
728x90
SMALL

- 오늘은 어제에 이어 Matplotlib 라이브러리를 가지고 여러 유형의 차트를 그려보며, 주어진 데이터를 시각화해보는 작업을 거쳤습니다.
📈 matplotlib.pyplot
- matplotlib, 그 중에서도 pyplot 라이브러리는 파이썬에서 데이터를 시각화할 때 사용하는 대표적인 라이브러리입니다.
- 특히 MATLAB 스타일의 인터페이스를 제공하며, 간단한 코드로 그래프를 쉽게 만들 수 있습니다.
- 앞으로 이 matplotlib.pyplot을 간단히 plt로 줄여 설명드리겠습니다.
✨ plt의 특징
- plt는 다양한 그래프(선 그래프, 막대 그래프, 산점도 그래프 등)을 지원해줍니다.
- 또한, 커스텀 함수들이 정말 다양하기 때문에 손쉽게 차트의 변형이 가능합니다.
- 또 생성한 차트를 그래프로 출력하거나 이미지로 저장하는 것도 용이합니다.
- 그럼 이 특징들이 어떤 함수들을 통해 나타나게 되는지 주요 함수들을 정리해보겠습니다.
📌 컨텍스트 생성 및 관리 함수
💡 plt.figure(figsize=None, dpi=None)
- 새로운 차트를 만들거나 기존 차트를 활성화해주는 함수입니다.
- figsize에 비율(예를 들어서 (10, 6)과 같이)을 추가해주면, 해당 비율로 차트의 크기가 설정됩니다.
- dpi 속성으로는 만들어지는 차트의 해상도를 설정하고 변경할 수 있습니다.
📌 설정 및 장식 함수
💡 plt.title(label)
- 차트의 제목을 설정하는 함수로, 이 제목은 기본적으로 차트가 그려지는 영역 위 중앙에 설정됩니다.
💡plt.legend()
- 차트의 범례를 보여주는 함수로, 이 범례를 보여주기 위해서는 해당 차트의 시각화 함수에 label이 표시되어 있어야 합니다.
💡 plt.colorbar(), plt.grid(axis='both')
- colorbar()는 차트에 색상 막대를, grid()는 그리드 격자를 추가해주는 함수입니다.
💡 plt.xlabel(xlabel), plt.ylabel(ylabel)
- x축, y축에 라벨을 달아주는 함수입니다.
💡 plt.xlim(left, right), plt.ylim(left, right)
- 현재 차트의 x축과 y축에 대한 범위를 제한할 때 사용하는 함수입니다.
- 차트에서는 데이터가 바뀌는 것처럼 보이지만, 실제로 데이터는 바뀌지 않습니다.
🌟 데이터 시각화 함수
💡 plt.plot(color=color, label=object, linestyle=offset, linewidth=offset, marker=None)
- 선 그래프를 그려주는 함수로, 가장 기본적 형태는 x, y 좌표 데이터를 받아 해당 데이터를 선으로 연결해 시각화해줍니다.
- 데이터를 하나 집어넣었을 때는 해당 데이터로 구성된 x, y 좌표들로 자동 설정됩니다.
- 데이터 두 개를 집어넣었을 때는 하나는 x축, 하나는 y축으로 설정되는데, 이때 두 데이터의 개수가 정확히 동일해야 함
- 아래 속성들은 외울 필요는 없지만, 오늘 실습에서 사용된 속성들을 나열해본 것입니다.
- label=object: 범례에 표시될 내용을 설정할 때 사용
- color=color: 차트 라인의 색상을 정할 때 사용
- ls 또는 linestyle=offset: 차트의 라인 스타일을 정할 때 사용
- lw 또는 linewidth=offset: 차트의 라인 굵기를 정할 때 사용
- marker=marker: 데이터가 표시될 모양(마커)을 변경할 때 사용
