

- 오늘은 벡터의 유사도와 관련해서 잠깐 오전에 배운 뒤에, 바로 머신러닝을 와다다 쏟아내며 배워보았습니다.
🏹 벡터의 유사도
- 문서의 유사성을 평가할 때 일반적으로 사용되는 기준은 두 문서가 얼마나 많은 공통 단어를 공유하는지이며, 이건 사람의 직관적인 판단 방식과 유사하게 진행됩니다.
- ML 기반의 자연어 처리에서도 동일한 원리가 적용되는데,
- 단어를 효과적으로 수치화하여 표현하는 방법(DTM, TF-IDF, Word2Vec 등)과
- 이러한 벡터 표현 간 유사도를 정량적으로 측정하는 방법(유클리드 거리, 코사인 유사도 등)이 핵심적인 역할을 해줍니다.
- 그 중에서 먼저 코사인 유사도를 살펴보겠습니다.
✨ 코사인 유사도(Cosine Similarity)
- 두 벡터 간 각도의 코사인 값을 사용하여 유사성을 측정하는 방법입니다.
- 이 유사도는 -1에서부터 1까지의 범위를 가지는데,
- 코사인 유사도가 1이라면, 동일한 방향이고 완전한 유사성을 띤다는 것을 의미하고,
- 0이 나오게 되면 직각 즉, 완전히 무관할 때의 결과입니다.
- -1은 완전한 반대 관계이지만, 오히려 주의 깊게 살펴볼 필요도 있습니다.
- 그렇기 때문에 1에 가까울수록 두 벡터는 더 높은 유사성을 가지게 됩니다.
💡 계산 예시
- 예를 들어, 문서 3개가 다음과 같이 주어질 때,
- 문서 1: "저는 사과가 좋아요", 문서 2: "저는 바나나가 좋아요", 문서 3: "저는 바나나가 좋아요 저는 바나나가 좋아요"
- 이 문서들을 토큰화해서 어제 배웠던 DTM을 구성하면 다음과 같은 벡터 형태(doc1, doc2, doc3)로 표현될 수 있습니다.
import numpy as np
from numpy import dot
from numpy.linalg import norm
def cos_sim(A, B):
return dot(A, B) / (norm(A) * norm(B))
doc1 = np.array([0, 1, 1, 1])
doc2 = np.array([1, 0, 1, 1])
doc3 = np.array([2, 0, 2, 2])
print('문서 1과 문서 2의 코사인 유사도:', cos_sim(doc1, doc2)) # 약 0.67
print('문서 1과 문서 3의 코사인 유사도:', cos_sim(doc1, doc3)) # 약 0.67
print('문서 2와 문서 3의 코사인 유사도:', cos_sim(doc2, doc3)) # 1.00
💡 np.dot() / np.linalg.norm()
- 위 코드에서 사용된 numpy의 dot() 함수는 두 배열(벡터 또는 행렬)의 점곱을 계산하는 데 사용되는 함수입니다.
- 이 함수는 다차원 배열에서도 작동하고 벡터와 행렬의 곱셈도 처리할 수 있는 능력자입니다!
- 단, 행렬 곱셈을 수행할 때는 첫 번째 행렬의 열의 수와 두 번째 행렬의 행의 수가 반드시 같아야 계산이 되고,
- 벡터의 내적을 수행할 때에는 두 벡터의 차원이 같아야 계산이 가능합니다.
- norm() 함수는 벡터의 표준(크기 또는 길이)을 계산하는 데 사용됩니다.
💡 결과를 분석해보면...
- 문서 2와 문서 3의 경우, 벡터의 방향성은 동일하고 각 단어의 빈도만 증가했기 때문에, 두 벡터 간 코사인 유사도는 정확히 1이 출력됩니다.
- 이것은 코사인 유사도가 벡터의 절대적 크기나 문서의 길이에 영향을 받지 않고, 벡터의 상대적 방향(즉, 단어의 상대적인 빈도 패턴)에만 초점을 맞추기 때문이라고 볼 수 있습니다.
💡 뒤에 나오는 유클리드 거리랑은 무슨 차이가 있을까?
- 유클리드 거리는 벡터의 절대적 크기 차이에 민감하기 때문에 같은 주제를 가진 문서라도 길이 차이에 따라 잘못된 유사성으로 평가될 가능성이 있습니다.
- 반면, 코사인 유사도는 길이나 절대 빈도가 아닌 문서의 상대적인 단어 빈도 패턴과 방향성에 기반해서 평가하기 때문에,
- 문서 길이에 상관없이 더 공정하고 신뢰할 수 있는 유사성 측정 결과를 제공해줄 수가 있습니다.
- 결론적으로 문서의 유사성을 살펴볼 때에는 유클리드 거리보다는 코사인 유사도를 사용하는 것이 더 효율적!!
🎬 줄거리를 이용해서 영화 추천 시스템 만들기 (간단하게)
- 영화 추천 시스템에서도 이런 유사도 계산 방법이 널리 사용되며, 특히 영화 줄거리를 기반으로 비슷한 영화를 찾는 것이 가능해졌습니다.
- 그래서 어제 배웠던 TF-IDF와 코사인 유사도를 활용해서 영화 줄거리 기반의 추천 시스템 구축해보는 실습을 해보았습니다.
- 데이터셋은 The Movies Dataset(Kaggle)에서 제공하는 movies_metadata.csv를 사용할 예정입니다.
import pandas as pd
# 데이터 로드 및 형식 확인
data = pd.read_csv('movies_metadata.csv', low_memory=False)
data.head(2)
💡 데이터 전처리하기
- 코사인 유사도를 계산하기 위해서는 영화 제목(title)과 영화 줄거리(overview) 열을 활용했어야 했습니다.
- 그리고 TF-IDF 벡터를 계산할 때, 데이터에 결측값이 있으면 문제가 발생하기 때문에 처리해주었습니다.
# Null 값 확인
print(data['overview'].isnull().sum())
# Null 값 빈 문자열로 대체
data['overview'] = data['overview'].fillna('')
💡 TF-IDF 벡터화 및 코사인 유사도 계산
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# TF-IDF 벡터화
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(data['overview'])
print('TF-IDF 행렬 크기:', tfidf_matrix.shape) # TF-IDF 행렬 크기: (45466, 76132)
# 코사인 유사도 행렬 생성
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
print('코사인 유사도 행렬 크기:', cosine_sim.shape)
💡 추천 시스템 구현해보기
- 영화 제목을 입력받아서 유사한 영화 10편을 추천하는 시스템을 구축해보았습니다.
# 영화 제목을 키로 하고 인덱스를 값으로 하는 딕셔너리 생성
title_to_index = dict(zip(data['title'], data.index))
# 영화 추천 함수 정의
def get_recommendations(title):
idx = title_to_index[title]
sim_scores = list(enumerate(cosine_similarity(tfidf_matrix[idx], tfidf_matrix)[0]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:11] # 자기 자신을 제외한 상위 10개
movie_indices = [idx[0] for idx in sim_scores]
return data['title'].iloc[movie_indices]
# 영화 "The Dark Knight Rises"와 유사한 영화 추천
recommended_movies = get_recommendations('Father of the Bride Part II')
print(recommended_movies)- 결과적으로 코사인 유사도를 이용한 이런 추천 시스템의 주요 특징은
- 벡터 방향성(단어의 상대적 빈도 및 패턴)에 초점을 맞추어 유사도 평가하고,
- 문서(영화 줄거리)의 길이나 절대적 단어 빈도보다는 내용의 주제적 유사성에 더 중점을 두어서 추천해주는 방식입니다.
