
728x90
SMALL

- 오늘은 Numpy 라이브러리의 주요 연산 및 함수들, Seaborn 라이브러리로 데이터를 다양하게 시각화하는 방법들을 배우고 Pandas 라이브러리와 통합하여 실습을 진행했습니다.
🤯 Numpy
- Numpy(Numerical Python)는 다차원 배열 객체를 지원하는 파이썬의 핵심적인 라이브러리입니다.
- 또한, 대용량의 배열과 행렬 연산(이미지, 영상 분석)을 수행할 때 주로 사용되는 라이브러리입니다.
✨ ndarray 특징 및 속성
💡 ndarray의 특징
- Python의 기본 리스트보다 빠르고, 메모리를 효율적으로 사용하며, 벡터 연산이 가능한 데이터 구조입니다.
- ndarray 객체는 동일한 자료형의 항목들만 저장이 가능합니다.
💡 ndarray의 기본 속성
- ndarray 객체는 기본적으로 다음과 같은 속성들을 가지고 있고, ndarray.(shape, dtype, ndim, size)과 같이 입력하시면 각 속성을 확인할 수 있습니다.
| 속성 | 설명 |
| 배열의 모양 (shape) | 배열의 각 차원에서의 크기를 튜플 형태로 나타내줍니다. |
| 배열의 데이터 타입 (dtype) | 배열의 원소들이 어떤 데이터 타입인지 확인할 때 사용합니다. |
| 배열의 차원 (ndim) | 배열이 몇 차원인지 확인할 때 사용됩니다. (1D: 벡터, 2D: 행렬, 3D 이상: 텐서) |
| 배열의 총 원소 개수 (size) | 배열에 포함된 총 원소의 개수를 확인해줍니다. |
✨ ndarray 생성 및 초기화
💡 데이터 타입 지정 방법
- ndarray의 타입을 지정하는 방법에는 총 두 가지가 존재하는데, 하나는 np의 타입으로, 하나는 문자열로 지정하는 방법입니다.
- np.array([1, 2, 3, 4], dtype=np.int32)
- np.array([1, 2, 3, 4], dtype='int32')
💡 초기화 함수
- ndarray를 한 번에 생성 및 초기화를 하고 싶을 때 다음과 같은 함수들을 이용할 수 있습니다.
| 함수 | 설명 | 예제 |
| np.zeros(shape) | 모든 값을 0으로 초기화 | np.zeros((2, 3)) → [[0. 0. 0.] [0. 0. 0.]] |
| np.ones(shape) | 모든 값을 1로 초기화 | np.ones((3, 3)) → [[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]] |
| np.full(shape, fill_value) | 모든 값을 지정한 값으로 채움 | np.full((2, 2), 7) → [[7 7] [7 7]] |
| np.eye(N) | N × N 크기의 단위 행렬(I) 생성 | np.eye(3) → [[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]] |
✨ 연속적인 값을 가지는 ndarray를 생성해주는 함수들
💡 np.arange([start, ]stop, [step])
- 일정한 간격으로 연속된 숫자를 생성하는 함수입니다. (Python의 range() 함수와 유사)
| 매개변수 | 설명 |
| start | (선택) 시작 값 (기본값: 0) |
| stop | (필수) 끝 값 (미포함) |
| step | (선택) 증가 간격 (기본값: 1) |
💡 np.linspace(start, stop, num=50)
- 지정한 범위 내에서 균등한 간격으로 값을 생성해주는 함수입니다.
| 매개변수 | 설명 |
| start | 시작 값 |
| stop | 끝 값 (포함) |
| step | 생성할 숫자의 개수 (기본값: 50) |
✨ ndarray의 연산
💡 사칙 연산
- ndarray는 사칙 연산을 수행할 때, 개별 원소별(element-wise)로 덧셈, 뺄셈, 곱셈, 나눗셈이 이루어지게 됩니다.
- python 리스트는 리스트와 리스트 간 연산, Numpy 배열의 연산은 요소와 요소 간의 연산이라고 보시면 되겠습니다!
💡 브로드캐스팅(Broadcasting)
- 서로 다른 크기의 배열 간 연산을 가능하게 하는 Numpy의 주요 기능입니다.
- 작은 배열이 자동으로 확장되어 크기가 큰 배열과 연산이 가능하도록 만들어줍니다.
- 단일 값(스칼라)도 배열과 연산 시 자동으로 확장됩니다.