- markerfacecolor=color: 마커의 색상을 변경할 때 사용
- markersize=offset: 마커의 사이즈를 변경할 때 사용
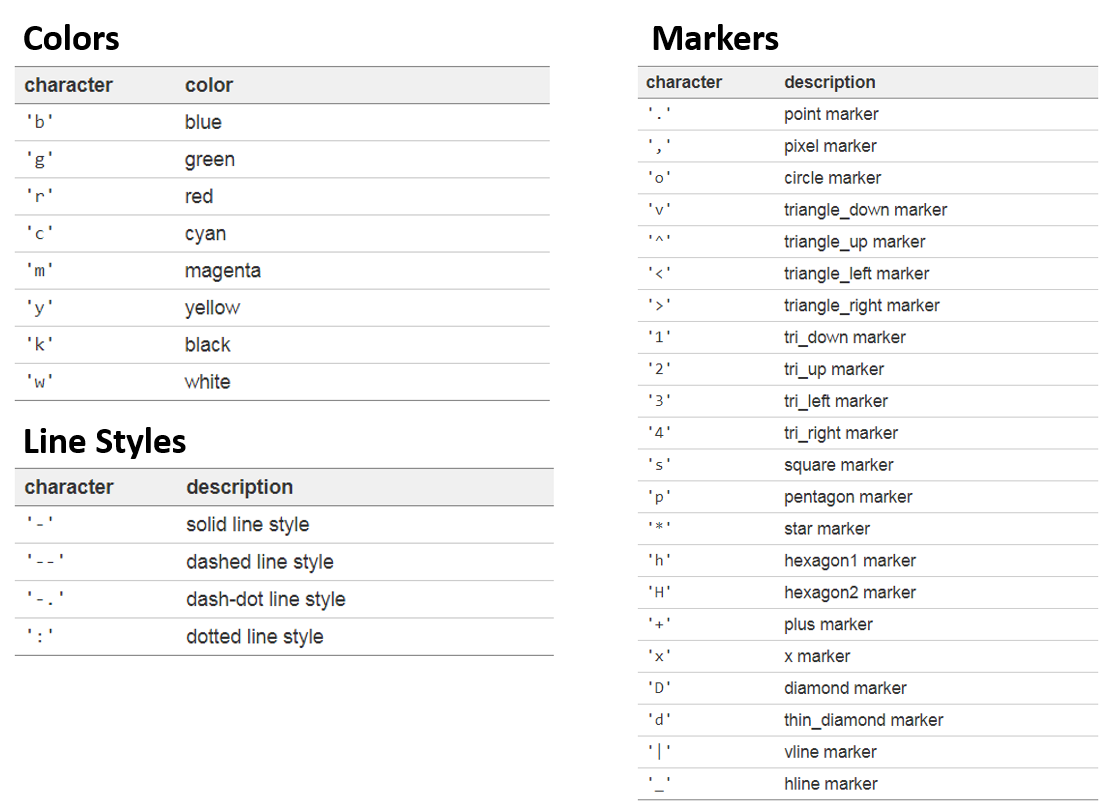
- 하단 이미지는 color, linestyle, marker 속성에 들어가는 기본적인 값들을 정리해둔 표입니다.
💡 plt.scatter(x, y, s=None, c=None, marker=None, cmap=None)
- 데이터의 분포를 알아내기 아주 좋은! 그래프인 산점도 그래프를 그려주는 함수입니다.
- x축과 y축에 해당하는 데이터의 상관 관계를 표현할 때 사용되며,
- 두 개의 축을 기준으로 데이터가 얼마나 퍼져있는지 그 분포를 알아낸다는 의미에서 '산포도'라고도 불립니다.
- 산점도 그래프를 그릴 때에도 주요 속성들이 포함되는데 아래에 간단히 나열해놓겠습니다.
- marker=None: 점의 유형을 변경할 때 사용
- s=None: 점의 크기를 조정할 때 사용
- c=None: 점의 색상을 조정할 때 사용
- cmap=None: 점의 색상을 일일이 리스트로 주고 싶지 않을 때, 내장 cmap을 이용해 점의 색상을 지정할 때 사
- 그래서 이러한 속성들로 matplotlib 라이브러리를 사용해 지역별로 남녀의 인구 데이터를 산점도 그래프로 시각화하는 코드는 아래처럼 구현하였습니다!
import csv
import math
import matplotlib.pyplot as plt
file = open('./data/gender.csv')
data = csv.reader(file)
name = input('궁금한 지역(도 단위)을 입력해주세요!: ')
m = []
f = []
size = []
for row in data:
if name in row[0]:
for i in range(3, 104):
m.append(int(row[i]))
f.append(int(row[i+103]))
size.append(math.sqrt(int(row[i]) + int(row[i+103])))
break
plt.figure(figsize=(10, 6), dpi=300)
plt.title(f'{name}의 남녀 인구 수 분포 및 추세선')
plt.scatter(m, f, c=range(101),
alpha=0.5,
s=size,
cmap='Reds')
# 추세선 시각화
plt.plot(range(max(m)), range(max(m)), 'lightcoral')
plt.xlabel('남성 인구 수')
plt.ylabel('여성 인구 수')
plt.colorbar()
plt.show()- 위 코드의 결과는 다음과 같이 나오게 됩니다. 중간에 math.sqrt()를 사용한 이유는 각 점마다 크기를 다르게 하기 위해서인데, 이는 나중에 수학적인 부분도 다루게 될 때 다시 언급해보겠습니다.

💡 plt.hist(x, bins=None, range=None)
- 자료의 분포 상태를 직사각형 모양의 막대 그래프로 그려주는 함수입니다.
- 데이터의 빈도에 따라 막대 그래프의 높이가 결정됩니다.
- bins=None: 데이터를 몇 개의 구간으로 쪼갤지 결정
💡plt.boxplot(x)
- Boxplot은 데이터의 분포와 이상치(outlier)를 확인하기 위해 사용되는 그래프입니다.
- 여기서 말하는 말 그대로 이상한 값 즉, 다른 수치에 비해 너무 크거나 작은 값을 나타낸 것입니다.
