

- 오늘은 SOYNLP, 여러 언어 모델, 그리고 BoW, DTM, TF-IDF에 대한 이론들을 배우고 관련 실습(WordCloud 생성)도 진행했습니다.
🎁 한국어 전처리 패키지
✨ SOYNLP를 이용해서 단어 토큰화하기
- SOYNLP는 비지도 학습 기반의 단어 토크나이저로, 형태소 분석기와 달리 사전에 등록되지 않은 단어(신조어 등)도 효과적으로 처리할 수 있게 해주는 패키지입니다.
💡 기존 형태소 분석기의 한계는?
- 일반적인 형태소 분석기는 신조어나 미등록 단어를 정확하게 구분하지 못하는 경우가 대부분입니다.
- 예를 들면, 저번에 사용했던 Okt 형태소 분석기를 사용하게 된다면 다음과 같은 결과가 나옵니다.
from konlpy.tag import Okt
tokenizer = Okt()
print(tokenizer.morphs('에이비식스 이대휘 1월 최애돌 기부 요정'))
# ['에이', '비식스', '이대', '휘', '1월', '최애', '돌', '기부', '요정']
💡 SOYNLP의 원리와 장점
- 그래서 SOYNLP는 응집 확률(cohesion probability)과 브랜칭 엔트로피(branching entropy)라는 것을 활용해서 단어를 학습하게 되는데,
- 여기서 응집 확률은 특정 문자 시퀀스가 함께 자주 등장하면 하나의 단어로 판단하는 것이고,
- 브랜칭 엔트로피는 특정 문자 시퀀스 앞뒤로 등장하는 단어가 다양하면 독립적인 단어로 인식하는 것입니다.
- 예를 들어서 '에이비식스'가 자주 등장하면서, 앞뒤로 독립적인 단어(최고, 가수, 실력 등)가 함께 나타난다면, 이를 하나의 단어로 인식하는 것입니다.
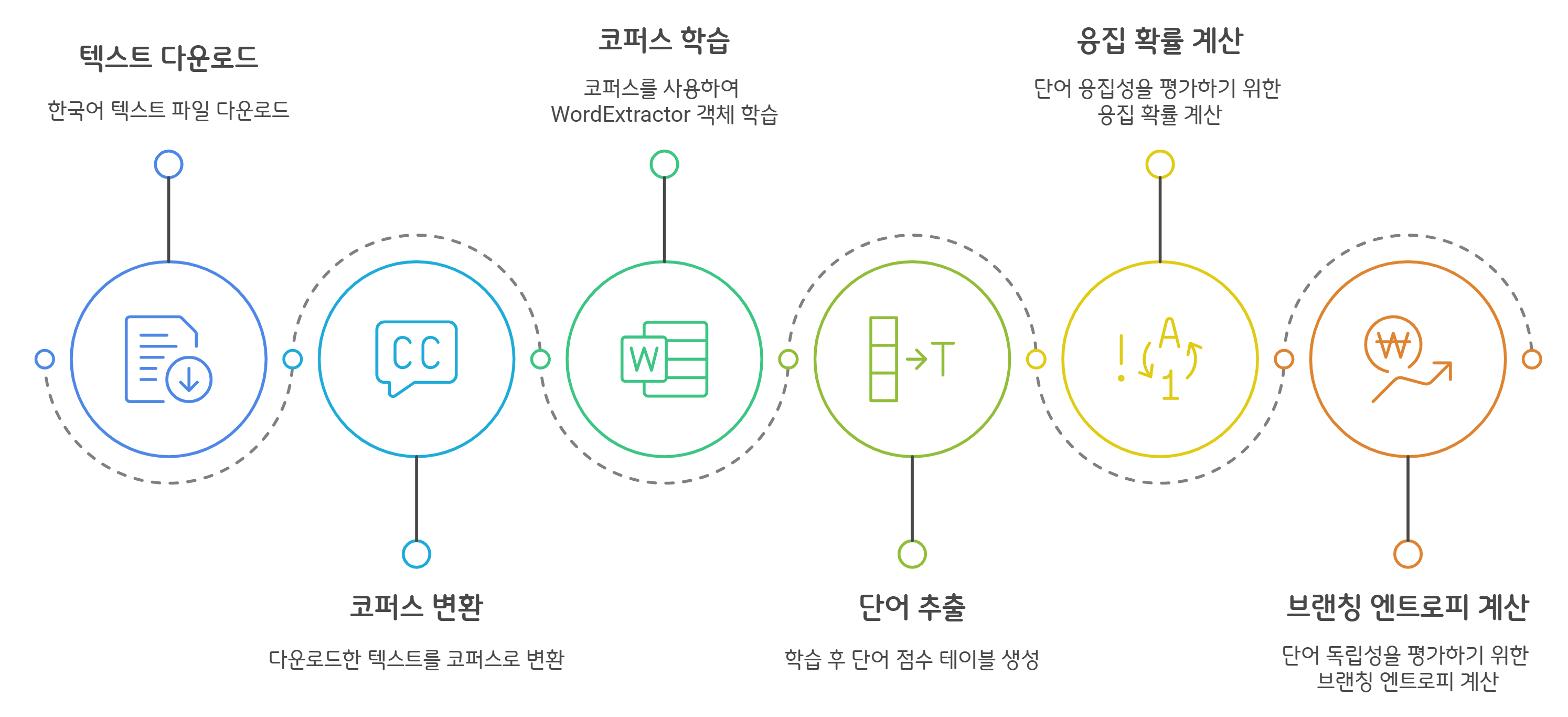
✨ SOYNLP 단어 토크나이저 학습 과정
- SOYNLP는 기존의 형태소 분석기와 달리, 데이터에서 직접 단어를 학습하는 방식을 사용합니다.
- 그래서 먼저 한국어 문장(코퍼스)들을 준비하고, 이를 분석해서 단어 점수표를 생성하는 과정이 필요합니다!
💡 학습할 데이터(코퍼스) 준비
- SOYNLP는 학습을 통해 단어를 학습하는 구조이기 때문에, 먼저 인터넷에 공개된 텍스트 데이터를 활용하려고 합니다.
- 다음과 같이 여러 패키지와 클래스를 사용해서 진행해보았습니다!
- urllib.request.urlretrieve()를 사용하여 한국어 텍스트 파일을 다운로드하고,
- DoublespaceLineCorpus()를 사용하여 코퍼스로 변환한 뒤,
- len(corpus)를 출력하여 전체 문장 개수를 확인하자!
- 결과적으로 총 30,091개의 문장으로 이루어진 코퍼스가 준비되었고,
- 결과를 쭈욱 확인해보면, 뉴스 기사 형태의 텍스트를 가져왔고, 그 안에 신조어나 복합 명사도 존재했습니다.
💡 단어 점수표 학습
- SOYNLP를 사용하여 코퍼스를 학습해서 단어 점수표(Word Score Table)를 생성할 수 있습니다.
- 이 과정에서 응집 확률과 브랜칭 엔트로피를 활용해 단어를 학습한답니다!