💡 벡터화 연산(vectorized operation)
- 반복문을 사용하지 않고 배열 전체에 대해 연산을 수행하는 Numpy의 주요 기법입니다.
- Numpy는 내부적으로 C로 구현된 최적화 연산을 사용하기 때문에 벡터화 연산을 활용하면 속도가 훨씬 빠릅니다.
💡 행렬 연산(matmul)
- matmul() 함수는 행렬 곱셈을 수행하는 함수로, 일반적인 요소별 곱셈 (*)과 다르게 행렬 연산 규칙을 따르는 함수입니다.
- 즉, 스칼라 곱셈 A * B는 요소별 곱셈이고, np.matmul(A, B) 또는 A @ B을 사용한 곱셈은 행렬 곱셈입니다.
- matmul() 함수는 두 행렬의 차원이 맞아야 연산이 가능합니다. (예를 들어, (m, n) @ (n, p) → (m, p))
✨ 배열의 축과 삽입
- 해당 함수들로 데이터의 삽입이 이루어질 때는 원본 데이터에 영향을 미치지 않습니다.
💡 np.insert(arr, obj, values, axis=None)
- 배열의 특정 위치에 새로운 값을 삽입하는 함수입니다.
| 매개변수 | 설명 |
| arr | 원본 배열 |
| obj | 값을 삽입할 인덱스 (위치) |
| values | 삽입할 값 |
| axis | 0: 행 방향(세로), 1: 열 방향(가로) (기본값: None) |
💡 np.flip(m, axis=None)
- 배열의 요소를 지정된 축을 기준으로 반전(뒤집기)해주는 함수입니다.
| 매개변수 | 설명 |
| arr | 원본 배열 |
| axis | 뒤집을 축 (기본값: None , 모든 축 반전) |
| axis=0 | 행(세로) 방향으로 뒤집기 |
| axis=1 | 열(가로) 방향으로 뒤집기 |
✨ 배열 조작 및 변형
💡 배열의 차원 변환
| 함수 | 설명 |
| arr.flatten() | 다차원 배열을 1차원 배열로 변환하는 함수입니다. (매우 중요!!!) |
| np.reshape(arr, new_shape) | 배열의 차원을 변경한 새로운 배열 반환하는 함수입니다. (매우 중요!!!) |
- 배열의 총 원소 개수(size)가 동일해야만 reshape() 함수가 가능합니다.
- (3, 4) → (2, 6)는 변환이 가능합니다. (총 원소 개수가 12개로 유지되기 때문에)
- reshape()은 원본 배열을 변경하지 않고 새로운 배열을 반환합니다.
- 따라서 arr = arr.reshape(...)와 같이 덮어쓰기가 가능합니다.
- -1을 사용하면 자동으로 계산됩니다.
- np.reshape(arr, (-1, 3))을 입력하게 되면 열 개수 3에 맞게 자동으로 행이 결정됩니다.
💡 배열의 데이터 타입 변경
| 함수 | 설명 |
| arr.astype(dtype) | 배열의 요소 타입을 변경하는 함수입니다. |
💡 배열 정렬
| 함수 | 설명 |
| np.sort(arr) | 배열을 오름차순으로 정렬해주는 함수입니다. (원본 변경 X) |
| arr.sort() | 배열을 제자리에서 정렬하는 함수입니다. (원본 변경 O) |
💡 배열 요소 추가
| 함수 | 설명 |
| np.append(arr, values, axis=None) | 배열의 끝에 새로운 값을 추가하는 함수입니다. |
✨ 인덱싱과 슬라이싱
- ndarray 내의 원소는 인덱스(정수)를 사용하여 참조가 가능합니다.
- 그리고, 특정 부분을 선택할 때 python 리스트와 같이 슬라이싱 기법을 사용할 수 있습니다.
arr_2d = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12]])
print(arr_2d[1:][0:2])
# 출력값
# [[4 5 6]
# [7 8 9]
# [0 1 2]]
✨ ndarray에서 값 탐색하기
- 아래 함수들은 전체 데이터 중 해당 값만을 반환해주는 함수입니다.
| 함수 | 설명 |
| arr.max() | 배열에서 최댓값을 반환하는 함수입니다. |
| arr.min() | 배열에서 최솟값을 반환하는 함수입니다. |
| arr.mean() | 배열의 평균값을 반환하는 함수입니다. |
😃 Seaborn
- seaborn은 matplotlib 기반의 통계 데이터 시각화 라이브러리로, matplotlib에 비해 높은 수준의 인터페이스를 제공해줍니다.