- boxplot() 함수는 이 최대값, 최소값, 상위 1/4, 2/4(중앙값), 3/4에 위치한 값(사분위수)을 한 눈에 보여주는 그래프인 Boxplot을 그려주는 함수입니다.

💡 plt.bar(x, height), plt.barh(y, width)
- 막대 그래프를 그릴 수 있는 두 가지 함수입니다.
- bar() 함수는 x축에 범주형 데이터(categories), y축에 값을 매핑하여 위로 올라가는 막대 그래프를 그려주고,
- barh() 함수는 y축에 범주형 데이터, x축에 값을 매핑하여 오른쪽으로 확장되는 막대 그래프를 그려주는 함수입니다.

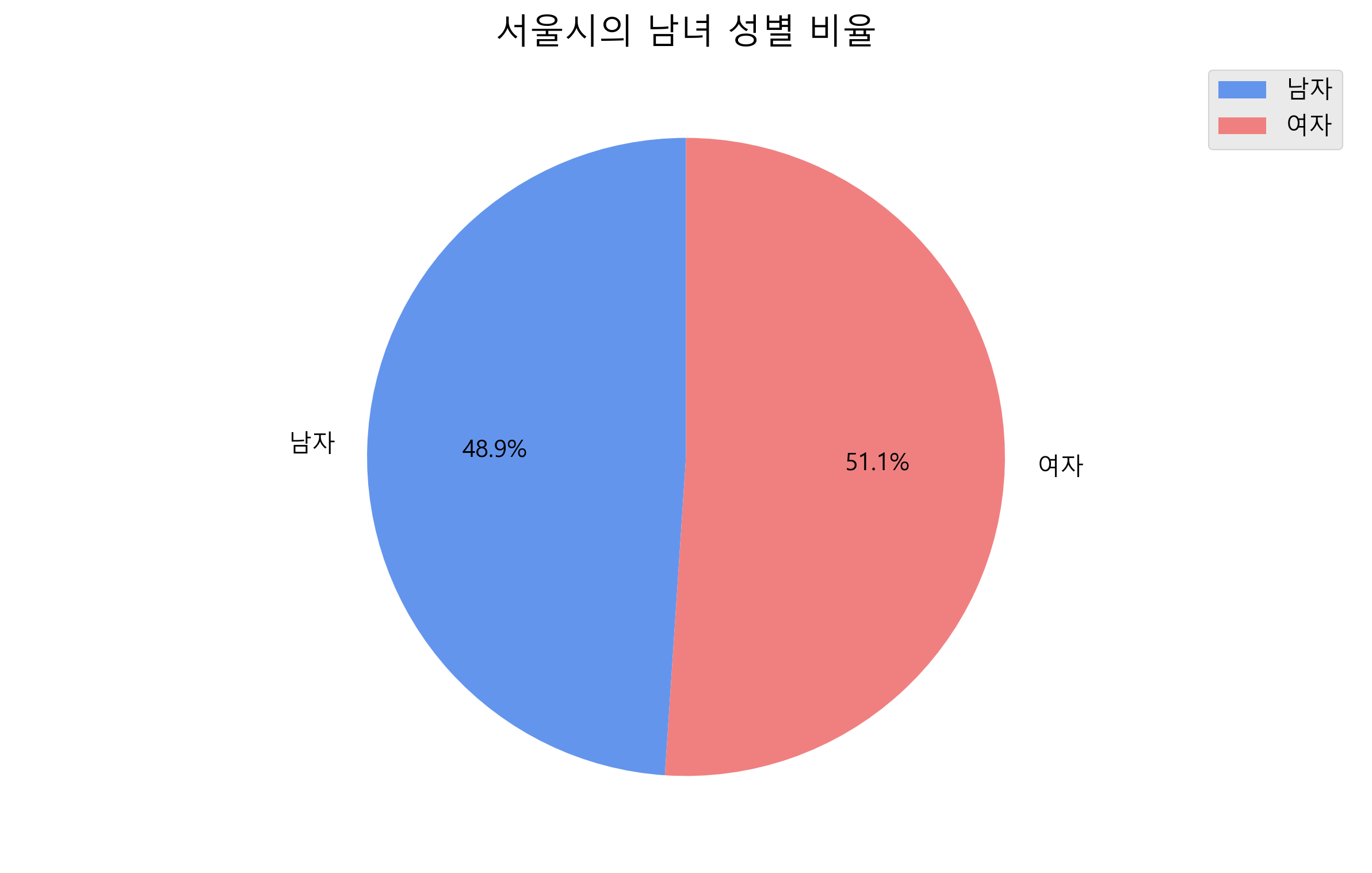
💡 plt.pie(x, explode=None, labels=None, colors=None, autopct=None)
- 비율(퍼센트)이나 구성 요소를 시각적으로 나타낼 때 사용하는 원형 차트를 생성하는 함수입니다.