- 먼저, WordExtractor() 객체를 생성하고,
- train() 함수를 호출하여 전체 코퍼스를 학습한 뒤,
- extract()를 호출하여 단어 점수표를 생성합니다.
training was done. used memory 0.817 Gb
all cohesion probabilities was computed. # words = 223348
all branching entropies was computed # words = 361598
all accessor variety was computed # words = 361598
- 결과적으로, 학습에 약 0.8GB의 메모리를 사용해서 학습을 진행했고, 총 36만 개 정도의 단어 후보가 생성되었음을 확인했습니다.
- 응집 확률, 브랜칭 엔트로피, accessor variety 등의 값이 같이 계산되어 출력되는 것을 알 수 있습니다.
✨ 그럼 응집 확률이 뭐지?
- 응집 확률은 문자열 내에서 특정 문자 시퀀스가 얼마나 자주 함께 등장하는지를 평가하는 척도입니다.
- 특정 문자열이 하나의 단어로 등장할 가능성이 높을수록 응집 확률이 증가하고,
- 문자열을 왼쪽부터 순차적으로 확장하면서, 다음 문자가 등장할 확률을 계산 후, 누적 곱한 값을 사용합니다.
- 즉, 응집 확률이 높을수록 해당 문자 시퀀스는 하나의 단어로 간주될 가능성이 커지게 됩니다.
💡 응집 확률 계산 방식
$$ cohesion(n) = \left( \prod_{i=1}^{n-1} P(c_{1:i+1} | c_{1:i}) \right)^{\frac{1}{n-1}} $$
- 여기서 $P(c_{1:i+1} | c_{1:i})$에 해당하는 부분은 앞부분 문자열 $c_{1:i}$가 주어졌을 때, 그 다음 문자가 나올 확률을 의미합니다.
- 마지막으로 누적으로 곱을 구한 후, (n−1) 제곱근을 취해서 정규화하게 됩니다.
- 예를 들어서 "반포한강공원에"(7글자)라는 문자열이 있다고 할 때, 응집 확률을 계산하는 과정은 다음 식으로 진행됩니다.
$$ cohesion(7) = \sqrt[6]{ P(\text{반포}|\text{반}) \cdot P( \text{반포한}| \text{반포}) \cdot P( \text{반포한강}| \text{반포한}) \cdots P( \text{반포한강공원에}| \text{반포한강공원})} $$
💡 "반포한강공원에"의 응집 확률 분석
- SOYNLP의 단어 점수표에서 응집 확률을 확인하면 다음과 같은 결과가 나옵니다.
| 문자열 | 응집 확률 |
| 반포한 | 0.0884 |
| 반포한강 | 0.1984 |
| 반포한강공 | 0.2973 |
| 반포한강공원 | 0.3789 (최대값) |
| 반포한강공원에 | 0.3349 |
- 결과적으로 "반포한" - "반포한강" - "반포한강공"으로 확장될수록 응집 확률이 증가하는 것을 볼 수 있었고,
- 여기서 "반포한강공원"에서 최대 응집 확률을 기록했다는 건 “반포한강공원”이 하나의 단어로 인식될 가능성이 가장 높다는 뜻으로 볼 수 있습니다.
- 조사("에")가 붙으면서 응집 확률이 감소한 것을 보니, "반포한강공원에"는 조사가 포함된 문장이므로 단어로 보기 어렵다는 뜻입니다.
- 따라서, "반포한강공원"이 하나의 단어로 판단되기에 가장 적합한 문자열이라고 생각할 수 있겠습니다!
✨ 브랜칭 엔트로피는 또 뭐지?
- 브랜칭 엔트로피(Branching Entropy)는 확률 분포의 엔트로피 값을 사용해서 주어진 문자열에서 다음 문자가 얼마나 다양하게 등장할 수 있는지를 측정하는 척도입니다.
- 쉽게 말하면, 특정 문자 시퀀스 다음에 올 수 있는 문자 종류가 많을수록 브랜칭 엔트로피 값이 크게 되고, 특정 문자 시퀀스 다음에 올 문자가 명확할수록 브랜칭 엔트로피 값이 작습니다.
- 그래서 하나의 단어가 끝나는 지점에서는 브랜칭 엔트로피가 다시 증가하는 경향을 보입니다.
- 개념만 들으면 이해가 안 될 수도 있으니, 예제를 한 번 살펴보시죠.
💡 브랜칭 엔트로피 예제
- 살짝 스무고개랑 비슷한데,
- 첫 번째 문자가 "디"라면, 다음 문자가 무엇인지 예측하기 어렵죠. (디지털, 디스코, 디스크 등 다양한 가능성이 존재하니깐!)
- 두 번째 문자가 "디스"라고 해도, 여전히 다양한 단어가 올 수 있습니다. (디스코드, 디스플레이, 디스카운트 등)
- 세 번째 문자로 "디스플"까지 나오면 이제는 거의 확실하게 "디스플레이"로 이어질 가능성이 높습니다.
- 네 번째 문자가 "디스플레”면, 누가 봐도 다음 글자는 확실하게 "이"일 가능성이 높죠!
- 즉, 단어가 점점 완성될수록 다음 글자 예측이 쉬워지므로 브랜칭 엔트로피가 감소하는 경향을 보이게 됩니다.
- 이제 엔트로피 값을 한 번씩 확인해보겠습니다.
| 문자열 | 브랜칭 엔트로피 |
| "디" | 2.6852 |
| "디스" | 1.6372 |
| "디스플" | -0.0 |
| "디스플레" | -0.0 |
| "디스플레이" | 3.1400 |
- "디스플레이"에서 3.14의 값이 나타났다는 것은, 단어가 끝난 후에는 조사나 다른 단어가 올 수 있으므로 엔트로피 값이 다시 증가한다는 것을 의미합니다.
- 즉, 단어가 점점 완성될수록 브랜칭 엔트로피 값이 감소하다가, 단어가 끝나는 순간 다시 증가합니다!
- 이런 브랜칭 엔트로피는 문장 내에서 단어 경계를 찾는 데 활용할 수도 있고,
- 미등록 단어(신조어)도 단어 경계를 자동으로 판단할 수 있게 됩니다.
✨ L 토크나이저?
- L 토크나이저는 한국어에서 어절을 두 개의 토큰(L + R)으로 분리하는 방식의 토크나이저입니다.
- 일반적으로 한국어의 어절은 핵심 단어(L) + 조사 또는 접사(R)의 형태를 가지기 때문에
- L 토크나이저는 가장 적절한 L 토큰을 찾아 어절을 분리하는 방식을 사용하게 됩니다.
💡 L 토크나이저의 동작 원리
- L 토크나이저는 SOYNLP의 응집 확률 점수를 활용해서 우선 가장 적절한 L 토큰을 결정합니다.
- 그리고는 어절을 L(왼쪽) + R(오른쪽) 형태로 분리해주는데,
- 이때, L 토큰의 점수가 높은 경우, 해당 부분을 단어로 간주하고 R 토큰과 분리하게 됩니다.