- matplotlib보다 더 직관적인 인터페이스를 제공하여 손쉽게 시각화가 가능한데,
- 갑자기 matplotlib을 안 쓰고 seaborn을 쓰는 이유는 !
- matplotlib.pyplot에는 pairplot이 없기 때문에 이를 경험해보기 위해서 사용하게 되었습니다.
🤷🏻 상관 관계
- 상관 관계는 두 개의 변수들이 함께 변화하는 관계를 의미합니다.
- 두 변수 간의 관계 유형에는 다음과 같이 세 가지가 있는데,
- 한 변수가 증가할 때 다른 값도 증가하면 양의 상관 관계
- 한 변수가 증가할 때 다른 값이 감소하면 음의 상관 관계
- 전혀 관계가 없다면, 0(상관 계수)으로 표현됩니다.
- 상관 관계 ≠ 인과 관계 (상관 관계가 있다고 해서 원인과 결과가 되는 것은 아닙니다.)
- ADsP 자격 시험에도 출제된 내용입니다 !
🤷🏼 상관 계수
- 변수들 사이의 상관 관계 정도를 나타내는 수치를 상관 계수라고 합니다.
- numpy의 np.corrcoef(x, y) 함수는 수학적으로 피어슨 상관 계수를 행렬 형태로 계산하여 보여줍니다.
- 또 이 행렬을 시각화해서 보려면, pyplot에 있는 plt.imshow(corrcoef(x, y))를 통해 히트맵으로 시각화도 가능하게 됩니다.
✨ 설정 함수
| 함수 | 설명 |
| sns.set_theme(style='darkgrid', font='sans-serif') | Seaborn의 테마 스타일을 설정합니다. |
| sns.load_dataset(name) | Seaborn에서 제공하는 샘플 데이터를 로드합니다. |
✨ 시각화 함수
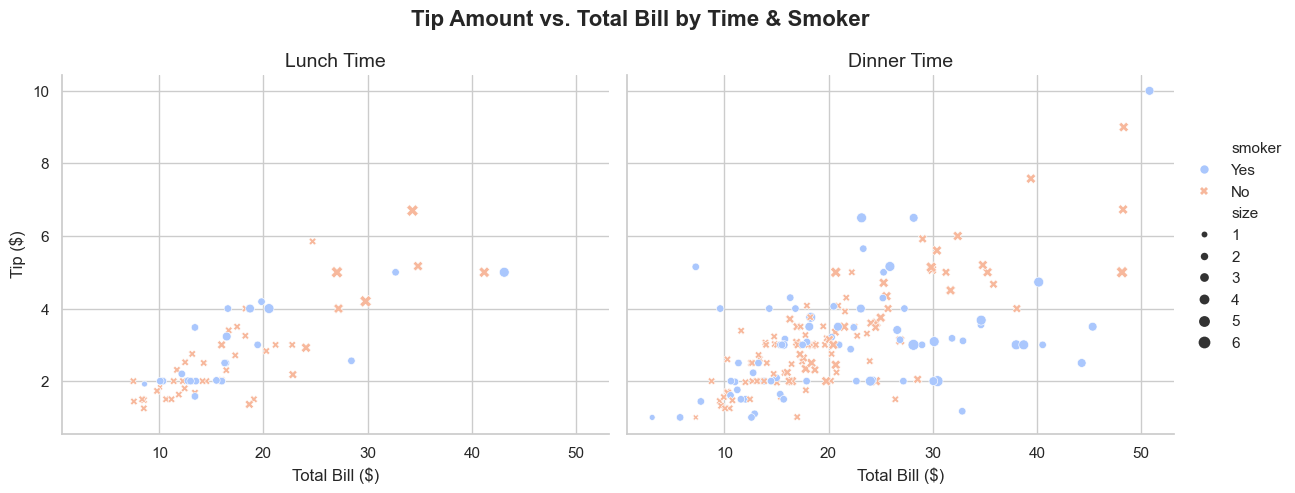
💡 sns.relplot(data=None, x=None, y=None, hue=None, size=None, style=None, row=None, col=None, kind=None)
- 두 변수 간 관계를 시각화하는 산점도 함수입니다.
- 반드시 각각의 매개변수(data, x, y 등)를 통해서 직접 데이터를 넣어주어야 합니다.
- 또한, 속성 중에서 data만 데이터프레임을 넣어주어야 하고, 나머지는 컬럼명을 넘겨주어야 합니다.