- explode=None: 각 영역을 얼마만큼의 비율로 떼어낼 지를 정할 때 사용
- labels=None: 각 영역의 레이블을 제공하는 문자열을 지정할 때 사용
- colors=None: 각 영역의 색깔을 지정할 때 사용
- autopct=None: 해당 데이터를 퍼센트로 표기하고자 할 때 사용
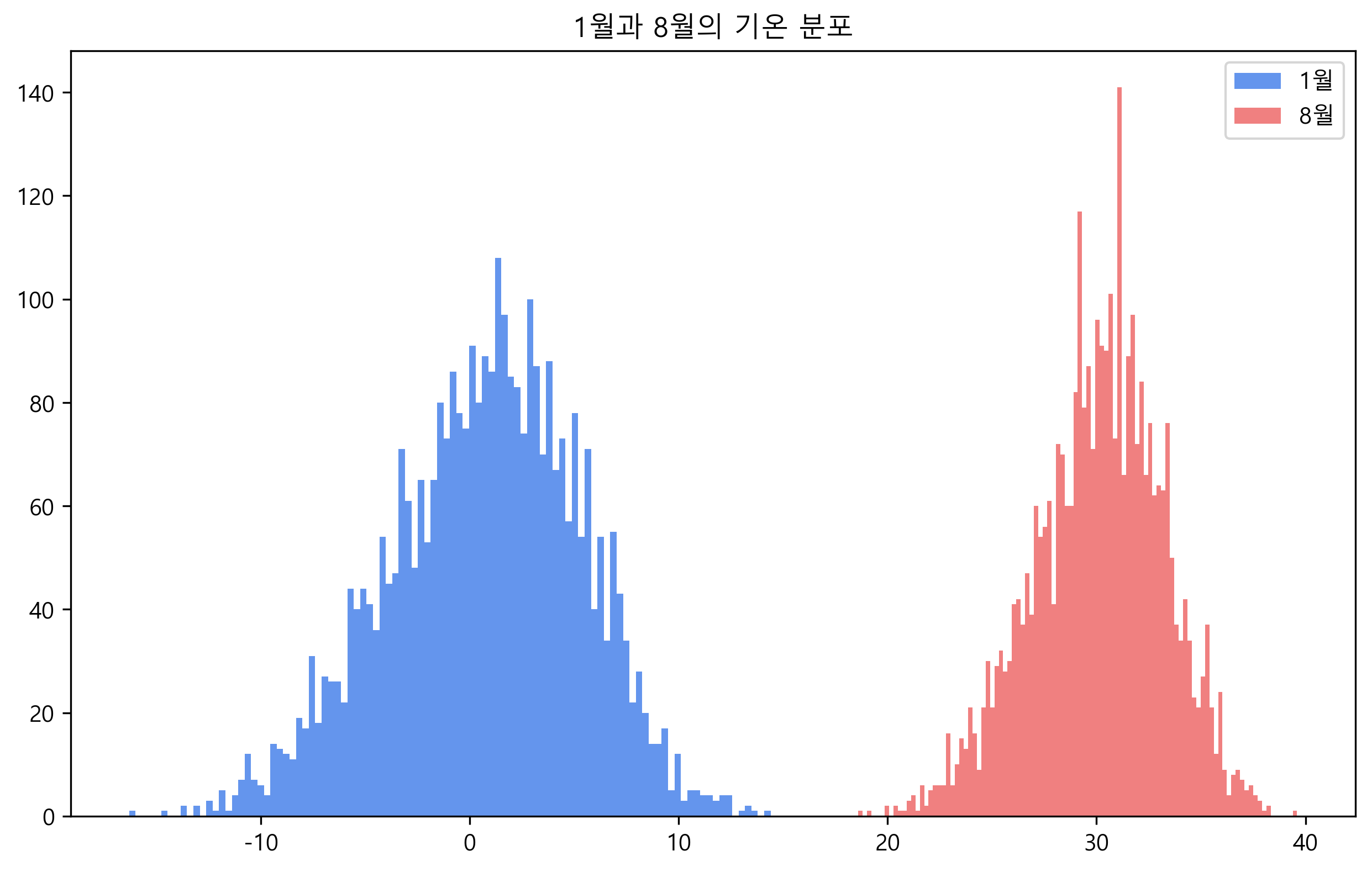
🌡️ 서울 기온 데이터 분석
- 우선 어떤 데이터든지 가져오게 되면, 먼저 결측치를 살펴보고, 그 다음에는 이상치, 분포를 확인하는 순으로 진행하는 것이 좋습니다.
🫱🏻 1. 데이터 읽어오기 (csv 모듈)
💡 csv.reader(csvfile, delimiter=None)
- csv 파일의 데이터를 읽어오는 함수입니다.
- delimiter는 delimiter에 지정된 속성을 기준으로, 분리해서 읽어오라는 의미를 담고 있습니다.