💡 L 토크나이저 예제
- SOYNLP를 활용한 코드로 잠깐 살펴보겠습니다.
from soynlp.tokenizer import LTokenizer
# 단어별 응집 확률 점수 계산
scores = {word: score.cohesion_forward for word, score in word_score_table.items()}
# L 토크나이저 초기화
l_tokenizer = LTokenizer(scores=scores)
# 문장 토큰화
tokens = l_tokenizer.tokenize("국제사회와 우리의 노력들로 범죄를 척결하자", flatten=False)
print(tokens)
# [('국제사회', '와'), ('우리', '의'), ('노력', '들로'), ('범죄', '를'), ('척결', '하자')]- L 토크나이저는 위처럼 몇 가지 이점이 존재하는데,
- 위 코드처럼 어절을 자연스럽게 분리할 수 있습니다.
- 기존 형태소 분석기(Okt 같은 것들)보다 자연스러운 단어 단위의 분리가 가능하고,
- 조사(R)까지도 따로 분리할 수 있어 형태소 분석보다 더 간단한 분석도 가능해집니다.
- 또, 다양한 한국어 데이터 처리에 활용할 수도 있습니다.
- 신조어나 복합 명사를 포함한 문장에서 핵심 단어를 효과적으로 추출할 수 있고, 자연어 처리에서 어절 단위로 분석할 때 유용하게 사용할 수 있습니다.
✨ 최대 점수 토크나이저도 있는데요
- 최대 점수 토크나이저(Max Score Tokenizer)는 띄어쓰기가 없는 문장에서 점수가 높은 글자 시퀀스를 순차적으로 찾아내는 토크나이저입니다.
- 한국어는 띄어쓰기가 중요한 언어지만, SNS나 채팅에서는 띄어쓰기가 잘 지켜지지 않는 경우가 굉장히 많습니다. (저의 경우에도...)
- 기존의 형태소 분석기는 띄어쓰기가 되어 있지 않으면, 단어를 올바르게 인식하지 못하는 반면에
- SOYNLP의 최대 점수 토크나이저는 점수를 기반으로 가장 적절한 단어 시퀀스를 찾아서 분리해주는 역할을 합니다.
💡 얘는 어떻게 동작하는감
- 먼저 아까 썼던 SOYNLP의 단어 점수표(응집 확률 점수)를 활용해서 각 문자 시퀀스의 점수를 평가해줍니다.
- 띄어쓰기가 없는 문장에서 점수가 가장 높은 단어 시퀀스를 우선적으로 선택해주고,
- 선택된 단어를 문장에서 제거 후에 남은 문자열에서 다시 단어를 선택해줍니다.
- 이 과정을 반복하면서 문장을 토큰화하는 것입니다. 예를 들면 아래처럼 진행됩니다.
💡 최대 점수 토크나이저 예제
from soynlp.tokenizer import MaxScoreTokenizer
# 단어별 응집 확률 점수 계산
scores = {word: score.cohesion_forward for word, score in word_score_table.items()}
# 최대 점수 토크나이저 초기화
maxscore_tokenizer = MaxScoreTokenizer(scores=scores)
# 띄어쓰기가 없는 문장 토큰화
tokens = maxscore_tokenizer.tokenize("국제사회와우리의노력들로범죄를척결하자")
print(tokens)
# ['국제사회', '와', '우리', '의', '노력', '들로', '범죄', '를', '척결', '하자']- 이런 최대 점수 토크나이저는 SNS, 채팅, 댓글 등에서 띄어쓰기가 잘 지켜지지 않은 문장을 처리할 때 유용하게 사용됩니다.
- 기존의 형태소 분석기는 띄어쓰기가 없거나 신조어가 포함되면 정확도가 떨어지지만, SOYNLP의 최대 점수 토크나이저는 점수를 기반으로 단어를 찾아내므로 유연하게 동작할 수 있어서
- 띄어쓰기 교정 시스템, 텍스트 분석, 검색 엔진 등에 사용할 수도 있겠습니다.
✨ 반복 문자를 정제해보자!
- 한국어 텍스트 데이터(SNS, 채팅, 댓글 등)에서는 특정 문자나 이모티콘이 과도하게 반복되는 경우가 많이 있습니다.
- 예를 들면, 카카오톡에서 웃을 때 보통 "ㅋㅋ", "ㅋㅋㅋ", "ㅋㅋㅋㅋㅋㅋ", "ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ"를 많이 사용하고,
- 울 때는 "ㅠㅠㅠㅠㅠㅠ"같은 표현을 쓴다든지, "하하하하하핫"과 같이 반복해서 쓰는 경우도 있죠.
- 이러한 반복을 모두 다른 단어로 처리하는 것은 불필요하기 때문에, 정제해서 동일한 형태로 변환하는 것이 효율적입니다.
💡 반복 문자 정규화 기능
- SOYNLP는 불필요하게 반복되는 문자들을 일정 횟수로 제한해서 정규화를 시켜줄 수 있습니다.
- 이모티콘 정규화(emoticon_normalize)같은 경우에는 ㅋㅋ, ㅠㅠ 같은 감정 표현도 정리해주고,
- 일반적인 문자 반복 정규화(repeat_normalize)에서는 "하하하하핫" 같은 반복되는 표현을 정리해줍니다. 각각의 예시를 잠깐 보겠습니다.
💡 이모티콘 정규화 예제
from soynlp.normalizer import emoticon_normalize
print(emoticon_normalize('앜ㅋㅋㅋㅋ이영화존잼쓰ㅠㅠㅠㅠㅠ', num_repeats=2))
print(emoticon_normalize('앜ㅋㅋㅋㅋㅋㅋㅋㅋㅋ이영화존잼쓰ㅠㅠㅠㅠ', num_repeats=2))
# 아ㅋㅋ영화존잼쓰ㅠㅠ
# 아ㅋㅋ영화존잼쓰ㅠㅠ
- "ㅋㅋㅋㅋㅋㅋ"가 "ㅋㅋ"로 정규화되었고, "ㅠㅠㅠㅠㅠㅠ"도 "ㅠㅠ"로 정규화되었습니다.
- 보통 영화의 댓글을 정제할 때 주로 사용되는데, 이 이모티콘 정규화는 문장의 의미는 유지하면서 불필요한 반복을 깔끔히 제거해줍니다.
💡 반복 문자 정규화 예제
from soynlp.normalizer import repeat_normalize
print(repeat_normalize('하하하하하하핫', num_repeats=2))
print(repeat_normalize('하하하하핫', num_repeats=2))
# 하하핫
# 하하핫- "하하하하하하핫"이 "하하핫"으로 정규화됩니다. num_repeats를 늘리면 더 늘어날 수도 있겠죠.
- 이 repeat_normalize 함수를 사용하면, 동일한 의미는 유지하면서 불필요한 반복은 축소해줄 수 있습니다.
🌟 사용자 사전을 추가해서 형태소 분석을 개선해보자!
- 전에도 수차례 얘기드린 바로, 영어는 띄어쓰기만으로도 단어가 명확히 분리되지만, 한국어는 형태소 단위로 분석해야 하기 때문에 띄어쓰기만으로는 단어를 구분하기 어려운 경우가 많습니다.