- 그래서 문서 길이가 서로 다른 경우에도 비교적 공정한 평가가 가능해집니다.
✨ 유클리드 거리(Euclidean distance)
- 유클리드 거리는 다차원 공간에서 두 점 사이의 거리를 측정하는 가장 기본적이고 직관적인 거리 측정 방법입니다.
- 문서의 유사도를 평가할 때 사용 가능하긴 하지만, 뒤에 나오는 자카드 유사도나 코사인 유사도만큼 효과적이지는 않은 편입니다.
- 그래도 익숙한 거리일테니 알아는 두셔요!!
💡 유클리드 거리 공식
- 다차원 공간에 있는 두 점 $p=(p_1, p_2, \dots, p_n)$와 $q=(q_1, q_2, \dots, q_n)$ 사이의 유클리드 거리는 다음과 같이 정의됩니다.
$$ d(p, q) = \sqrt{(q_1 - p_1)^2 + (q_2 - p_2)^2 + \dots + (q_n - p_n)^2} = \sqrt{\sum_{i=1}^{n}(q_i - p_i)^2} $$
- 이 공식은 2차원 공간에서 피타고라스의 정리를 이용한 두 점 사이의 거리 계산법과 원리가 동일합니다.
💡 코드로 예시 살펴보기
import numpy as np
def euclidean_distance(A, B):
return np.linalg.norm(A - B)
doc1 = np.array([2, 3, 0, 1])
doc2 = np.array([1, 2, 3, 1])
doc3 = np.array([2, 1, 2, 2])
docQ = np.array([1, 1, 0, 1])
print('문서1과 문서Q의 거리:', euclidean_distance(doc1, docQ)) # 2.24
print('문서2과 문서Q의 거리:', euclidean_distance(doc2, docQ)) # 약 3.16
print('문서3과 문서Q의 거리:', euclidean_distance(doc3, docQ)) # 약 2.45- 결과적으로 유클리드 거리의 값이 작을수록 두 문서가 더 유사하다고 판단되고,
- 그래서 위 예시에서는 문서1과 문서Q가 가장 가까운 거리로 계산되기 때문에 가장 유사한 문서로 판단됩니다.
✨ 자카드 유사도(Jaccard Similarity)
- 자카드 유사도는 두 집합 간의 유사도를 측정하는 방법으로, 교집합과 합집합의 비율을 이용해서 계산되는 방식입니다.
- 즉, 두 문서가 공유하는 단어의 비율을 기반으로 유사도를 평가하는 방식이라고 보시면 되겠습니다.
💡 자카드 유사도 공식
- 두 개의 집합 A와 B가 있을 때, 자카드 유사도 $J(A, B)$는 다음과 같이 정의되는데,
$$ J(A, B) = \frac{|A \cap B|}{|A \cup B|} $$
- 값의 범위는 $0 \leq J(A, B) \leq 1$이고,
- 두 집합이 완전히 동일하면 자카드 유사도 값은 1, 공통 원소가 하나도 없다면 0을 가지게 됩니다.
💡 이것도 코드로 예시를 살펴봅시다!
doc1 = "apple banana everyone like likey watch card holder"
doc2 = "apple banana coupon passport love you"
# 토큰화
tokenized_doc1 = doc1.split()
tokenized_doc2 = doc2.split()
print('문서1:', tokenized_doc1)
print('문서2:', tokenized_doc2)
# 문서1: ['apple', 'banana', 'everyone', 'like', 'likey', 'watch', 'card', 'holder']
# 문서2: ['apple', 'banana', 'coupon', 'passport', 'love', 'you']
💡 여기서 합집합과 교집합을 계산할 때는?
# 합집합
union = set(tokenized_doc1).union(set(tokenized_doc2))
print('문서1과 문서2의 합집합:', union)
# 교집합
intersection = set(tokenized_doc1).intersection(set(tokenized_doc2))
print('문서1과 문서2의 교집합:', intersection)
# 문서1과 문서2의 합집합: {'you', 'passport', 'watch', 'card', 'love', 'everyone', 'apple', 'likey', 'like', 'banana', 'holder', 'coupon'}
# 문서1과 문서2의 교집합: {'apple', 'banana'}
# 자카드 유사도 계산
jaccard_similarity = len(intersection) / len(union)
print('자카드 유사도:', jaccard_similarity)
# 자카드 유사도: 0.16666666666666666- 결과적으로 apple과 banana 두 단어만이 두 문서에서 공통적으로 등장하므로 교집합 크기는 2입니다.
- 전체 단어들의 합집합 크기는 12이기 때문에, 자카드 유사도는 2 / 12 = 0.1667로 계산됨을 알 수 있습니다.
- 자카드 유사도는 단어의 단순 존재 여부를 기반으로 하기 때문에 단어의 빈도나 의미적 유사성을 고려하지 않습니다.
- 따라서 문서 간 유사도를 측정하는 데 있어 단순한 기준은 되어줄 수도 있겠지만, 정교한 비교가 필요한 경우에는 TF-IDF나 코사인 유사도를 활용하는 것이 적절하다고 봅니다.
🏃🏻 드디어 머신러닝!
- 머신러닝은 현재 영상 처리, 번역기, 음성 인식, 스팸 메일 탐지 등의 다양한 분야에서 활용되고 있습니다.
- 특히 더 나아간 방법인 딥러닝은 자연어 처리 분야에서 필수적인 역량으로 자리 잡고 있습니다.
- 그래서 기본적인 머신러닝 개념과 모델(선형 회귀, 로지스틱 회귀, 소프트맥스 회귀 등)들을 이해한 다음에야 딥러닝으로 확장이 가능하기 때문에 머신러닝을 배워보았습니다!
⚠️ 기존 프로그래밍 방식의 한계
- 전통적인 프로그래밍 방식으로 특정 문제를 해결하는 것은 어려울 수 있는데,
- 예를 들어, 머신러닝에서 빠질 수 없는 이미지로 고양이와 강아지를 구분하는 문제를 생각해보겠습니다.
- 사람은 사진을 보면 쉽게 구분할 수 있지만, 이를 프로그램으로 구현하는 것은 쉽지 않습니다. 사진의 각도나 조명, 피사체의 자세 변화 등으로 인해 일관된 규칙을 정의하기 어렵기 때문입니다.
- 이미지에서 특정 패턴(경계선 등)을 찾아서 알고리즘화하는 시도는 있었지만, 완벽하진 않았기에 이러한 한계를 극복하기 위해 머신러닝이 등장하게 되었습니다.
✨ 머신러닝은 어떻게 접근하고 학습할까?
- 머신러닝은 기존 프로그래밍과는 다르게, 데이터에서 직접 규칙성을 찾아 해결하는 방법을 사용합니다.
- 기존 방식은 사람이 직접 규칙을 정의하고 프로그램 작성하는 방식이었다면,
- 머신러닝 방식은 기계가 데이터를 학습하여 스스로 규칙을 발견하는 방식입니다.
💡 머신러닝의 학습 과정
- 데이터 수집
- 위의 예시(강아지/고양이 분류)에서는 여러 장의 강아지, 고양이 사진과 해당 라벨(강아지/고양이)을 제공해줘야겠죠.