- 이 reader() 함수는 기본적으로 한 줄을 읽어 해당 줄을 list 형태로 변환합니다.
csv 파일의 마지막 줄은 항상 '\n'로 끝나야 하는데,
그 이유는 '\n'으로 끝나지 않게 되면 reader()가 마지막 행을 구분하지 못하기 때문입니다.
💡 next(iterator)
- 파이썬에 있는 내장 함수로, next() 함수는 실행할 때마다 한 행씩 반환하면서 데이터를 pass! 시켜주는 함수입니다.
- 데이터를 읽어올 때, header, 즉 특정 컬럼명을 건너뛰고 싶을 때 주로 사용되고, 저희 실습 때도 이를 위해 사용되었습니다.
🙅🏻♂️ 2. 결측치 처리
- 실습을 진행하다보니 결측치가 발생하여 형 변환이 되지 않는 경우가 발생했었습니다.
- 해당 결측치들은 다음 두 방식 중 하나를 선택하여 처리할 수 있겠습니다.
- 해당 데이터를 삭제하거나,
- 결측치를 최대, 최소, 평균, 혹은 임의의 값으로 대체하는 방법
- 저희는 이 중에서 최대, 최소값으로 결측치를 대체해보는 작업을 진행했습니다.
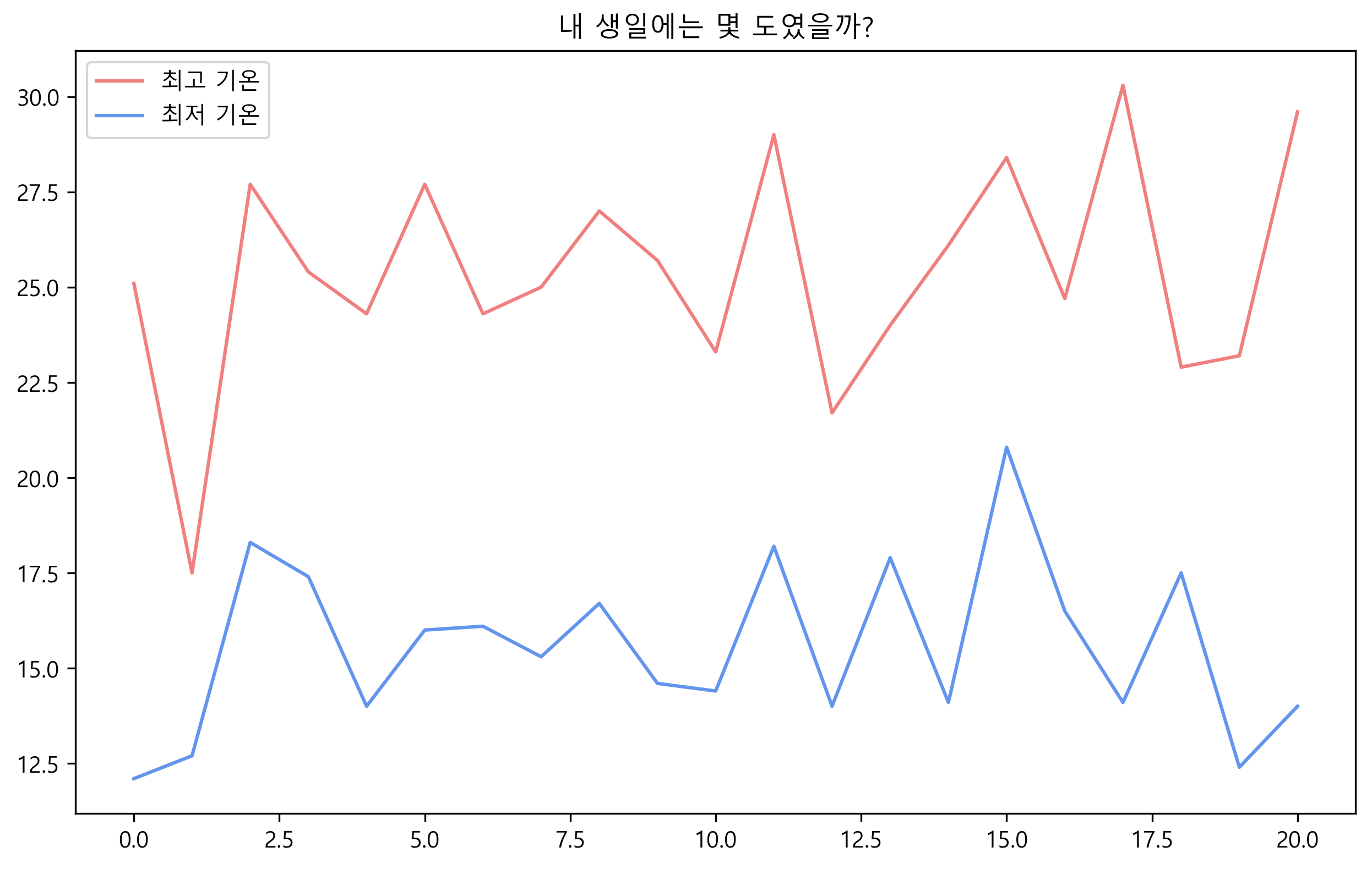
🎂 3. 각 연도별로 내 생일에 해당하는 데이터 추출 후 시각화
- 데이터에는 날짜('2019-01-01' 형식)도 포함되어 있기 때문에 이를 적절히 split하여 year, month, day로 구분하였습니다.
