
728x90
SMALL

- 오늘은 파이썬의 전반적인 기초 지식들, 그리고 기초적인 데이터 분석 관련 실습을 진행하였습니다.
🐍 Python의 기초
- Python이든 다른 프로그래밍 언어에서든 배우기 전에 알고 있어야 할 중요한 요소들이 있습니다.
✨ 중요 요소들
💡 변수
- 하나의 값(단일 값)을 저장하는 것을 뜻하며, 변수에는 단일 값만이 들어갈 수 있습니다.
- 이 변수들을 최대한 적게 써야 메모리를 최적화할 수 있습니다. 이를 잘 기억해서 추후에는 메모리의 효율성을 잘 고려하는 개발자가 되어야 하겠습니다.
- 주로 외부 데이터(.csv, .xls, .spss, .db, .txt, .json 등)를 변수로 받아서 처리하게 됩니다.
💡 조건문
- if라는 키워드를 통해 조건을 달아주는 요소입니다!
- if-else, if-elif-else 구조로 확장하여 나타낼 수 있습니다.
💡 반복문
- 동일한 내용을 반복적으로 수행시키고자 할 때 사용하는 요소입니다!
- for 변수 in 다중값: 과 같이 나타내어 표기합니다. 여기서 다중값은 보통 리스트([0, 1, 2, 3] 등)를 나타냅니다.
- 반복문 내부에 선언된 변수들은 반복문의 외부에서 사용할 수 없습니다.
💡 배열
- 파이썬에서는 리스트로 표현되는 변수입니다. 즉, 변수들이 담아져있는 변수라고 보시면 됩니다.
- 가로 형태로 나열되어 있는 형태입니다.
- 배열에 있는 값(데이터)들은 인덱스를 통해 접근할 수 있습니다.
- 이 배열의 인덱스는 0부터 1씩 증가하는 형태로 주어집니다.
- 인덱스는 왼쪽에서 오른쪽으로 갈 때에는 0번부터, 오른쪽에서 왼쪽으로 갈 때에는 -1번부터 진행이 됩니다.
- 리스트의 슬라이싱은 추후 데이터를 다룰 때에도 정말 다양한 방식으로 사용되니 명확하게 알고 있어야 합니다!
💡 함수
- 코드를 더욱 체계적으로 사용하기 위해 사용하는 요소입니다.
- def 키워드를 통해 함수를 선언할 수 있습니다.
💡 클래스
- 함수들을 모아놓는 저장소입니다.
⚠️ 주의점
- Python은 들여쓰기(indent)에 민감한 언어이기 때문에 띄어쓰기나 탭(Tab)을 아주 잘 활용하셔야 합니다.
- 다른 언어들처럼 세미콜론(;)을 문장 끝에 찍지 않습니다.
- 다른 언어들과 달리 Boolean(논리 변수)들이 True, False와 같이 대문자로 시작합니다.
🤯 연산자 중 //, %
- //는 몫, %는 나머지를 구하기 위한 연산자입니다.
- 이들로 이루어진 연산의 결과값은 무조건 소수가 아닌 정수로 나타날 수 밖에 없습니다.
- 보통 은행권에서 데이터를 표현할 때 가장 많이 사용되는 연산자들입니다.
📌 중요 내장 함수
✨ type()
class type(object)- 변수나 객체의 내부 형태를 우리에게 알려주는 함수입니다.
- 인수 하나(위 코드에서 object)로 해당 object의 유형을 반환합니다.
- 반환 값은 객체의 타입(유형)이며 일반적으로 object.__class__에서 반환된 것과 동일한 객체입니다.
✨ input()
input(prompt)- 결과값은 무조건 문자열로 반환됩니다.
- prompt 인자가 있으면, 끝에 개행 문자를 붙이지 않고 입력창에 prompt를 같이 보여주게 됩니다.
- 그런 다음 함수는 입력에서 한 줄을 읽고, 문자열로 변환(줄 끝의 줄 바꿈 문자 제거한 뒤)해서 반환해줍니다.
- 파일의 끝을 읽게 되면 EOFError를 일으킵니다.
✨ range()
class range(start, stop[, step])- 범위를 만들어 하나씩 꺼내주는 역할을 해주는 함수입니다.
- range에 대한 인수는 정수(내장 int 또는 특수 메소드를 구현하는 모든 객체 __index__())여야 합니다.
- 여기서 step 인수가 생략되면 기본값 1로 설정되고, start 인수가 생략되면 기본값 0으로 설정됩니다.
- step이 0이면 ValueError가 발생합니다.
✨ split()
str.split(sep=None, maxsplit=-1)- 검색어 및 자연어 처리에서의 기본 코드에서 주로 사용됩니다.
- sep의 기본값은 None이며, 이때의 동작은 띄어쓰기나 엔터를 구분자로 하여 문자열을 분할하게 됩니다.
- ‘문자열’.split(sep=',')이라고 작성한다면 문자열에서 ,(콤마)를 기준으로 문자열을 자릅니다.
- sep은 생략하고 문자열.split(',')으로 사용해도 무방합니다.