- 예를 들면 특정 단어(이름, 브랜드명)가 담겨있는 문장을 형태소 분석하면 예상치 못한 결과가 나올 수도 있는 것입니다.
- 위와 같은 예를 방지하기 위해서 특정 단어를 하나의 단어로 인식할 수 있게 형태소 분석기한테 알려줄 필요가 있겠죠!
- 이러한 문제를 해결하기 위해 나온 것이 바로 사용자 사전을 추가하는 방식입니다.
- 이 방법은 기존 형태소 분석기로 진행하게 되면, 방법이 복잡한 경우가 많기 때문에, Customized KoNLPy를 사용해서 쉽게 사용자 사전을 추가할 수 있습니다.
✨ Customized KoNLPy를 이용해서 사용자 사전 추가하기
- 사용자 사전을 추가하여 "길동이"(특정 사람의 이름)를 하나의 단어로 등록할 때는 간단하게 add_dictionary 함수를 사용합니다.
twitter.add_dictionary('길동이', 'Noun')
# 사용자 사전 추가 후 다시 형태소 분석 실행
print(twitter.morphs('길동이는 사무실로 갔습니다.'))
📖 언어 모델
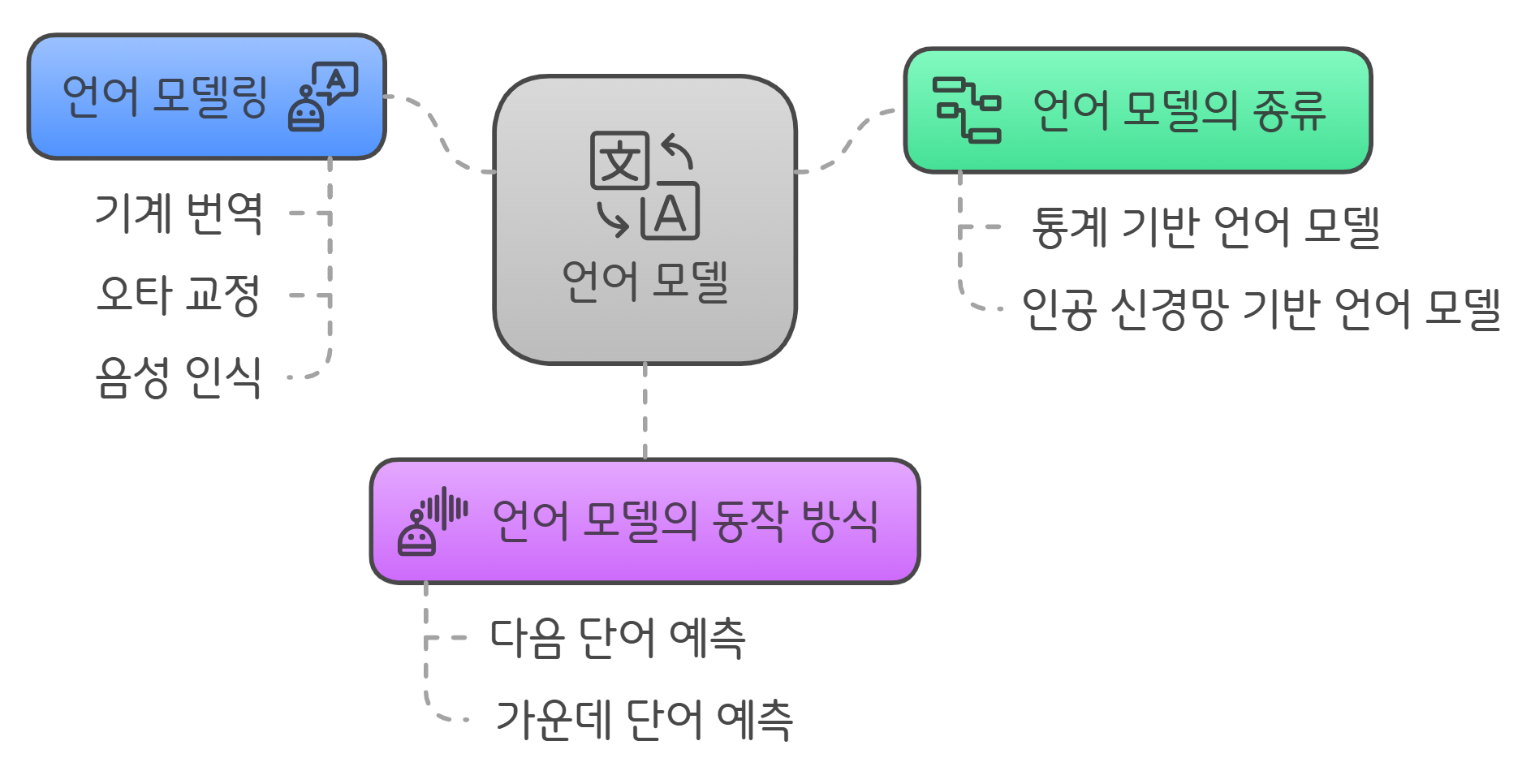
- 언어 모델(Language Model, LM)은 단어 시퀀스(문장)에 확률을 할당하는 모델입니다.
- 즉, 주어진 문장이 얼마나 자연스럽고 적절한지 판단하는 것이 언어 모델의 역할입니다.
- 언어 모델의 성능이 뛰어날수록 기계는 사람처럼 자연스러운 문장과 부자연스러운 문장을 구별할 수 있게 됩니다.
✨ 언어 모델의 종류
- 언어 모델은 크게 두 가지 방식으로 구분되는데, 다음처럼 분류됩니다.
| 언어 모델 유형 | 방법론 | 특징 |
| 통계 기반 언어 모델 | 확률과 통계를 기반으로 한 방식 | 전통적, 비교적 간단하지만 성능에 한계 있음 |
| 인공 신경망 기반 언어 모델 | 딥러닝(인공 신경망)을 이용한 방식 | 복잡한 언어 구조 이해에 뛰어난 성능 |
- 최근에는 인공 신경망 기반 언어 모델(딥러닝 기반)이 더 좋은 성능을 보이고,
- 특히, 최근에 주목받는 GPT, BERT와 같은 모델들이 모두 신경망 기반의 언어 모델을 사용합니다.
💡 통계 기반 언어 모델 (Statistical Language Model, SLM)
- 여기서 통계 기반 언어 모델은 전통적인 방식으로, 단어들의 빈도 및 확률 계산을 이용해서 다음 단어를 예측하거나 문장의 적절성을 평가해주는 모델입니다.
- 단순하고 직관적이지만, 복잡한 문맥을 이해하거나 언어의 미묘한 특징을 표현하는 데는 몇 가지 한계가 존재합니다.
✨ 언어 모델의 동작 방식
- 언어 모델이 문장에 확률을 부여하는 가장 일반적인 방식은 다음 두 가지로 구분됩니다.
💡 다음 단어를 예측하는 모델
- 이전에 등장한 단어들이 주어졌을 때, 다음에 올 단어를 예측하는 방식입니다.
- 예를 들어서, "오늘 날씨가 정말 ___"라는 문장이 들어오게 되면, 모델은 "좋네요"라는 단어를 높은 확률로 예측하게 됩니다.