- 모델 학습(Training)
- 기계가 데이터 속에서 패턴과 규칙을 학습하고,
- 학습이 진행되면서 점점 더 정확한 예측이 가능해지도록 합니다.
- 예측(Prediction)
- 새로운 이미지가 입력되었을 때, 학습된 규칙을 이용해 정답(강아지/고양이)을 예측합니다.
- 그래서 머신러닝 모델이 학습을 마치면, 새로운 데이터에 대해서도 정답을 찾아낼 수 있게 되는 것입니다.
✨ 그렇다면 모델은 어떻게 평가할까?
- 머신러닝 모델을 학습시키기 전에, 데이터를 훈련용, 검증용, 테스트용으로 분리하는 것이 일반적입니다.
- 여기서 훈련 데이터(Training Data)는 모델을 학습하는 데 사용되는 데이터이고,
- 보통 검증 데이터(Validation Data)는 모델 성능을 조정(튜닝)하는 데 사용됩니다.
- 뒤에 배울 과적합(Overfitting) 여부 판단을 하거나,
- 하이퍼파라미터(초매개변수) 조정할 때 사용됩니다.
- 마지막으로 테스트 데이터(Test Data)는 모델의 최종 성능 평가를 위해 사용되는 데이터입니다.
💡 그럼 일반 매개변수는 뭐고, 하이퍼파라미터는 뭐지?
- 하이퍼파라미터는 사람이 직접 설정하는 변수(학습률, 뉴런 개수, 층 수 등)로 사람이 조정을 할 수 있는 변수라고 생각하시면 되고,
- 매개변수(가중치나 편향 등)는 학습을 통해 모델이 자동으로 조정하는 값이라고 보시면 됩니다.
- 결과적으로 모델은 검증 데이터를 활용해 하이퍼파라미터 튜닝을 진행하고, 최종적으로 테스트 데이터로 모델을 평가하게 됩니다.
✨ 머신러닝의 대표 문제! 분류와 회귀!
- 머신러닝 문제는 크게 분류(Classification) 문제와 회귀(Regression) 문제로 나뉘게 됩니다.
💡 먼저 분류!
- 분류에는 크게 이진 분류와 다중 분류가 있는데,
- 이진 분류는 말 그대로 두 가지 선택지 중 하나를 선택하는 분류 방법으로, 합격 / 불합격을 판별하거나 스팸 메일을 탐지할 때 주로 사용되고,
- 다중 분류는 세 개 이상의 선택지 중 하나를 선택하는 방법으로, 도서를 분류(과학, IT, 만화 등)하는 문제 등에 주로 사용됩니다.
💡 그 다음은 회귀!
- 회귀는 보통 예측하는 문제에 자주 사용되는데, 예를 들어
- 연속형 데이터를 예측하는 문제로 부동산 가격 예측, 주가 예측 등이 있을 수 있고,
- 특정 범위 내에서 다양한 수치가 나올 수도 있는 예측 문제도 포함될 수 있습니다.
- 분류와 회귀에 관한 자세한 내용은 추후에 더 언급하겠습니다.
✨ 머신러닝은 어떻게 구분되나!?
- 머신러닝은 크게 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 자기지도 학습(Self-Supervised Learning) 등으로 구분됩니다.
- 여기서 지도 학습은 레이블(정답)이 있는 데이터로 학습되며, 모델이 예측값과 실제값의 차이를 줄이도록 학습하는 방법입니다.
- 스팸 메일을 분류하거나, 감성 분석, 음성 인식을 하는 데에 사용됩니다.
- 비지도 학습은 레이블(정답) 없이 데이터의 패턴을 학습하는 것으로 고객들을 군집화하거나, 토픽 모델링(LSA, LDA) 등을 진행할 때 사용됩니다.
- 자기지도 학습은 모델이 스스로 레이블(정답)을 생성해서 학습하는 방식으로 Word2Vec, BERT 같은 자연어 처리 모델에서 사용됩니다.
✨ 머신러닝에서 사용되는 샘플과 특성이란?
- 머신러닝에서는 독립 변수($x$)와 종속 변수($y$)를 이용해서 예측을 수행합니다.
- 여기서 샘플(Sample)은 데이터베이스의 레코드(record)와 유사한 개념으로, 하나의 데이터 행(row)을 의미하고,
- 특성(Feature)은 종속 변수를 예측하는 데 사용되는 독립 변수(x)들을 의미합니다.
- 머신러닝에서는 데이터를 행렬(Matrix) 형태로 표현하는 경우가 대부분인데, 이 행렬은 보통 독립 변수(n개) × 데이터 샘플(m개)의 행렬로 이루어집니다.
✨ 혼동 행렬(Confusion Matrix)은?
- 모델의 예측 결과를 평가하는 방법 중 하나로, 실제값과 예측값의 관계를 정리한 표입니다. 자격증 시험에 거의 무조건적으로 나오는 개념!
| 예측 참 (Positive) | 예측 거짓 (Negative) | |
| 실제 참 | TP (True Positive) | FN (False Negative) |
| 실제 거짓 | FP (False Positive) | TN (True Negative) |
💡 여기서 모델 성능 지표를 끄집어낼 수 있다...!
- 정밀도(Precision)는 위 행렬에서 TP / (TP + FP)를 나타내며 모델이 True로 예측한 것 중 실제 True인 비율을 의미합니다.
- 재현율(Recall)은 TP / (TP + FN)로 계산되고, 실제 True인 데이터 중에서 모델이 True로 예측한 비율
- 정확도(Accuracy)는 (TP + TN) / (TP + FN + FP + TN)처럼 계산되고, 전체 데이터 중에서 정답을 맞춘 비율을 뜻합니다.
- 그런데 이런 정확도만으로 성능을 평가하기 어려운 경우,
- 예를 들어, 스팸 메일 분류기 문제에서 전체 100개 중 5개가 스팸이면, 모든 메일을 "정상"으로 예측해도 정확도는 95%나 됩니다.
- 이런 경우에는 F1-score 등의 추가 평가 지표를 활용해야 합니다. F1-score는 나중에 추가로 작성해보겠습니다.
✨ 너무 많이 맞추거나, 너무 적게 맞추거나
💡 과적합(Overfitting)?
- 과적합은 훈련 데이터에 모델이 너무 맞춰져서 일반화가 어려운 경우를 뜻합니다.
- 즉, 훈련 데이터에서는 높은 성능을 보이지만, 테스트 데이터에서는 오히려 성능이 떨어지는 현상을 말합니다.
- 훈련 데이터를 너무 반복 학습해서 패턴이 아닌 노이즈까지 학습되버리는 것이 원인입니다.
- 따라서 이를 방지하기 위해서는 조기 종료(Early Stopping), 드롭아웃(Dropout), 데이터 증강(Data Augmentation)과 같은 추가 방법들이 사용되어져야 합니다.
💡 과소적합(Underfitting)?
- 훈련 데이터에도 제대로 학습이 안 된 경우를 의미합니다.
- 왜냐, 모델이 너무 단순하거나, 학습이 충분히 진행되지 않아서 발생하는 문제입니다.
- 그래서 이럴 경우에는 모델의 복잡도를 증가시킨다든지, 학습 데이터를 추가한다든지, 학습 횟수(Epoch)를 늘리든지 해야합니다.
💡 머신러닝에서는 과적합을 어떻게 방지하나?
- 머신러닝에서는 데이터를 분리하는 방법으로 과적합을 방지하는데, 일반적으로 훈련, 검증, 테스트 데이터를 6:2:2 비율로 나누어 진행합니다.