💡 sns.distplot(a=None, bins=None, hist=True, kde=True)
- a 값에는 해당 데이터의 분석하고자 하는 컬럼명을 넘겨주면 됩니다.
- kde=True로 설정 시, 가우시안 커널 밀도 추정치를 선으로 그려볼 수도 있습니다.
- bins에 특정 숫자를 넘겨주면 matplotlib의 히스토그램과 같이 구간을 설정할 수 있습니다.
- 현재는 distplot이 DEPRECATED되어서 displot()으로 변경해서 사용하시면 되겠습니다.

💡 sns.regplot(data=None, x=None, y=None)
- 산점도에 선형 회귀선을 추가로 그려주는 시각화 함수입니다.
- data에 데이터프레임, x, y에는 각각 컬럼명을 넘겨주면 되지만, regplot()로 반환되는 값은 특정 변수에 저장시킨 후에 시각화를 진행해야 합니다.

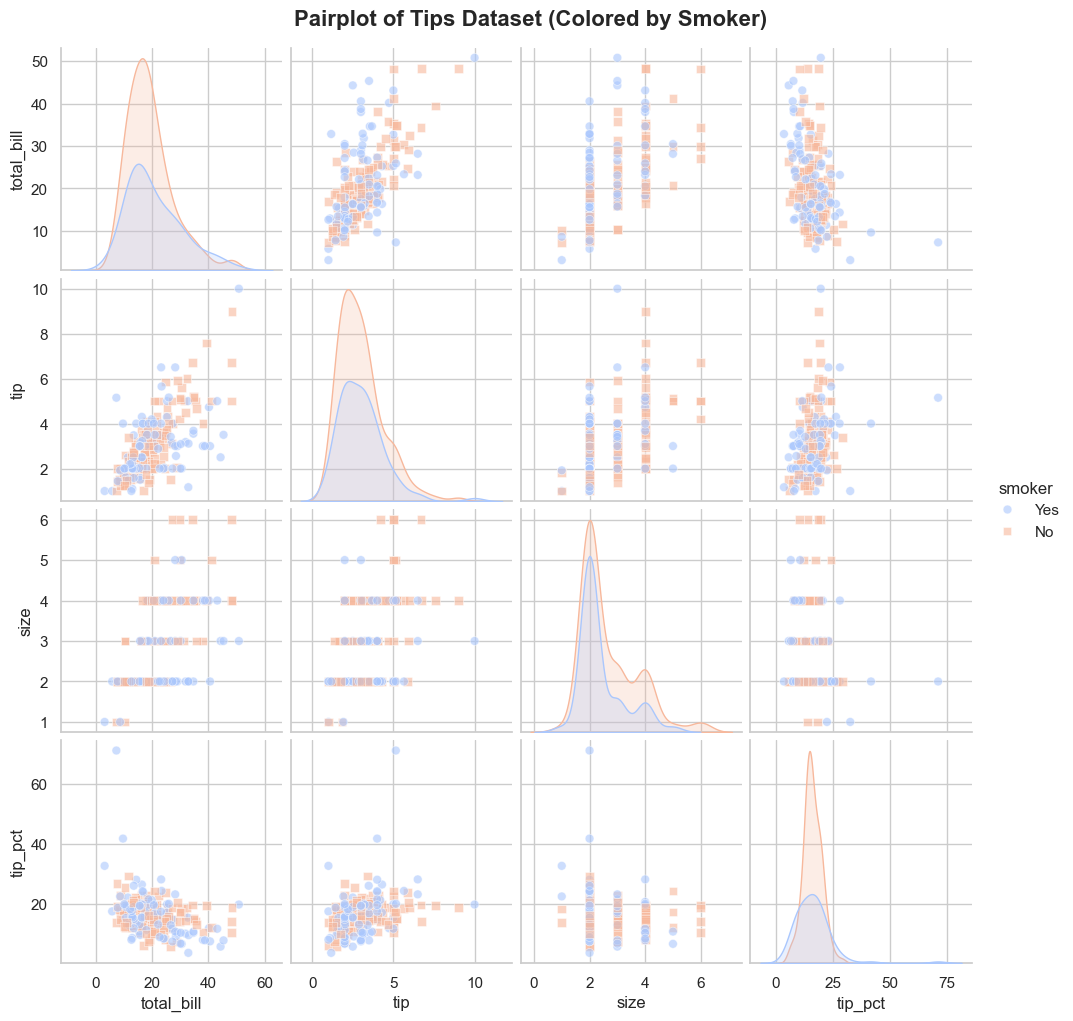
💡 sns.pairplot(data, hue=None, hue_order=None, palette=None)
- 사실 이것 때문에 seaborn을 쓴다 해도 과언이 아닌데, 여러 변수들 사이의 관계를 살펴보기 위한 차트를 그려주는 함수입니다.