- 이런 모델에는 우리가 익히 알고 있는 GPT 모델이 대표적입니다.
💡 가운데 단어 예측 모델 (빈칸 추론 방식)
- 문장의 양쪽 문맥이 주어졌을 때, 가운데 비어있는 단어를 예측하는 방식입니다.
- 위의 예를 다시 들어보면, "오늘 날씨가 ___ 좋네요."라는 문장에서 모델은 "정말"이라는 단어를 예측하게 됩니다.
- 고등학교 수험 시험의 빈칸 추론 문제와 비슷하다고 보시면 되고, 대표적인 모델로는 BERT가 있습니다.
✨ 언어 모델링 (Language Modeling)
- 언어 모델링이란, 주어진 단어 시퀀스(문맥)로부터 아직 모르는 단어를 예측하는 작업입니다.
- 대부분의 언어 모델은 이전 단어들에서 다음 단어를 예측하는 방식으로 모델링을 수행하는데, 이 언어 모델링은 자연어 처리에서 핵심적인 역할을 해줍니다.
💡 단어 시퀀스에 확률을 할당하는 언어 모델
- 기계 번역(Machine Translation)
- P(나는 버스를 탔다) > P(나는 버스를 태운다)
- 두 문장 중 어떤 문장이 더 자연스러운지 확률을 통해 결정하기도 하고,
- 오타 교정(Spell Correction)
- P(선생님이 교실로 부리나케 달려갔다) > P(선생님이 교실로 부리나케 잘려갔다)
- 잘못된 단어보다 자연스러운 단어를 선택하기도 합니다.
- 음성 인식(Speech Recognition)
- P(나는 메롱을 먹는다) < P(나는 메론을 먹는다)
- 음성 인식에서는 발음이 비슷한 단어들 중에서 문맥상 적절한 단어를 판단해주기도 합니다.
💡 단어 시퀀스의 확률 표현
- 언어 모델에서 단어 시퀀스(문장)는 확률로 표현됩니다.
- 예를 들어서 단어 시퀀스 $W = (w_1, w_2, w_3, ..., w_n)$의 확률은 다음과 같이 표현합니다.
$$ P(W) = P(w_1, w_2, w_3, w_4, w_5, \dots, w_n) $$
- 하지만 실제로 이 확률을 구할 때는 조건부 확률을 사용해서 구합니다! (이번엔 수학 시간인가...)
💡 조건부 확률을 사용해서 단어 시퀀스의 확률 계산
- 다음 단어를 예측하는 확률을 표현할 때 조건부 확률을 사용하는데, 아래처럼 표현합니다.
$$ P(w_n \mid w_1, w_2, \dots, w_{n-1}) $$
- 예를 들어, 5번째 단어의 확률을 표현하면 $P(w_5 \mid w_1, w_2, w_3, w_4)$이고,
- 이것은 앞서 등장한 4개의 단어가 주어졌을 때, 5번째 단어가 나올 확률을 의미합니다.
- 결국 전체 단어 시퀀스 $W$의 확률은 모든 단어들의 조건부 확률을 곱한 형태로 나타낼 수 있는 것입니다.
$$ P(W) = P(w_1, w_2, w_3, \dots, w_n) = \prod_{i=1}^{n}P(w_i \mid w_1, \dots, w_{i-1}) $$
- 즉, 단어 시퀀스의 확률은 각 단어가 주어진 이전 단어들로부터 등장할 확률의 곱으로 표현됩니다.
💡 다음 단어를 예측한다는 것은?
"비행기를 타려고 공항에 갔는데 지각을 하는 바람에 비행기를 [?]"
- 이 문장에서 "[?]" 부분에 들어갈 단어를 예측해본다면,
- 사람들은 쉽게 "놓쳤다"라는 단어를 예상하겠지만, 이것은 사람의 상식과 경험에 기반한 판단이라고 볼 수 있습니다.
- 기계도 마찬가지로 이렇게 작동하는데요. 먼저 기계는 앞에 등장한 단어들("비행기를 타려고 공항에 갔는데 지각을 하는 바람에 비행기를")을 분석합니다.
- 그리고 이 앞의 단어들을 조건으로 다음 단어가 등장할 확률을 예측합니다.
- 후보 단어들("놓쳤다", "먹었다", "탔다" 등)의 등장 확률을 각각 계산하고, 여기서 가장 높은 확률을 가진 단어를 선택합니다.
- 즉, 언어 모델은
- 이전 단어들을 분석해서
- 다음 단어가 등장할 확률을 추정하고,
- 가장 높은 확률의 단어를 선택하여 문장을 완성하는 방식으로 동작하는 것입니다.
✨ 통계적 언어 모델 (Statistical Language Model, SLM)
💡 먼저 조건부 확률! 좀 더 자세히 보자
- 조건부 확률은 어떤 사건이 일어났을 때 다른 사건이 일어날 확률을 나타냅니다.
$$P(B|A) = \frac{P(A,B)}{P(A)}$$
- 위 식의 의미는 사건 A가 발생한 상태에서 사건 B가 발생할 확률을 나타낸 것입니다.
- 앞서 설명했듯이 단어 시퀀스의 확률을 계산할 때, 앞의 단어가 주어졌을 때 다음 단어가 등장할 확률을 구하는 데 사용합니다.
- 예를 들어, 4개의 사건 A, B, C, D의 연속된 조건부 확률은?
$$ P(A, B, C, D) = P(A) \times P(B|A) \times P(C|A, B) \times P(D|A, B, C) $$
💡 SLM은 어떻게 동작할까?
- 통계적 언어 모델은 단어의 등장 빈도(카운트)를 기반으로 확률을 계산하는 방식을 취합니다.
- 이전에 나타난 단어들이 주어졌을 때 다음 단어의 등장 빈도를 기반으로 확률을 계산하는 것입니다.
- 예를 들면, 학습한 코퍼스 데이터에서 "An adorable little boy"가 100번 등장했다고 가정하고,
- 이 중에서 그 다음 단어로 "is"가 30번 등장했다면, 조건부 확률은 다음과 같이 계산할 수 있겠죠!
$$ P(\text{is}|\text{An adorable little boy}) = \frac{\text{count(An adorable little boy is)}}{\text{count(An adorable little boy)}} = \frac{30}{100} = 0.3 $$
- 즉, "An adorable little boy"라는 문맥이 주어졌을 때 "is"가 나올 확률은 30%로 계산됩니다.
😢 희소 문제 (Sparsity Problem)
- SLM은 단어의 등장 빈도를 통해 확률을 계산하기 때문에 충분한 데이터가 없으면 정확한 확률을 구할 수 없는 문제가 발생할 수도 있습니다.
- 학습 데이터에서 "An adorable little boy is"라는 시퀀스가 전혀 없었다면, 이 단어 시퀀스의 확률은 0이 되버리고,
- 마찬가지로 "An adorable little boy"라는 시퀀스가 아예 없다면, 확률 자체가 정의되지 않습니다(분모가 0이 되기 때문에).
💡 이런 희소 문제 해결을 위해서는?