- 여기서 훈련 데이터(Training Set)는 모델 학습용 데이터, 검증 데이터(Validation Set)는 과적합 방지 및 하이퍼파라미터 튜닝용 데이터를 의미하고, 마지막 테스트 데이터(Test Set)는 모델의 최종 성능을 평가할 때 사용됩니다.
- 훈련 과정은 보통 다음과 같이 진행됩니다.
- 훈련 데이터로 모델을 먼저 학습하기
- 검증 데이터로 모델 성능 평가하기 (과적합 여부 판단 과정 추가)
- 검증 데이터의 성능이 악화되면 학습 종료하기
- 최종 테스트 데이터로 성능 평가하기
⌛ 선형 회귀
- 선형 회귀(Linear Regression)는 독립 변수(x)와 종속 변수(y) 사이의 선형 관계를 모델링하는 방법입니다.
- x 값이 증가하거나 감소함에 따라 y 값이 영향을 받는 경우에 주로 사용되는데,
- 공부 시간을 늘릴수록 성적이 올라간다거나
- 집의 평수가 클수록 가격이 비싸진다거나
- 운동 시간이 많을수록 체중이 감소할 때 등에 사용됩니다.
✨ 단순 선형 회귀(Simple Linear Regression)
- 독립 변수(x)가 하나일 때 사용되는 선형 회귀 방법입니다.
- 기본적으로 $y=wx+b$의 수식을 사용하는데, 여기서 w는 가중치로 직선의 기울기를 나타내고, b는 편향으로 직선의 절편을 의미합니다.
✨ 다중 선형 회귀(Multiple Linear Regression)
- 두번째는 다중 선형 회귀인데, 말 그대로 독립 변수(x)가 여러 개일 때 사용되는 회귀 방법입니다.
- 기본적으로 $y = w_1x_1 + w_2x_2 + ... + w_nx_n + b$의 수식을 사용하는데, 여러 개의 독립 변수가 종속 변수(y)에 영향을 미칠 수 있다는 것을 의미합니다.
💡 머신러닝에서의 가설(Hypothesis)
- 주어진 데이터에서 x와 y 사이의 관계를 추론하는 식을 세우는 과정을 가설식을 세운다~라로 합니다.
- $H(x)$라고 보통 불리고 수식은 $H(x)=wx+b$와 같이 세울 수 있습니다.
- 이 가설식의 목표는 가장 적절한 $w$와 $b$를 찾아, 데이터에 최적화된 직선을 만드는 것입니다.
💡 선형 회귀의 목표
- 가설식의 목표와 정확히 일치하는데, 데이터에 가장 잘 맞는 직선을 찾는 것이 주된 목표입니다.
- 이 직선을 찾기 위해서 적절한 가중치($w$)와 편향($b$)을 최적화하고,
- 도출된 직선을 기반으로 새로운 데이터에 대해 예측이 가능하게 됩니다.
✨ 비용 함수(Cost Function)란?
- 머신러닝에서 목적 함수(Objective Function)는 최적의 모델을 찾기 위해 값을 최소화 또는 최대화하는 함수를 뜻하고,
- 비용 함수(Cost Function)나 손실 함수(Loss Function)는 모델의 오차를 측정하고, 이를 최소화하기 위한 함수를 의미합니다.
- 머신러닝에서 비용 함수는 예측값과 실제값 사이의 차이를 나타내고, 이 함수를 모델이 예측한 값이 실제값과 얼마나 가까운지를 평가하는 기준으로 삼을 수 있습니다.
💡 오차를 줄여야 모델이 좋다!
- 모델의 예측값 $H(x)$와 실제값 $y$ 간의 차이를 오차라고 하는데, 이 오차를 줄여야 모델의 성능이 좋아지게 됩니다.
- 오차는 단순히 $y - H(x)$와 같이 계산하면 되는데, 이 모든 오차를 단순히 합하면 양수와 음수가 상쇄되는 문제가 발생할 수 있습니다.
- 이 문제를 해결하기 위해 각 오차를 제곱한 후 합산하는 방법을 사용하기도 합니다.
$$ \sum (y - H(x))^2 $$
- 이렇게 제곱을 하면 모든 오차가 양수가 되어 상쇄되지는 않겠는데...
- 데이터 개수가 많아질수록 오차의 합은 커지기 때문에 평균을 구하는 과정이 필요합니다.
💡 그래서 우린 MSE를 사용한다!
- 위에서 구한 오차 제곱합을 데이터 개수로 나눈 값을 사용해서 모델의 성능을 평가하는 데 사용됩니다.
$$ MSE = \frac{1}{n} \sum_{i=1}^{n} (y^{(i)} - H(x^{(i)}))^2 $$
- 이 MSE 값이 작을수록 모델이 실제 데이터와 가까운 예측을 하고 있음을 의미합니다.
- 이 MSE는 단위가 제곱 형태이기 때문에, 원래 단위와 차이가 날 수는 있습니다. (그래서 나중에는 RMSE 사용...)
✨ 그럼 이 비용 함수는 어떻게 최적화할까?
- 비용 함수 $Cost(w, b)$의 값을 최소화하는 최적의 $w$와 $b$를 찾는 것이 최적화의 목표입니다.
$$ Cost(w, b) = \frac{1}{n} \sum_{i=1}^{n} (y^{(i)} - H(x^{(i)}))^2 $$
- 비용 함수가 최소가 되는 $w$와 $b$를 찾아야 가장 적절한 직선을 얻을 수 있는데, 이 과정에서 경사 하강법(Gradient Descent)과 같은 최적화 알고리즘이 사용됩니다.
💡 옵티마이저, 그 중에서도 경사 하강법
- 머신러닝 및 딥러닝에서는 모델을 학습시키기 위해 비용 함수를 최소화하는 최적의 매개변수(w, b)를 찾아야 합니다.
- 이를 수행하는 알고리즘을 옵티마이저(Optimizer) 또는 최적화 알고리즘이라고 부릅니다.
- 옵티마이저 종류는 다양하게 있지만, 우선은 경사 하강법(GD)부터 배우게 되었습니다.
💡 경사 하강법(Gradient Descent)은?
- 비용 함수 $Cost(w,b)$의 값이 가장 작은 최적의 $w$를 찾는 것에 목표를 두고 나아가는 방법입니다.
- 이것을 위해서 비용 함수의 기울기(미분값)를 구해, 기울기가 0에 가까워지는 방향으로 지속적으로 $w$를 변경해줍니다.
- 이 과정을 반복하면 비용 함수가 최소가 되는 $w$ 값으로 수렴되는 결과를 얻게 됩니다.
- 기울기와 비용 함수의 관계에서는
- 기울기 $\frac{\partial}{\partial w} Cost(w)$가 양수라면, $w$를 감소시켜야 하고,
- 기울기 $\frac{\partial}{\partial w} Cost(w)$가 음수라면, $w$를 증가시켜야 합니다.
💡 경사 하강법은 어떻게 나타나나?
$$ w := w - \alpha \frac{\partial}{\partial w} Cost(w) $$
- 위 수식에서 $\alpha$(학습률, Learning Rate)는 한 번에 얼마나 크게 이동할지를 결정하는 친구입니다.
- 이 학습률이 너무 크면 발산하거나 최솟값을 놓칠 수가 있고, 학습률이 너무 작으면 수렴 속도가 매우 느려집니다. 그래서 최적의 학습률을 설정하는 것이 중요합니다!