- 데이터프레임 전체를 입력하면 모든 수치형 변수 간의 관계를 자동으로 플로팅해줍니다.
💡 sns.lmplot(data, x=None, y=None, ci=95, order=1, scatter_kws=None)
- 선형 회귀선을 구하고 시각화하는 기능을 포함한 함수입니다.
- sns.regplot() 함수와 유사하지만, 범주별로 여러 개의 회귀선을 그릴 수 있다는 특징이 있습니다.
- ci=95로 설정하면 95% 신뢰구간을 나타내는 음영 영역까지도 포함해서 시각화해줍니다.
- order에 설정된 값으로 몇 차수의 회귀선을 시각화할지 결정하게 됩니다. (1이면 직선, 2라면 곡선)
- scatter_kws는 산점도 마커의 스타일을 지정할 수 있습니다.

🐼 Pandas로 데이터 그룹핑 및 분석
- 데이터 분석 과정에서 대량의 데이터를 효과적으로 다루기 위해 특정 기준으로 데이터를 나누고(그룹핑),
- 그룹별 통계량을 계산하여 의미 있는 인사이트를 도출해야 할 때가 많기 때문에 pandas의 groupby()를 통해 이를 경험해보고자 합니다.
✨ 관련 함수
✨ df.iloc[]
- Pandas 데이터프레임(DataFrame)에서 위치 기반(정수 인덱스)으로 행과 열을 선택하는 방법입니다.
- 라벨(df.loc[])이 아닌 위치(df.iloc[]) 기반으로 행과 열을 선택할 때 사용되는 방법입니다.
✨ df.groupby()
- 데이터프레임에서 특정 컬럼을 기준으로 그룹을 생성하고, 그룹별로 연산을 수행하게 되는 함수입니다.
- 추가적으로 agg()으로 각 그룹별 여러 개의 연산(sum, mean 등)을 동시에 적용할 수도 있습니다.
✨ df.pivot(columns, index=<no_default>, values=<no_default>)
- 데이터프레임에서 특정 열을 기준으로 행과 열을 변환(재구성)하여 데이터를 요약해주는 함수입니다.
- groupby()는 그룹별 집계가 목적이라면, pivot()은 데이터의 재구성이 목적이라고 할 수 있겠습니다.
✨ df.fillna(value=None)
- 결측값(NaN)을 특정 값으로 채우는 함수입니다.
- 결측값은 데이터 분석 시 문제가 되므로, 이를 처리하기 위해 자주 사용되는 함수입니다.
- value에는 결측값을 대체할 값(숫자나 문자열)을 설정해주시면 됩니다.
🤔 9일차 회고
- 오늘은 numpy 다차원 배열(ndarray)을 다루는 것, seaborn 라이브러리의 다양한 함수로 여러 차트를 시각화해보는 것을 중점적으로 실습하였습니다.
- 이번 주는 월요일만 조금 널널하게 듣고, 나머지 나날들은 전부 블로그에, 노션에 정리하느라 정신이 없어 시간이 순삭된 것 같습니다.
- 이번 한 주를 보내면서, 저는 매번 배웠던 내용들을 정리하는데도 그저 전에 스쳐 들었던 내용들까지 이리도 세세히 배우게 되어 정말 다행이라고 생각합니다.
- 특히 주요 라이브러리들의 docs들을 보며 함수 하나 하나를 설계할 때 설계자가 얼마나 많은 공을 들였는지까지도 알게 되었습니다.
- 다음 주부터는 지금까지 배운 내용들을 토대로 본격적인 데이터 분석과 머신 러닝 관련 수업을 들을 예정인데, 다음 주도 밀리지 않게 열심히 정리하며 체득해보겠습니다!
728x90
LIST
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 Iterator와 Generator 그리고 한국인의 삶 (2) | 2025.02.12 |
|---|---|
| 🤔 Python 이론 살짝 업글해보기 (4) | 2025.02.11 |
| 🤔 Matplotlib을 활용한 본격적인 시각화 (2) | 2025.02.06 |
| 🤔 Series와 DataFrame 그리고 Pandas (1) | 2025.02.06 |
| 🤔 함수와 모듈 그리고 클래스 (15) | 2025.02.04 |