- 이 중 제가 태어난 해 이후로, month와 day가 제 생일과 일치할 때만 데이터를 추출했고, 이를 시각화한 결과는 하단 이미지와 같습니다.
🚇 지하철 시간대별 승하차 인원 추이 분석
- 후반부에 강사님께서 저희한테 직접 분석하여 시각화해봐랏!! 하셔서 직접 진행해 보았습니다.
✨ 1. 주어진 데이터 확인

- 우선 주어진 데이터는 위와 같이 쭉 나열되어 있고, 특이하게도 오전 4시부터 오전 3시까지의 승하차 인원을 보여주고 있었습니다. 아무래도 첫차와 막차 기준인 것 같습니다.
- 결과적으로 제가 가져와야할 것은 시간대별 승하차 인원의 합계였습니다.
- 저 csv 파일을 기준으로 보게 된다면, E열의 승차 인원 합산 후 승차 인원 리스트에 저장, G열의 승차 인원 합산 후 승차 인원 리스트에 저장..., 그리고 하차 인원도 마찬가지로 진행해야했습니다.
- 이를 위해 저는 먼저 이 합산 인원들을 담아낼 빈 리스트를 선언했습니다. 심플하게 승차 인원을 up, 하차 인원을 down이라고 하겠습니다.
✨ 2. 저장 리스트 선언
import csv
import matplotlib.pyplot as plt
file = open('./data/subwaytime.csv')
data = csv.reader(file)
next(data)
next(data)
up = [[] for _ in range(24)]
down = [[] for _ in range(24)]- 위 코드에서 next(data)를 두 번 실행한 이유는 저는 이미 어느 열이 승차 인원이고, 어느 열이 하차 인원인지 알고 있었기에 컬럼명과 승하차 구분 행을 건너뛴 후부터 데이터를 살피고자하기 위함이었습니다.
- 그 후 강사님께서 이미 구현하신 그래프를 살펴보니 x축이 오전 4시부터 시작하고 있었기에, 저는 up 리스트 첫 번째 요소에 오전 4시 데이터를 집어 넣어야했습니다.
- 이에 따라 인덱스를 살짝 계산하여 조정하는 과정이 필요했습니다.
✨ 3. 인덱스 조정 후 저장
for row in data:
for i in range(4, 52, 2):
index = (i-4) // 2
up[index].append(int(row[i]))
for i in range(5, 53, 2):
index = (i-5) // 2
down[index].append(int(row[i]))
- 이렇게 계산하여 각 리스트에 넣게 되면 해당 승하차 인원들만 구분되어 들어가게 됩니다.
- 이제 리스트에는 구분된 승하차 인원 수들이 담겼기 때문에 이를 한꺼번에 보여주기 위해 합산을 진행해야 합니다.
- 참고로 강사님께서는 map() 함수를 이용하여 다음과 같이 간단히 구현해주셨습니다.
up = [0] * 24
down = [0] * 24
for row in data:
row[4:] = map(int, row[4:])
for i in range(24):
up[i] += row[4+i*2]
down[i] += row[5+i*2]
✨ 4. 리스트 순회하며 합산
up_sum = [sum(hour) for hour in up]
down_sum = [sum(hour) for hour in down]- 리스트에 추가된 각 시간대별 리스트가 합산되어 특정 리스트(up_sum, down_sum)에 다시 담기게 되었습니다.
- 이제 시각화할 데이터는 모두 구축 완료했고! 이제 시각화만이 남았습니다.
✨ 5. 시각화 과정
labels = [f'{i}시' if i <= 24 else f'익일 {i-24}시' for i in range(4, 28)]
plt.rc('font', family='Malgun Gothic')
plt.figure(figsize=(10, 6), dpi=300)
plt.plot(range(4, 28),
up_sum,
label='승차',
color='lightcoral',
linewidth=2,
marker='o',
markersize=5,
alpha=0.8)
plt.plot(range(4, 28),
down_sum,
label='하차',
color='cornflowerblue',
linewidth=2,
marker='s',
markersize=5,
alpha=0.8)
plt.title('지하철 시간대별 승하차 인원 추이')
plt.xlabel('시간대', fontsize=12)
plt.ylabel('인원 수', fontsize=12)
plt.xticks(range(4, 28), labels=labels, rotation=45)
plt.legend()
plt.grid(True, linestyle='--', linewidth=1)
plt.show()- 라인 그래프를 요구하셨기 때문에 이에 해당하는 plot() 함수의 속성과 설정 및 장식 함수들을 적절히 사용해서 시각화를 진행했습니다.