- 이 경사 하강법은 보통 다음과 같이 진행됩니다.
- 초기 랜덤 $w$ 설정하기
- 비용 함수의 기울기(미분값) 계산하기
- 기울기에 따라 $w$ 업데이트하기
- 비용 함수의 값이 더 이상 줄어들지 않으면 학습을 종료하기
- 실제로 경사 하강법을 적용할 때에는 $w$와 함께 편향 $b$도 함께 최적화 해야 합니다.
- 그리고 일반적으로 선형 회귀에서는 MSE와 경사 하강법이 가장 적합한 비용 함수와 옵티마이저 조합으로 확인되고 있습니다.
✨ 선형 회귀 구현해보기!
- 머신 러닝에서는 비용 함수를 최적화하기 위해 미분을 활용해서 모델의 가중치 $w$와 편향 $b$를 업데이트해줍니다.
- Tensorflow에서는 tf.GradientTape()를 사용하여 자동 미분을 수행할 수 있습니다.
import tensorflow as tf
w = tf.Variable(2.)
def f(w):
y = w**2
z = 2*y + 5
return z
with tf.GradientTape() as tape:
z = f(w)
gradients = tape.gradient(z, [w])
print(gradients)
# 출력: [<tf.Tensor: shape=(), dtype=float32, numpy=8.0>]- tape.gradient(z, [w])를 사용하게 되면, $w$에 대한 미분 값을 자동으로 계산할 수 있고, 이 기능을 통해 선형 회귀 모델을 학습할 수도 있습니다.
💡 그래서 어떻게 선형 회귀를 구현하는데?
- 먼저 학습할 변수와 가설부터 정의하겠습니다.
w = tf.Variable(4.0) # 초기 가중치
b = tf.Variable(1.0) # 초기 편향
@tf.function
# 내부 함수를 고치기 위한 오버라이딩
def hypothesis(x):
return w * x + b- 현재 w = 4, b = 1로 설정되어 있기 때문에 입력값을 넣으면 다음과 같은 결과가 출력되는 것을 확인할 수 있습니다.
x_test = [3.5, 5, 5.5, 6]
print(hypothesis(x_test).numpy())
# 출력: [15. 21. 23. 25.]- 그 후로 손실 함수인 MSE를 정의해보았습니다.
@tf.function
def mse_loss(y_pred, y):
return tf.reduce_mean(tf.square(y_pred - y))- 위 함수는 실제값 $y$와 예측값 $y_{pred}$ 의 차이를 제곱하고, 평균을 구해서 오차를 측정하게 됩니다.
💡 옵티마이저 설정하고 학습시켜보기!
x = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 공부한 시간
y = [11, 22, 33, 44, 53, 66, 77, 87, 95] # 시험 성적
optimizer = tf.optimizers.SGD(0.01) # 확률적 경사 하강법(SGD), 학습률 0.01
for i in range(301):
with tf.GradientTape() as tape:
y_pred = hypothesis(x) # 예측값
cost = mse_loss(y_pred, y) # 비용 함수 계산
gradients = tape.gradient(cost, [w, b]) # w, b에 대한 기울기 계산
optimizer.apply_gradients(zip(gradients, [w, b])) # w, b 업데이트
if i % 10 == 0:
print(f"epoch : {i:3} | w: {w.numpy():.4f} | b: {b.numpy():.4f} | cost: {cost.numpy():.6f}")
# epoch : 0 | w: 8.2133 | b: 1.664 | cost: 1402.555542
# ...
# epoch : 300 | w: 10.6269 | b: 1.161 | cost: 1.086645- 학습이 진행될수록 w와 b의 값이 조정되면서 cost가 줄어드는 것을 확인할 수 있고,
- 최적화가 완료되면 새로운 입력값에 대한 예측을 수행할 수 있습니다.
x_test = [3.5, 5, 5.5, 6]
print(hypothesis(x_test).numpy())
# 출력: [38.35 54.29 59.60 64.92]
💡 이번에는 Keras로 간단히 구현해보자!
- Tensorflow의 Keras를 사용하면 더욱 간단하게 선형 회귀 모델 구현이 가능합니다.
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]) # 공부한 시간
y = np.array([11, 22, 33, 44, 53, 66, 77, 87, 95]) # 시험 성적
model = Sequential()
model.add(Dense(1, input_dim=1, activation='linear')) # 선형 회귀 모델
sgd = optimizers.SGD(learning_rate=0.01) # 확률적 경사 하강법(SGD) 사용, 학습률 0.01
model.compile(optimizer=sgd, loss='mse', metrics=['mse'])
model.fit(x, y, epochs=300) # 300번 학습 수행- 입력의 차원(input_dim)은 1(공부한 시간)로 설정하고, 출력 차원도 1(예측된 성적)으로 설정합니다.
- 다중 선형 회귀를 하고 싶으시면, 데이터를 변경한 뒤, 입력 차원을 원하시는 차원으로 변경하시면 다중 선형 회귀 모델도 쉽게 구축이 가능합니다!
- 선형 회귀이기 때문에 활성화 함수는 'linear'로 설정하면 되고, 옵티마이저는 SGD(Stochastic Gradient Descent)로 설정했습니다.
- 여기서 SGD 함수에 lr 인자를 넣게 되면 ValueError가 날 수 있습니다. TensorFlow 2.x 버전에서는 optimizers.SGD() 함수의 lr(learning rate) 인자가 learning_rate로 변경되었으니 참고 부탁드립니다!
- 마지막으로 손실 함수는 MSE로, 학습률은 0.01로 설정해서 진행했습니다.
⌛ 로지스틱 회귀
- 로지스틱 회귀는 이진 분류 문제를 해결하기 위한 대표적인 알고리즘입니다.
✨ 이진 분류 문제는 어떻게 접근해?
- 앞서 배운 선형 회귀는 데이터를 직선으로 표현하는 방법이지만,
- 이진 분류 문제는 직선이 아니라 'S'자 형태의 곡선(Sigmoid Function)으로 표현하는 것이 적절합니다.
| 시험 점수 (score) | 결과 (result) |
| 45 | 불합격 (0) |
| 50 | 불합격 (0) |
| 55 | 불합격 (0) |
| 60 | 합격 (1) |
| 65 | 합격 (1) |
| 70 | 합격 (1) |
- 위 데이터를 그래프로 표현하면, 점수가 55를 기준으로 급격히 변하는 S자 곡선이 필요하게 됩니다.
- 이것 때문에 시그모이드 함수(Sigmoid Function)를 사용하게 되는 것입니다.
✨ 시그모이드 함수는 어떻게 생겼지?
- 위에서 언급했듯이, 로지스틱 회귀에서 사용되는 함수는 시그모이드 함수이며, 수식은 다음과 같습니다.
$$ H(x) = \frac{1}{1 + e^{-(wx + b)}} $$
- 이것을 간단히 시그모이드 함수로 정의하면 아래와 같아집니다.
$$ \sigma(wx + b) = \frac{1}{1 + e^{-(wx + b)}} $$
- 여기서 w는 가중치(weight)로, 기울기를 조절해주는 역할을 해주고, b는 편향(bias)으로 곡선 이동에 관여하는 역할을 해줍니다.
💡 그래프는 어떻게 생겼을까?
- 시그모이드 함수는 출력값이 0과 1 사이로 조정되고, 다음과 같은 특징을 가지게 됩니다.