- 희소 문제를 완화하기 위해서 언어 모델에서는 n-gram 언어 모델과 같은 기법을 사용합니다.
- n-gram은 앞에 등장한 n-1개 단어만 사용하여 다음 단어의 확률을 추정하는 방식인데요.
- 전체적인 문맥을 사용하지 않고 제한된 몇 개의 단어만을 사용해서 계산하기 때문에 희소 문제를 완화시킬 수 있습니다.
- 하지만 여전히 근본적인 해결책은 아니기 때문에 최근에는 SLM보다 인공 신경망 기반 모델로 넘어가는 중이라고 합니다.
✨ N-gram 언어 모델은?
- N-gram이란, 아까도 설명했듯, 다음 단어가 무엇인지 예측할 때 이전에 나온 모든 단어를 보는 대신,
- 최근 등장한 일부 단어(n개)만 보고 다음 단어를 예측하는 방법입니다. 여기서 'n'은 고려하는 단어의 개수를 의미합니다.
- 다음 단어가 무엇인지 예측할 때 전체 문장을 볼 수도 있지만, 실제로는 일부 단어만 보는 것이 더 효율적이고 현실적입니다.
- 왜냐하면 너무 긴 단어 시퀀스는 실제 코퍼스(corpus)에 거의 등장하지 않아서 카운트하기가 어렵기 때문인데요.
- 긴 문장을 사용할수록 정확한 예측이 가능할 것 같지만, 실제로는 데이터가 희소해져서 빈도수를 카운트하기 어려워집니다. 따라서 N-gram처럼 몇 단어만 사용하여 근사시키는 것이 좋다고 봅니다.
💡 N-gram의 여러 가지 종류
- 문장이 "An adorable little boy is spreading smiles."와 같이 주어졌을 때,
- Unigrams(1-gram)은 An, adorable, little, boy, is, spreading, smiles를 뜻하고,
- Bigrams(2-gram)은 An adorable, adorable little, little boy, boy is, is spreading, spreading smiles처럼 두 개씩 묶은 형태를 뜻하며,
- Trigrams (3-gram)은 An adorable little, adorable little boy, little boy is, boy is spreading, is spreading smiles와 같이 3개의 단어를 묶어 표현하게 됩니다.
- N-gram에서 n이 커질수록 더 많은 앞 단어들을 참고하기 때문에 문장의 맥락을 더 잘 포착할 수 있습니다.
💡 N-gram 성능 지표 (Perplexity)
- N-gram 모델의 성능은 퍼플렉서티(Perplexity)라는 값으로 측정하는데 이 수치가 작을수록 성능이 좋다는 의미입니다.
- n이 증가할수록 perplexity 값이 낮아지고, 성능이 향상된다는 것을 확인할 수 있었습니다.
💡 N-gram의 한계
- 이 N-gram도 결국 n이 커지게 되면 희소 문제가 발생할 수도 있습니다!
- 또한, n을 너무 크게 잡으면 데이터 부족으로 정확한 확률을 추정하기 어려워지고, 모델의 크기도 커지기 때문에 Trade-off 문제가 발생할 수 있습니다. 일반적으로 n은 5 이하로 제한하는 것이 권장됩니다.
💡 도메인에 맞는 코퍼스를 수집하자!
- 어떤 분야(Domain)인지, 어떤 애플리케이션(Application)인지에 따라 특정 단어들의 확률 분포는 달라집니다.
- 마케팅 관련 데이터에서는 광고, 소비자와 같은 단어가 빈번하게 등장하고, 의료 분야에서는 진단(diagnosis), 치료(treatment) 등의 단어가 주를 이루는 것처럼 말이죠!
- 따라서 해당 도메인에 맞는 코퍼스를 사용하면, 모델이 더 정확한 언어를 생성해줄 수 있습니다.
✨ 인공 신경망 기반 언어 모델 (Neural Network-Based Language Model)
- 위에서 살펴봤던 N-gram 언어 모델은 몇 가지 한계를 가지고 있기 때문에, 이를 해결하기 위해서 인공 신경망(Neural Network)을 활용한 언어 모델들이 등장했습니다.
💡N-gram 모델 개선 방법
- N-gram에서의 희소 문제나 Trade-off 문제를 개선하기 위해서 확률 계산을 진행할 때 일반화 기법을 적용해서 데이터 부족 문제를 일부 해결할 수 있었고,
- 분모와 분자에 작은 숫자를 추가하여 확률 값이 0이 되는 문제도 방지할 수 있습니다.
💡 신경망 기반 모델의 장점
- 그러나 이런 방식으로도 근본적인 한계를 해결하기 어려웠고, 현재는 딥러닝 기반 언어 모델이 N-gram보다 우수한 성능을 보이게 되었습니다.
- RNN(Recurrent Neural Network), LSTM(Long Short-Term Memory), Transformer 모델(BERT, GPT 등)이 그 예시가 되겠고,
- 이러한 신경망 모델들은 문맥을 더 깊이 이해할 수 있어서 N-gram의 단순 접근 방식보다 더 정교한 언어 처리가 가능합니다.
✨ 한국어에서의 언어 모델
- 한국어는 영어나 다른 언어에 비해 언어 모델이 다음 단어를 예측하기 어려운 특징 몇 가지가 있는데요.
- 첫째는 어순의 자유로움입니다.
- 한국어는 어순이 상대적으로 자유로워, 문장 내 단어의 순서가 바뀌어도 의미가 전달됩니다.
- 심지어 주어가 생략되어도 문장이 성립할 때도 있기 때문에, 이러한 특성으로 확률 기반 언어 모델이 다음 단어를 예측하는 것이 어려울 수 밖에 없죠...
- 두번째는 저번에도 얘기했듯, 교착어의 특성 때문입니다.
- 한국어는 교착어로, 단어에 조사와 접사가 붙어서 문법적인 의미를 형성합니다.
- 그래서 띄어쓰기 단위(어절)로 토큰화를 할 경우, 가능한 단어의 수가 엄청나게 불어날 수도 있습니다.
- 따라서 한국어에서 언어 모델을 학습할 때는 조사를 분리하는 것이 중요한 전처리 과정 중에 하나입니다.
- 마지막은 띄어쓰기의 불규칙성입니다.
- 한국어는 띄어쓰기가 제대로 지켜지지 않아도 의미가 전달되며, 띄어쓰기 규칙이 상대적으로 복잡하기도 합니다.
- 이로 인해서 실제 한국어 코퍼스에서는 띄어쓰기가 지켜지지 않은 데이터가 많아, 토큰화가 제대로 되지 않는 문제가 발생하기도 합니다.
- 잘못된 토큰이 훈련 데이터로 사용될 경우에 언어 모델의 성능이 저하될 가능성이 큽니다.
✨ PPL로 언어 모델 평가하기! (그 PPL 아님)
- 퍼플렉시티(Perplexity, PPL)는 언어 모델을 평가하는 지표로, 일반적으로 낮을수록 성능이 좋은 모델임을 의미합니다.
- 영어에서 'perplexed'는 '헷갈리는'이라는 의미를 가지고, 그래서 PPL은 모델이 얼마나 "헷갈려하는지"를 수치화한 것이라 볼 수 있습니다.