- x축의 tick들이 4부터 27까지 보여졌기 때문에, 이런 식으로 나타내게 되면 보는 사람들은 x축이 시간이라고 생각하지 못할 수도 있을 듯 싶었습니다. 그래서 임의로 labels를 지정해 xticks() 함수에 넘겨주었습니다.
- 결과는 하단과 같이 보여지게 됩니다.
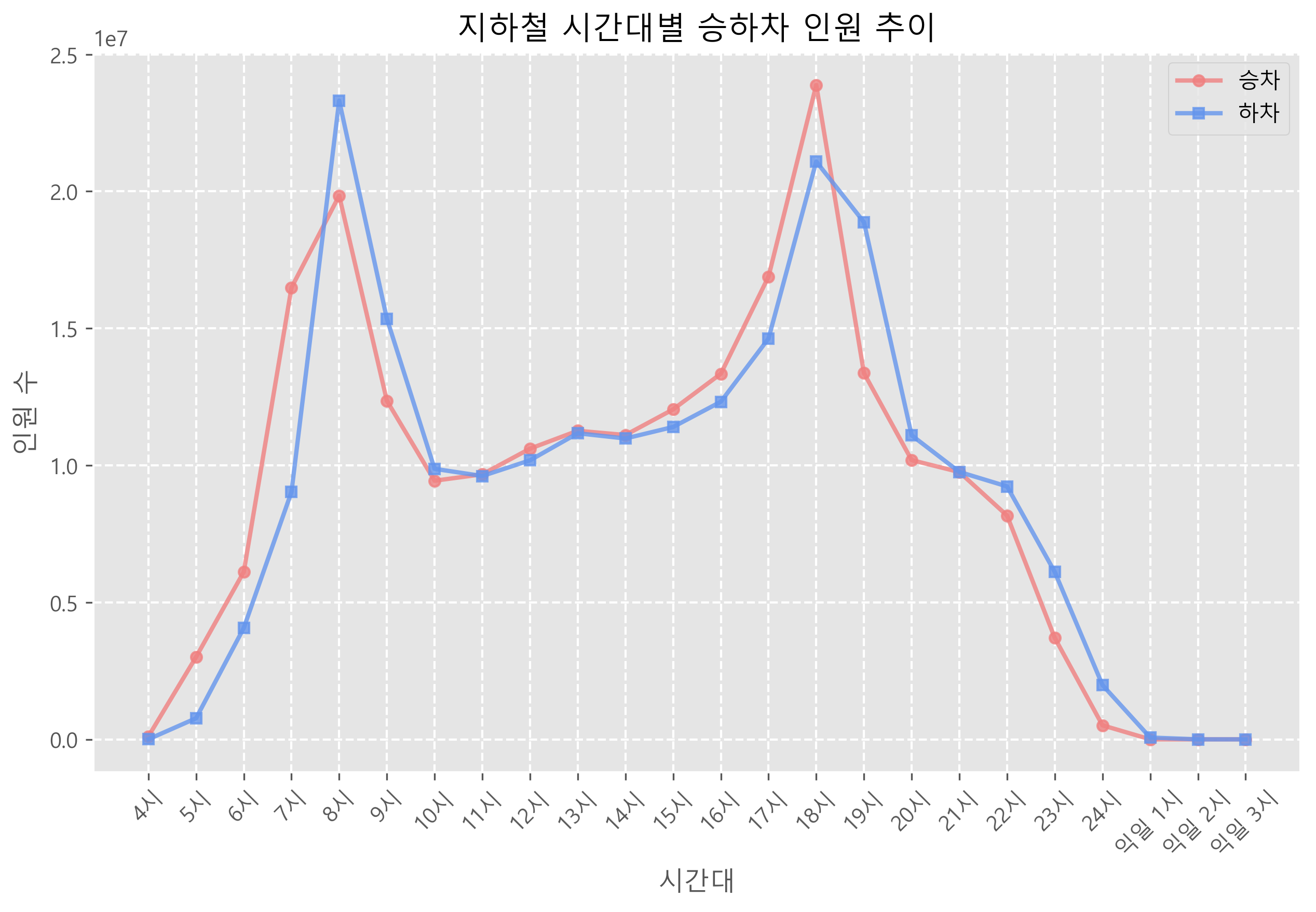
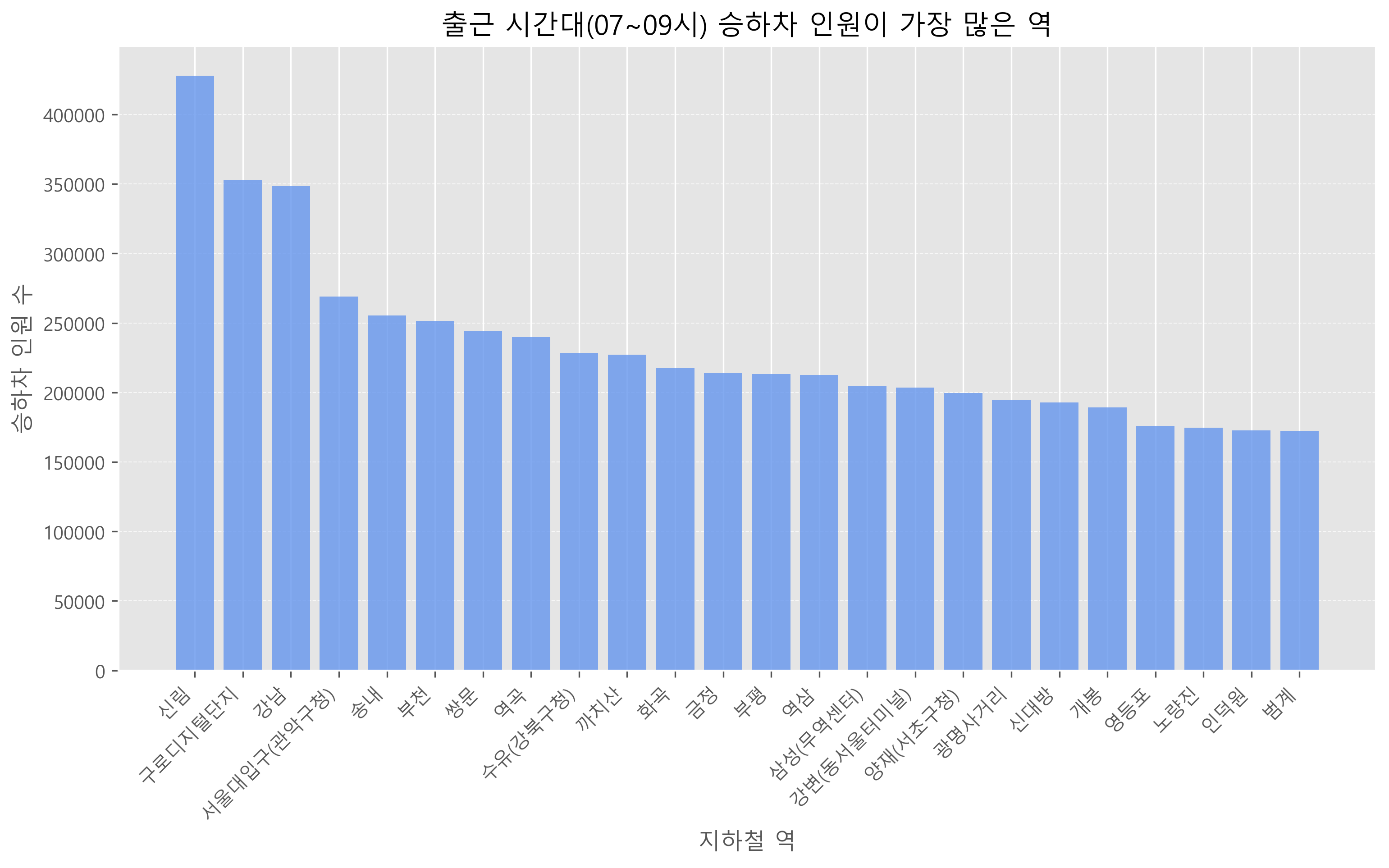
- 추가적인 과제로 요런 그래프로 그려보았습니다.
🤔 8일차 회고
- 오늘 수업의 주 목적은 여러 데이터들을 여러 그래프로 시각화하는 데 있었습니다.
- 분명 전에 다 해봤던 내용들이긴 한데, 세부적(docs나 관련 자료 등)으로도 살펴보고, 리마인드도 해보면서 시각화에 대한 지식을 확장해갈 수 있었습니다.
- matplotlib으로 그릴 수 있는 plot들은 다 그려본 것 같은데, 그럼에도 한참 남은 느낌이고...
- 오늘 하루 분량만으로도 이토록 많은 내용들을 배울 수 있어서 너무나도 영광이었습니다. 🙇🏻♂️ 충분히 알차고 생산적인 시간이었습니다!
- 이제 점점 심화 단계로 들어가는 중인 것 같은데, 하루 빨리 교육을 마치고 프로젝트에 돌입하고 싶은 마음이 큽니다. 배울수록 더 활용하고 싶은 욕구가 커지나 봅니다... ✨
- 내일도 오늘과 같은 데이터 시각화 작업을 계속해서 진행할 예정입니다.
728x90
LIST
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 Python 이론 살짝 업글해보기 (4) | 2025.02.11 |
|---|---|
| 🤔 Numpy와 Seaborn 그리고 또다시...각화 (0) | 2025.02.07 |
| 🤔 Series와 DataFrame 그리고 Pandas (1) | 2025.02.06 |
| 🤔 함수와 모듈 그리고 클래스 (15) | 2025.02.04 |
| 🤔 Python Programming Basics (w. Spyder) (2) | 2025.02.03 |