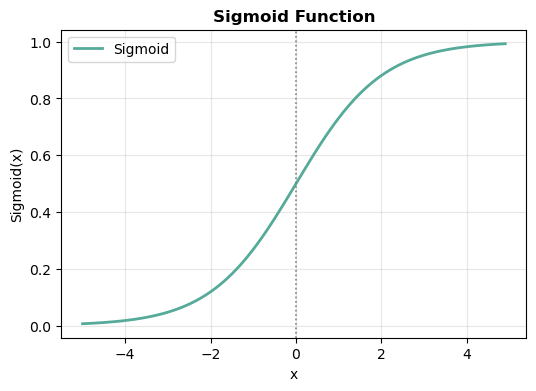
- x = 0일 때 출력값은 0.5이고, x가 증가하면, 값이 1에 가까워집니다.
- 또, x가 감소하면 값이 0에 수렴하는 꼴입니다. 즉, x가 특정 값을 기준으로 0과 1 사이의 확률 값으로 변환되는 것을 확인할 수 있습니다.
💡 가중치가 변하면 어떻게 그려질까?
- 가중치인 w 값이 더욱 커질수록 그래프의 경사도가 커지게 됩니다.
- 즉, 더 빠르게 0과 1로 나뉘게 된다는 것을 알 수 있습니다. 아래 그림으로 확인하시죠!
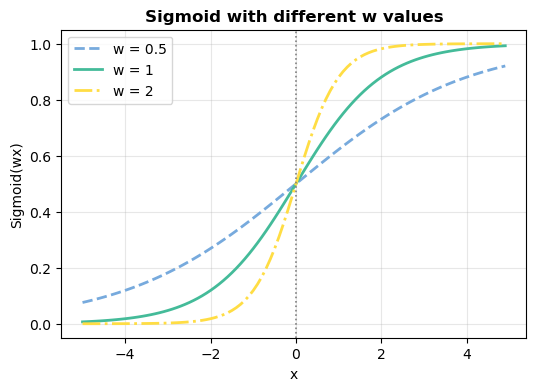
- 가중치가 0.5일 때, 그래프는 완만하고, 그에 반해, 2일 때는 그래프가 급격하게 변하는 것을 확인할 수 있습니다.
💡 절편값이 바뀌면 어떻게 그려질까? (당연히 움직이겠지...)
- 위에서도 얘기드렸듯, b 값은 그래프를 좌우로 이동시키는 역할을 해줍니다.

✨ 로지스틱에서의 비용 함수는?
- 로지스틱 회귀는 경사 하강법을 사용해서 가중치 w와 편향 b를 찾게 됩니다.
- 하지만, 선형 회귀처럼 평균 제곱 오차(MSE)를 비용 함수로 사용하면, 로컬 미니멈(Local Minimum)에 빠질 가능성이 크기 때문에 문제가 발생합니다.
$$ \text{MSE} = \frac{1}{n} \sum (y - H(x))^2 $$
- 선형 회귀와 같이 이 MSE 함수를 Cost Function으로 사용하면 경사 하강법이 잘못된 최적점에서 멈출 수 있습니다.
💡 그래서 새로운 비용 함수를 사용하자!
- 로지스틱 회귀에서는 크로스 엔트로피(Cross Entropy) 비용 함수를 사용하게 됩니다. 아래와 같은 수식을 가집니다.
$$ J(w) = -\frac{1}{n} \sum \left[ y \log H(x) + (1 - y) \log (1 - H(x)) \right] $$
- y = 1일 때에는 $logH(x)$ 사용해서 $H(x)$가 1에 가까울수록 비용이 감소하는 구조이고,
- y = 0일 때에는 반대로 $log(1−H(x))$ 사용해서 $H(x)$ 가 0에 가까울수록 비용이 감소하는 구조입니다.
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0.01, 0.99, 100)
y1 = -np.log(x) # 실제값 1일 때 비용 함수
y2 = -np.log(1 - x) # 실제값 0일 때 비용 함수
plt.plot(x, y1, 'b--', label='y=1')
plt.plot(x, y2, 'r--', label='y=0')
plt.title("Cross Entropy Loss")
plt.legend()
plt.show()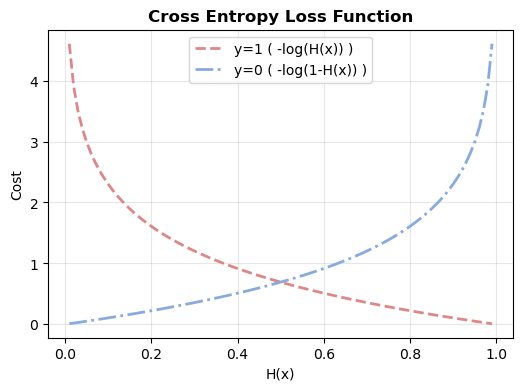
- 위의 붉은 선이 y=1일 때의 비용 함수인데, 확인해보시면 H(x)가 1에 가까울수록 비용이 낮아지는 것을 확인할 수 있습니다.
✨ Keras로 로지스틱 회귀를 구현해보자!
- 먼저 입력 데이터(독립 변수)와 출력 데이터(레이블)를 생성해줬습니다. 입력값으로는 -50부터 50까지의 다양한 값들, 그리고 레이블은 10 이상이면 1, 10 미만이면 0으로 설정했습니다.
- 즉, 숫자 10을 기준으로 이진 분류하는 데이터셋을 생성해낸 것입니다.
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
# 입력 데이터 (독립 변수)
x = np.array([-50, -40, -30, -20, -10, -5, 0, 5, 10, 20, 30, 40, 50])
# 레이블 데이터 (10 이상이면 1, 미만이면 0)
y = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
💡 로지스틱 회귀 모델의 구성
- 선형 회귀 모델을 구축했듯 keras의 Dense()를 활용해서 쉽게 회귀 모델을 구성할 수 있는데,
- Dense(1, input_dim=1, activation='sigmoid')와 같이 작성하게 되면,
- 출력 뉴런 1개 (이진 분류이기 때문에)
- 입력 차원 1개 (단순한 1차원 입력 넣을거야~ / 이 차원에 따라 다중 입력도 가능)
- 활성화 함수는 sigmoid(이진 분류에 주로 사용)으로 세팅한다는 뜻이 됩니다.
- 옵티마이저로는 SGD를 사용했고, (사실 이 GD만 배웠지, SGD는 아직 배우지도 않음)
- 손실 함수는 binary_crossentropy 즉, 크로스 엔트로피를 사용했습니다.
- 에포크(Epoch)는 200회 반복해서 학습을 진행했습니다.
# 모델 정의
model = Sequential()
model.add(Dense(1, input_dim=1, activation='sigmoid'))
# 옵티마이저 설정 (학습률 0.01)
sgd = optimizers.SGD(learning_rate=0.01)
# 모델 컴파일 (이진 분류이므로 binary_crossentropy 사용)
model.compile(optimizer=sgd, loss='binary_crossentropy', metrics=['binary_accuracy'])
# 모델 학습 (총 200번 반복)
model.fit(x, y, epochs=200)- 학습이 진행되면서 손실값은 줄어들고, 정확도(Binary Accuracy)는 점점 증가하는 것을 눈으로 확인할 수 있었습니다.
💡 학습된 모델로 예측해보면?
- 학습된 모델을 사용해서 입력값(x)에 대한 예측값을 시각적으로 확인하기 위해 그래프를 그려보았습니다.