- PPL은 문장의 길이로 정규화된 문장 확률의 역수로 정의됩니다.
- 주어진 문장 $W = (w_1, w_2, ..., w_N)$에 대해서 PPL은 다음과 같이 정의되고,
$$ PPL(W) = P(w_1, w_2, ..., w_N)^{-\frac{1}{N}} = \sqrt[N]{\frac{1}{P(w_1, w_2, ..., w_N)}} $$
- 여기서 체인 룰(Chain Rule)을 적용하게 되면,
$$ PPL(W) = \sqrt[N]{\frac{1}{\prod_{i=1}^{N} P(w_i | w_1, w_2, ..., w_{i-1})}} $$
- Bigram 모델이라고 생각하면,
$$ PPL(W) = \sqrt[N]{\frac{1}{\prod_{i=1}^{N} P(w_i | w_{i-1})}} $$
- 과 같이 계산됩니다.
💡 분기 계수 (Branching Factor)
- PPL은 해당 모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하는지를 나타내는 척도입니다.
- 예를 들어, 테스트 데이터에 대해 PPL이 10이라면, 이 모델은 매 시점마다 평균적으로 10개의 단어 후보 중 하나를 선택한다고 해석할 수 있습니다.
- PPL이 낮다고 해서 반드시 사람이 느끼기에 더 좋은 모델이라는 것을 의미하지는 않으며, 테스트 데이터의 도메인과 크기에 따라 신뢰성이 달라질 수 있습니다.
💡 N-gram과 인공 신경망 언어 모델의 비교
- PPL을 사용해서 N-gram 모델과 신경망 기반 모델을 비교한 연구를 확인해보면, 전통적인 5-gram 모델(Kneser-Ney)을 사용한 경우 PPL이 67.6으로 측정되었습니다.
- 반면, 신경망 모델(RNN, LSTM 등)은 더 낮은 PPL 값(각각 43.7, 30)을 보여 더 좋은 성능을 보인다는 것을 확인했습니다.
👆🏻 카운트 기반의 단어 표현(Count-Based Word Representation)
- 자연어 처리에서 텍스트를 수치화하는 방법은 여러 가지가 있으며, 특히 정보 검색과 텍스트 마이닝에서는 카운트 기반의 텍스트 표현 방법이 주로 사용됩니다.
- 대표적인 방법으로 DTM(Document-Term Matrix)과 TF-IDF(Term Frequency-Inverse Document Frequency)의 두 가지 방법이 존재합니다.
- 이러한 방식으로 텍스트를 수치화하면, 특정 단어가 문서에서 얼마나 중요한지를 나타내거나, 문서의 핵심어를 추출, 검색 엔진에서 검색 결과의 순위 결정, 문서 간 유사도 계산 등 다양한 용도로 활용될 수 있습니다.
✨ 단어의 표현 방법은 다양하다!
- 단어의 표현 방식은 크게 두 가지로 나뉘는데,
- 국소 표현(Local Representation, 이산 표현)
- 단어 자체에 특정 값을 매핑하여 표현하는 방식으로, 이 표현은 단어의 의미나 뉘앙스를 반영하지 못합니다.
- 예를 들면 전에 배운 One-hot Encoding, N-gram, 그리고 Bag of Words 등이 있습니다.
- 분산 표현(Distributed Representation, 연속 표현)
- 단어를 주변 단어와의 관계를 통해 표현하는 방식으로 단어의 의미적 유사성을 반영할 수 있습니다.
- 앞으로 배울 Word2Vec, FastText, GloVe와 같은 방식들이 있고,
- 국소 표현은 단어의 의미를 반영하지 못하지만, 분산 표현은 단어의 뉘앙스까지 포함할 수 있습니다.
- 더 나아가면, 연속 표현은 분산 표현을 포함하는 더 큰 개념으로 볼 수도 있습니다.
- 예를 들어 나중에 배울 수도 있는 LSA(Latent Semantic Analysis)나 LDA(Latent Dirichlet Allocation)는 연속 표현이지만, Word2Vec과 같은 분산 표현 방식과는 접근법이 다릅니다.
💡 한 눈에 보는 단어 표현 방식
| 표현 방식 | 특징 | 예시 |
| 국소 표현 (Local Representation) | 단어 자체를 독립적으로 수치화 | One-hot Encoding, N-gram |
| 카운트 기반 (Count-Based) | 단어 빈도를 이용해 표현 | Bag of Words (DTM), TF-IDF |
| 연속 표현 (Continuous Representation) | 단어 의미를 반영하여 표현 | LSA, Word2Vec, GloVe |
| 예측 기반 (Prediction-Based) | 신경망을 활용하여 단어의 의미를 학습 | Word2Vec (Skip-gram, CBOW), FastText |
| 혼합 방식 (Count + Prediction) | 카운트와 예측 방식을 결합 | GloVe |
✨ Bag of Words(BoW)란?
- BoW는 단어의 등장 순서를 고려하지 않고, 단어의 빈도수만을 고려해서 텍스트를 수치화하는 방법입니다.
- 즉, 문서를 단어가 담긴 '가방(bag)'으로 생각하고, 단어가 몇 번 나타났는지만 세는 방식입니다.
- BoW를 만드는 두 가지 과정이 있는데, 하나는 문서 내 모든 단어에 고유한 인덱스를 부여해서 단어 집합을 생성하는 과정과,
- 각 인덱스 위치에 단어 등장 횟수를 저장한 벡터를 생성하는 과정이 있습니다.
💡 한국어 예시로 이해해보자
- 예를 들어, "정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다."라는 문장으로 분석을 한다고 칩시다.
- 그럼 BoW는 다음과 같은 코드로 생성할 수 있습니다.
from konlpy.tag import Okt
okt = Okt()
def build_bag_of_words(document):
document = document.replace('.', '')
tokenized_document = okt.morphs(document)
word_to_index = {}
bow = []
for word in tokenized_document:
if word not in word_to_index:
word_to_index[word] = len(word_to_index)
bow.append(1)
else:
index = word_to_index[word]
bow[index] += 1
return word_to_index, bow
doc = "정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다."
word_to_index, bow = build_bag_of_words(doc)
print(word_to_index)
print(bow)
# {'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9}
# [1, 2, 1, 1, 2, 1, 1, 1, 1, 1]- 위 벡터 결과에서 물가상승률이라는 단어가 두 번 등장했기 때문에 값이 2로 기록되게 됩니다.
💡 영어 문서로는 어떻게 만들지? (CountVectorizer)
- 당연히 영어는 한국어보다 훨씬 쉽죠. scikit-learn의 CountVectorizer를 사용하여 간단히 구현할 수 있습니다.
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['Family is not an important thing. It is everything.']
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(text)
print("BoW 벡터:", X.toarray())
print("단어 인덱스:", vectorizer.vocabulary_)- 길이가 2 미만인 단어(예를 들어 'I'의 경우)는 기본적으로 제외됩니다.
- 띄어쓰기를 기준으로 단어를 구분하기 때문에 한국어를 적용시키기는 어렵습니다.
