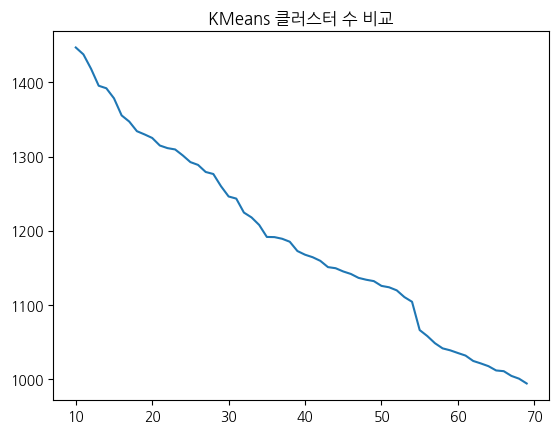
plt.show()- 그 후에 엘보우 플롯을 통해 급격하게 이너셔 값이 낮아지는 지점을 찾아서 최적의 클러스터 수를 설정합니다.
- 여기서는 52~53 정도인 것 같아보입니다.
💡 이번엔 MiniBatchKMeans를 사용해보고 실루엣 점수에 대해서 알아보자!
- 데이터가 많을 경우에는 MiniBatchKMeans를 사용해서 속도를 높일 수 있습니다.
- 또한, 실루엣 점수를 통해서 군집이 얼마나 잘 분리되었는지 평가할 수도 있습니다.
from sklearn.cluster import MiniBatchKMeans
from sklearn.metrics import silhouette_score
b_inertia = []
silhouettes = []
for i in trange(10, 70):
mkmeans = MiniBatchKMeans(n_clusters=i, random_state=42)
mkmeans.fit(feature_tfidf)
b_inertia.append(mkmeans.inertia_)
silhouettes.append(silhouette_score(feature_tfidf, mkmeans.labels_))- 여기서 실루엣 점수는 클러스터 내 데이터 간의 응집도와 클러스터 간 분리도를 동시에 평가해주는 지표입니다.
- 그래서 점수가 높을수록 군집이 잘 분리되었다고 판단할 수 있습니다.
✨ 결과가 얼마나 잘 나왔는지 시각화
- Yellowbrick 라이브러리를 사용하면, 엘보우나 실루엣 플롯을 통해 군집화 결과를 쉽게 시각화할 수 있습니다.
- 또한, 각 클러스터별로 대표 키워드를 추출해서 어떤 주제가 두드러지는지 평가할 수도 있습니다.
- 엘보우 플롯을 통해 최적의 클러스터 수를 결정하고, 실루엣 플롯으로 각 클러스터의 분리도를 확인한 후,
- 각 클러스터별 대표 단어('파이썬 강의', '공공데이터 활용' 등)를 분석해 추후에는 마케팅이나 고객 세그먼트에 활용할 수도 있다고 합니다.
from yellowbrick.cluster import SilhouetteVisualizer
visualizer = SilhouetteVisualizer(mkmeans, colors='yellowbrick')
visualizer.fit(feature_tfidf.toarray())
visualizer.show()
- 실루엣 플롯에서의 X축은 각 데이터의 실루엣 계수(-1~1 범위)이며, 1에 가까울수록 해당 데이터가 현재 클러스터에 잘 속해 있음을 의미합니다.
- 빨간 세로 점선은 전체 평균 실루엣 점수를 나타내며, 오른쪽으로 치우칠수록 군집 분리가 잘된 편입니다.
- 결과 그래프에서는 클러스터가 53개로 많아, 일부 클러스터가 얇게 나타나거나 음수 영역까지 뻗어 있는 것을 확인할 수 있었습니다.
- 서로 경계가 모호하거나 다른 클러스터에 속하는 게 자연스러울 수 있는 데이터인 것 같습니다.
- 평균 실루엣 점수가 크게 높지 않다면, 현재 군집 수가 너무 많거나 데이터 특성이 다양해 분리가 어렵다는 의미로 해석될 수 있습니다.
- 그래서 결과적으로 클러스터 수를 줄이거나 다른 군집화 알고리즘(DBSCAN 등)을 시도해보면, 분리가 더 명확해질 수 있고,
- 음수 구간이 많은 클러스터는 텍스트 전처리나 추가 변수 반영 등을 통해 개선할 여지가 있습니다.
🤔 36일차 회고
- 이제 지도학습에 대한 내용이 얼추 정리되고, 오늘은 비지도학습인 클러스터링을 배우게 되었습니다.
- 댓글 데이터 분석은 전에도 감성 분석 등에서 많이 해보았지만, 댓글을 군집화해보는 작업은 처음인 것 같습니다.
- 특히 텍스트 데이터라 그런지 군집이 많이 잡히는 경향이 있는 것 같은데, 추후에 전처리 과정을 더 진행하거나 다른 군집화 알고리즘도 사용해보고 싶습니다.
- 슬슬 제가 가게 될 회사의 도메인에 대한 고민이 깊어질 때인 것 같습니다.
- 지금까지 한 내용들을 토대로 한다면, 텍스트 데이터를 주로 다루는 곳이나 고객 분석 등을 해보는 곳으로 가보고 싶긴 한데... 더 고민해봐야할 듯 합니다.
728x90
LIST
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 이게 Flask였던가... (0) | 2025.03.31 |
|---|---|
| 🤔 타이타닉에서 살아남기 (0) | 2025.03.27 |
| 🤔 RNN과 LSTM 그리고 BiLSTM (6) | 2025.03.18 |
| 🤔 형태가 바뀌면 의미도 바뀔까? (0) | 2025.03.17 |
| 🤔 이번엔 좀 더 깊게 달려보자 (3) | 2025.03.13 |