# 예측값과 실제 데이터를 비교하는 그래프
plt.figure(figsize=(6, 4))
plt.plot(x, model.predict(x), 'b', label="Prediction") # 예측값(파란선)
plt.scatter(x, y, color='k', marker='o', label="Actual Data") # 실제값(검은 점)
plt.axhline(0.5, color='gray', linestyle=':') # 기준선 (0.5)
plt.xlabel("Input Value (x)")
plt.ylabel("Predicted Probability")
plt.title("Logistic Regression Model", fontsize=12, fontweight='bold')
plt.legend()
plt.grid(alpha=0.3)
plt.show()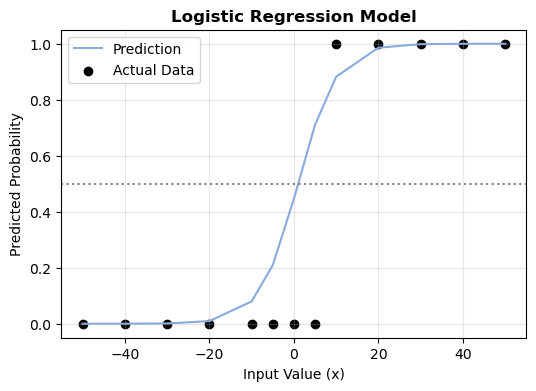
💡 새로운 값을 넣어서 예측해보자!
# x 값이 5보다 작은 경우 (0.5 이하 예측)
print(model.predict([1, 2, 3, 4, 4.5]))
# x 값이 10보다 큰 경우 (0.5 이상 예측)
print(model.predict([11, 21, 31, 41, 500]))
'''
[[0.21071826] # 1 → 0.21
[0.26909265] # 2 → 0.27
[0.33673897] # 3 → 0.34
[0.41180944] # 4 → 0.41
[0.45120454]] # 4.5 → 0.45
[[0.86910886] # 11 → 0.87
[0.99398106] # 21 → 0.99
[0.99975663] # 31 → 0.999
[0.9999902 ] # 41 → 0.9999
[1. ]] # 500 → 1.0
'''- 5보다 작은 값은 0.5 이하, 즉 0(불합격)으로 예측하는 것을 볼 수 있고,
- 10보다 큰 값은 0.5 이상, 즉 1(합격) 으로 예측하는 것을 확인할 수 있습니다.
- 이렇게 로지스틱 회귀는 S자 형태의 시그모이드 함수를 사용하여 연속된 값들을 확률(0~1)로 변환해서 이진 분류를 수행합니다.
✨ 벡터와 행렬
- 머신러닝과 딥러닝에서 데이터를 다루는 방식은 대부분 벡터와 행렬, 그리고 텐서(Tensor) 연산으로 이루어집니다.
- 기본적으로 숫자(스칼라)에서 시작해서 벡터(1차원 배열), 행렬(2차원 배열), 그리고 텐서(다차원 배열)로 확장됩니다.
💡 스칼라(Scalar)
- 스칼라는 가장 기본적인 수치 값, 즉 하나의 숫자를 의미합니다. 수학적으로는 0차원 텐서(0D Tensor)라고도 부릅니다.
💡 벡터(Vector)
- 벡터는 숫자들이 나열된 1차원 배열입니다. 머신러닝에서는 하나의 샘플(feature set)을 표현할 때 벡터를 자주 사용합니다.
- 헷갈리시면 안 되는 게, 벡터의 "차원(Dimension)"과 "텐서의 차원"은 다른 개념입니다.
- 벡터에서 차원은 벡터에 포함된 숫자의 개수를 의미하지만, 텐서에서의 차원은 그 구조의 복잡도를 나타냅니다.
💡 행렬(Matrix)
- 행렬은 행(row)과 열(column)로 구성된 2차원 배열입니다. 예를 들어서 다음과 같은 표를 행렬로 표현하게 되면, 그 다음과 같습니다.
| 방 개수(x1) | 층수(x2) | 연식(x3) |
| 2 | 1 | 10 |
| 4 | 2 | 20 |
| 3 | 2 | 15 |
$$ X = \begin{bmatrix} 2 & 1 & 10 \\ 4 & 2 & 20 \\ 3 & 2 & 15 \end{bmatrix} $$
💡 텐서(Tensor)
- 텐서는 행렬을 넘어서 3차원 이상의 구조를 가진 다차원 배열입니다.
- 보통 이미지 데이터를 다룰 때 RGB 값이 포함된 3차원 텐서를 사용합니다.
- 자연어 처리에서도 문장 데이터는 (Batch, Timesteps, Features) 형태의 3D 텐서로 표현됩니다.
✨ 그럼 연산은 어떻게 해?
💡 벡터별로 더하기와 빼기
- 벡터는 같은 크기일 때 요소별(element-wise)로 연산이 이루어집니다.
$$ A = \begin{bmatrix} 8 \\ 4 \\ 5 \end{bmatrix}, \quad B = \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix} $$
$$ A + B = \begin{bmatrix} 9 \\ 6 \\ 8 \end{bmatrix}, \quad A - B = \begin{bmatrix} 7 \\ 2 \\ 2 \end{bmatrix} $$
💡 그럼 내적은?
- 벡터의 내적은 대응하는 원소를 곱한 후 합하는 연산입니다.
$$ \mathbf{a} \cdot \mathbf{b} = (1 \times 4) + (2 \times 5) + (3 \times 6) = 32 $$
💡 내적은 완전한 곱셈이 아닌 거 같아
- 행렬 곱은 단순한 요소별 곱셈이 아니라, 행렬의 가로(행) 벡터와 세로(열) 벡터의 내적을 계산하는 방식으로 이루어집니다.
$$ \begin{bmatrix} 1 & 3 \\ 2 & 4 \end{bmatrix} \times \begin{bmatrix} 5 & 7 \\ 6 & 8 \end{bmatrix} = \begin{bmatrix} (1×5 + 3×6) & (1×7 + 3×8) \\ (2×5 + 4×6) & (2×7 + 4×8) \end{bmatrix} $$
A = np.array([[1, 3], [2, 4]])
B = np.array([[5, 7], [6, 8]])
print(np.matmul(A, B))
💡 다중 선형 회귀와 행렬 연산
- 선형 회귀는 하나의 종속 변수 $y$를 여러 개의 독립 변수 $x_1, x_2, ... x_n$로 예측하는 모델입니다.
- $y = w_1 x_1 + w_2 x_2 + ... + w_n x_n + b$를 행렬 연산으로 표현하면 $Y = XW + B$와 같이 나타낼 수 있는데, 여기서
- $X$는 입력 데이터 행렬 ($m × n$), $W$는 가중치 벡터 ($n × 1$), $B$는 편향 벡터 ($m × 1$), $Y$는 출력 값 ($m × 1$)을 의미합니다.
💡 크기가 맞아야 곱셈이 가능!
- 행렬 곱 연산이 성립하려면 아래 조건을 맞춰야 합니다.
$$X_{m \times n} \times W_{n \times j} + B_{m \times j} = Y_{m \times j}$$
- 즉, 입력 행렬 X의 열 개수가 가중치 행렬 W의 행 개수와 같아야하고,
- 출력 행렬 Y의 크기는 B의 크기와 같아야 합니다.
⌛ 소프트맥스 회귀
✨ 먼저 다중 클래스 분류란?