💡 BoW에서 불용어는 어떻게 처리할까?
- BoW에서도 불용어를 제외하기 위한 총 3가지 방법이 있는데요! 바로 알려드리겠습니다.
- 사용자가 정의하는 불용어를 사용하기
- vect = CountVectorizer(stop_words=['is', 'not', 'an'])
- CountVectorizer에 내장되어 있는 불용어를 사용하기
- vect = CountVectorizer(stop_words='english')
- NLTK 라이브러리의 불용어를 사용하기
- from nltk.corpus import stopwords
- stop_words = stopwords.words("english")
- vect = CountVectorizer(stop_words=stop_words)
✨ 그렇담 문서 단어 행렬(Document-Term Matrix, DTM)이란?
- DTM은 여러 개의 문서를 하나의 행렬 형태로 표현한 것으로, 각 문서에 대한 단어의 등장 빈도수를 행렬로 나타낸 것입니다.
- 아까 배웠던 BoW(Bag of Words)를 여러 문서로 확장한 개념으로 볼 수 있습니다.
| 과일이 | 길고 | 노란 | 바나나 | 소비 | 정부 | 발표 | |
| 문서1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 문서2 | 0 | 0 | 0 | 1 | 1 | 1 | 2 |
| 문서3 | 0 | 1 | 1 | 2 | 0 | 0 | 0 |
| 문서4 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
⚠️ 이러한 DTM의 한계점은? 희소 표현!
- DTM의 각 행(문서 벡터)은 단어 집합 전체를 차원으로 가지므로, 보통 대부분의 값이 0이 됩니다.
- 이렇게 0이 많은 행렬을 희소 행렬(sparse matrix)이라고 부르는데요.
- 이런 희소성 문제는 메모리 비효율과 계산 속도 저하의 원인이 됩니다.
- 해결책으로는 불용어 제거, 빈도가 낮은 단어 제거, 어간 및 표제어 추출을 통한 단어 정규화가 필요합니다.
- 또한, DTM은 단어의 빈도수만을 고려하기 때문에 불용어가 빈번하게 등장하면 문서 간 유사성 분석에서 잘못된 판단을 유발할 수 있습니다.
- 이런 점을 극복하기 위해서 중요한 단어와 그렇지 않은 단어의 가중치를 다르게 적용하는 TF-IDF 기법을 사용하게 된 것입니다.
✨ TF-IDF에 대해서도 알아보자!
- TF-IDF는 문서에서 단어의 중요도를 평가하는 방법으로, 단순 빈도(BoW) 기반의 한계를 보완해줍니다.
- 각 단어에 대해 두 가지 요소(TF, IDF)로 구성되는데요.
- 하나는 단어 빈도(Term Frequency, TF)로 특정 문서 내에서 단어가 등장한 빈도이고,
- 두번째는 역 문서 빈도 (Inverse Document Frequency, IDF)로 특정 단어가 등장한 문서의 수에 반비례하는 값입니다.
- 보통 자주 등장하는 단어가 중요한 단어일 가능성이 높지만, 모든 문서에 공통적으로 자주 등장하면 중요하지 않을 가능성이 큽니다.
- 따라서, 한 문서에서만 빈번히 나타나는 단어의 중요도를 높이는 방법입니다.
💡 TF-IDF는 어떻게 구해질까?
- TF는 특정 문서 d에서 특정 단어 t가 등장한 횟수로, 이미 DTM에서 구한 값을 사용합니다.
$$TF(d, t) = \text{문서 } d \text{ 내 단어 } t \text{의 등장 횟수}$$
- IDF는 전체 문서 수 n과 특정 단어가 등장한 문서 수 df(t)를 이용해 계산합니다.
$$IDF(t) = \log \frac{n}{1 + df(t)}$$
- 이때, 1을 더해주는 이유는 분모가 0이 되는 상황을 방지하기 위함입니다.
- 로그를 취함으로써 문서 수가 커지더라도 극단적으로 IDF 값이 커지는 것을 막아주는 역할을 합니다.
- 이 IDF 값이 높을수록 특정 문서에만 등장한 중요한 단어로 평가됩니다.
- 그리고 마지막 TF-IDF는 위에서 구한 TF와 IDF를 곱한 값입니다!
$$TF\text{-}IDF(d, t) = TF(d, t) \times IDF(t)$$
💡 TF-IDF의 특징과 장점
- 모든 문서에 공통적으로 등장하는 단어(예를 들어 불용어 등)는 자동으로 중요도가 낮아집니다.
- 희귀 단어와 문서에 특화된 단어를 강조하는 효과가 있습니다.
- 문서 분류, 문서 검색, 문서 유사도 평가 등 다양한 분야에서 자주 활용됩니다.
⚠️ 그렇지만 TF-IDF의 한계점도 존재하는데...!
- 단순히 빈도 기반이기 때문에 단어의 의미적 맥락이나 순서를 고려하지 않습니다.
- 모든 상황에서 반드시 좋은 성능을 보장하지는 않으므로, 실험적인 접근을 통해서 적합성을 판단할 필요가 있습니다.
✨ Scikit-learn으로도 TF-IDF를 계산할 수 있다?!
💡 기본적인 DTM (CountVectorizer)
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['you know I want your love', 'I like you', 'what should I do']
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print("DTM:\n", X.toarray())
print("Vocabulary:", vectorizer.vocabulary_)
💡 Scikit-learn의 TfidfVectorizer로 구현하기!
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = ['you know I want your love', 'I like you', 'what should I do']
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(corpus)
print("TF-IDF Matrix:\n", tfidf_matrix.toarray())
print("Vocabulary:", tfidf_vectorizer.vocabulary_)- sklearn에서는 기본 TF-IDF 식에 약간의 조정을 가해서 사용합니다. (로그 내부 항에 +1을 추가하거나 정규화를 수행하는 등)
🤔 30일차 회고
- 오늘은 복잡하고 어렵지만, 텍스트 전처리에서 가장 기본적인 내용들을 주로 다뤄보았습니다.
- 오늘 포스팅되어있는 내용의 양만 봐도 하루만에 끝낸 것이 대견할 정도로 방대한 양을 배웠습니다.
- 그렇기에 자주자주 살펴보며, 관련 내용으로 면접을 보게 되더라도 바로 답변이 나올 수 있도록 꼼꼼히 살펴봐야할 것 같습니다.
- 중간중간 수식들이 많이 등장하고, 생소한 용어들도 꽤나 많았지만, 오늘 배운 내용들을 가지고 텍스트 전처리를 진행함에 있어서 무리없이 할 수 있도록 잘 숙지하겠습니다!
- 내일은 본격적인 머신러닝을 쭉 배울 예정입니다. 내일도 화이팅 :)
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 이번엔 좀 더 깊게 달려보자 (3) | 2025.03.13 |
|---|---|
| 🤔 왜 달려도 달려도 끝이 없을까... (8) | 2025.03.12 |
| 🤔 자연어를 전처리해보자 (7) | 2025.03.07 |
| 🤔 자연어를 처리해보자 (6) | 2025.03.06 |
| 🤔 SQL 끝장내기 (2) | 2025.03.04 |