- 이전의 로지스틱 회귀는 이진 분류 문제를 해결하기 위한 방법으로, 주어진 입력 데이터가 특정 두 개의 범주 중 하나에 속할 확률을 예측하는 모델이었습니다.
- 그렇지만 다중 클래스 분류(Multi-class Classification)는 선택지가 두 개 이상인 경우를 의미합니다.
- 예를 들어, 붓꽃 품종 분류(Iris Classification) 문제에서 꽃받침 길이, 꽃잎 길이 등의 입력 데이터를 이용해 setosa, versicolor, virginica 중 하나로 분류해야 합니다.
- 이진 분류는 시그모이드(Sigmoid) 함수를 사용하지만, 다중 클래스 분류는 소프트맥스(Softmax) 함수를 사용합니다.
✨ 소프트맥스에서의 비용 함수는? (제곧답)
- 소프트맥스 함수 자체가 바로 다중 클래스 분류 문제에서 각 클래스에 대한 확률을 추정하는 역할을 합니다.
- 주어진 입력 데이터 $z_i$에 대해 다음과 같이 정의됩니다.
$$ p_i = \frac{e^{z_i}}{\sum_{j=1}^{k} e^{z_j}}, \quad \text{for } i = 1, 2, \dots, k $$
- 즉, 각 클래스 $i$의 확률 $p_i$는 해당 클래스의 지수 함수 값 $e^{z_i}$을 모든 클래스의 지수 함수 값의 합으로 나눈 값입니다.
- 이렇게 하면, 모든 확률 $p_i$ 값의 합이 항상 1이 되도록 보정되므로 각 클래스가 정답일 확률을 직접적으로 비교할 수 있습니다.
- 붓꽃 데이터셋을 예로 들면, $z$ 값들이 다음과 같이 주어졌다고 가정해 보겠습니다.
$$ softmax(z) = \left[ \frac{e^{z_1}}{\sum_{j=1}^{3} e^{z_j}}, \frac{e^{z_2}}{\sum_{j=1}^{3} e^{z_j}}, \frac{e^{z_3}}{\sum_{j=1}^{3} e^{z_j}} \right] = [p_1, p_2, p_3] $$
- 이때, 각 확률 값은 특정 붓꽃 품종일 확률을 의미하며, 예측값은 가장 높은 확률을 가진 클래스로 결정됩니다.
$$ softmax(z) = [p_{virginica}, p_{setosa}, p_{versicolor}] $$
✨ 소프트맥스 회귀는 어떻게 동작할까?
💡 먼저 입력 데이터를 변환해!
- 입력 데이터 $X$가 주어지면, 이를 가중치 $W$와 곱하고, 편향 $B$를 더해 예측값 $Z$를 구합니다.
$$ Z = WX + B $$
- 입력 데이터는 SepalLength, SepalWidth, PetalLength, PetalWidth로 총 4개의 특성이 들어가게 되고,
- 가중치 행렬 $W$는 3 × 4 크기로 주어지고, (3개의 클래스, 4개의 특성)
- 편향 $B$는 3 × 1 크기,
- 출력 $Z$도 마찬가지로 3 × 1 크기입니다.
💡 그 다음은 소프트맥스를 적용!
$$\hat{y} = softmax(Z)$$
- 소프트맥스 함수를 사용해서 각 클래스의 확률을 계산합니다.
💡 마지막은 원-핫 벡터와 비교해서 오차 계산하자!
- 실제 클래스 값은 원-핫 벡터(One-hot Vector)로 표현됩니다.
| 품종 | 원-핫 벡터 |
| virginica | [1, 0, 0] |
| setosa | [0, 1, 0] |
| versicolor | [0, 0, 1] |
- 소프트맥스 함수의 출력값(예측값)과 원-핫 벡터(실제값)를 비교하여 오차를 계산합니다.
- 오차는 일반적으로 소프트맥스 회귀에선 아래와 같이 크로스 엔트로피 함수를 사용합니다.
$$J = -\sum_{i=1}^{k} y_i \log (\hat{y}_i)$$
- 여기서 $y_i$는 실제 클래스의 원-핫 벡터의 값이고, $\hat{y}_i$는 모델이 예측한 확률 값을 의미합니다.
- 즉, 정답 클래스의 확률이 높을수록 비용 함수 값이 작아지고, 정답 클래스의 확률이 낮을수록 비용 함수 값이 커집니다.
- keras에서 모델 컴파일을 진행할 때에는 categorical_crossentropy를 사용하면 됩니다.
✨ 가중치 업데이트(Gradient Descent)해주기!
💡 오차를 통한 역전파
- 모델이 예측한 값과 실제 정답 값 사이의 차이(오차)를 기반으로 역전파(Backpropagation)를 수행하여 가중치와 편향을 업데이트합니다.
$$W = W - \alpha \frac{\partial J}{\partial W}$$
$$B = B - \alpha \frac{\partial J}{\partial B}$$
- 여기서 $\alpha$는 학습률(Learning Rate)을 뜻하며,
- $\frac{\partial J}{\partial W}$는 가중치에 대한 비용 함수의 미분 값을 의미합니다.
- $\frac{\partial J}{\partial B}$는 편향에 대한 비용 함수의 미분 값입니다.
- 위 과정을 계속 반복해서 모델이 점점 더 정확하게 예측할 수 있도록 학습해줍니다.
✨ 소프트맥스 회귀가 신경망이라구?
- 소프트맥스 회귀는 사실상 입력층에서부터 출력층으로 구성된 단순한 신경망 모델입니다.
- 위의 붓꽃 분류 문제에서도 보면, 입력층은 4개의 특성 (꽃받침 길이, 넓이, 꽃잎 길이, 넓이),
- 출력층은 3개의 클래스 (setosa, versicolor, virginica),
- 활성화 함수는 소프트맥스(Softmax)로 다음과 같이 표현되기 때문에,
$$ softmax(WX + B) = \hat{y} $$
- 즉, 내일 배울 다층 퍼셉트론(MLP, Multi-Layer Perceptron)에서 은닉층이 없는 가장 단순한 형태의 신경망으로 볼 수 있습니다.
🤔 31일차 회고
- 유사도를 처음 배운 것도 아닌데 코사인 유사도가 유클리드 거리보다 좀 더 나은 척도였다는 것을 이제야 알다니... 이래서 사람은 꾸준히 공부를 해야하나 봅니다.
- 그리고 머신러닝 들어와서 분류나 회귀 관련해서도 keras에서 제공하는 다양한 함수들도 기존에는 많이 알고 있었는데,
- 또 이제와 다시 보니 많이 까먹었더라구요 😢 깊게 공부하며 다시 한 번 파야겠습니다.
- 어제 오늘 정말 와다다 달려서 그런지 살짝 지치기도 하지만, 내일 딥러닝까지 배우고 나면 할 수 있는 범위가 넓어져서 더욱 기대가 되는 요즘입니다.
- 프로젝트도 슬슬 준비 중에 있는데, 가지각색으로 아이디어가 나오고 있어서 이번 프로젝트도 한 번 기깔나게 성공시켜보겠습니다!
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 형태가 바뀌면 의미도 바뀔까? (0) | 2025.03.17 |
|---|---|
| 🤔 이번엔 좀 더 깊게 달려보자 (3) | 2025.03.13 |
| 🤔 Words In My Bag (8) | 2025.03.11 |
| 🤔 자연어를 전처리해보자 (7) | 2025.03.07 |
| 🤔 자연어를 처리해보자 (6) | 2025.03.06 |