📖 다중 값인데 리스트 말고 딕셔너리
- 딕셔너리의 키는 고유해야 합니다. 즉, 중복 키를 가질 수가 없습니다.
- 딕셔너리 내 없는 키에 값을 할당하려고 하면, 자동으로 해당 키와 할당되는 값이 추가됩니다.
✨ 관련 함수들
💡 keys()
- 딕셔너리 키들의 모음을 반환합니다.
- 키를 직접 출력하기 위해서는 해당 dict.keys()를 list()로 변환해야 합니다.
💡 values()
- 딕셔너리 값들의 모음을 반환해줍니다.
- 값을 직접 출력하기 위해서는 해당 dict.values()를 keys()와 같이 list()로 변환해야 합니다.
💡 items()
- 딕셔너리 항목들((key, value) 쌍들)의 모음 튜플(요소들의 중복이 없는) 형태로 반환합니다.
💡 sorted()
sorted(iterable, /, *, key=None, reverse=False)
- iterable(다중 값)의 항목들로 오름차순으로 정렬된 리스트를 반환합니다.
- 키워드 인자로만 지정해야 하는 두 개의 인자가 존재하는데, 하나는 key, 하나는 reverse입니다.
- key는 하나의 인자를 받는 함수를 지정하는데, iterable(다중 값)의 각 요소들로부터 비교하는 키를 추출하는 데 사용됩니다. 추후 더 자세히 다뤄보겠습니다.
- reverse는 논리값으로, True가 설정되면, 내림차순으로 요소들이 정렬되어 리스트로 반환됩니다.
📊 데이터 분석 기초
- 파이썬으로 데이터(.csv) 파일을 불러오기 위해 먼저 csv 라이브러리를 import하고 관련 함수를 활용했습니다.
- 데이터는 신용 카드 이용 내역 데이터로, 사용 날짜, 가격, 사용처 등이 포함되어 있습니다.
✨ 데이터 불러오기
# csv 라이브러리 import
import csv
f = open('card.csv') # 파일 오픈
data = csv.reader(f) # 파일 읽기 reader
next(data) # 파일 헤더 건너뛰기
data = list(data) # 파일 리스트로 바꾸기
print(data[0])
# 출력 결과
# ['2019-10-12 9:13', '1972753', '본', 'S&', '185', '네이버파이낸셜(주)', '546800', '일시불(A)', '부분취소']- open 함수는 python 내장 함수로 파일이 오픈되어있는지에 대한 상태를 반환해줍니다.
- reader 함수는 csv 라이브러리에 포함되어있는 함수로, 상태에 따라 해당 파일의 값들을 반환해줍니다.
- next 함수는 data를 다음으로 넘기고, 넘어간 데이터는 삭제하는 함수이기 때문에 주의해서 사용해야 합니다.
✨ 데이터를 시각화해보기
💡 월별 지출액
- 10~12월의 월별 지출액을 시각화하기 위한 프로그램의 흐름을 생각해보자면,
- 10~12월의 월별 지출액을 저장할 리스트(monthly_expenses)를 만들고 초깃값을 0으로 저장합니다.
- 전체 이용 내역(data)을 돌며 아래 내용을 반복합니다.
- 각 이용 내역에서 매입 상태가 '전표매입'이라면,
- 해당 건의 이용월과 이용 금액을 구하고,
- 이용 월에서 10을 뺀 후(인덱스에 접근하기 위해), 월별 지출액 리스트(monthly_expenses)의 인덱스(idx)를 구한 뒤,
- 구한 인덱스의 값(monthly_expenses[idx])에 구한 이용 금액을 더해줍니다.
- 각 이용 내역에서 매입 상태가 '전표매입'이라면,
- 월별 지출액 리스트(monthly_expenses)로 막대그래프를 그려줍니다.
- 위와 같기 때문에 위 흐름의 2번 과정까지를 코드로 나타내면 다음과 같습니다.
monthly_expenses = [0, 0, 0]
for row in data:
if row[-1] == '전표매입':
month = int(row[0].split('-')[1])
idx = month - 10
payment = int(row[6])
monthly_expenses[idx] += payment
print(monthly_expenses)
# 출력 결과
# [2093015, 4127744, 1953269]- 그리고 최종적으로 이를 시각화하려면 matplotlib.pyplot의 도움을 받아야 합니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 7), dpi=100)
plt.rc('font', family='NanumGothic', size=12)
plt.bar(['10월', '11월', '12월'], monthly_expenses, color='cornflowerblue', edgecolor='navy', alpha=0.7)
for i, v in enumerate(monthly_expenses):
plt.text(i, v, f'{v:,}원',
ha='center', va='bottom',
fontweight='bold',
fontsize=10)
plt.title('10~12월 지출 현황', fontsize=16, fontweight='bold')
plt.ylabel('지출액', fontsize=12)
plt.gca().yaxis.set_major_formatter(plt.FuncFormatter(lambda x, p: format(int(x), ',')))
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()- 수업에서 기본으로 제공되는 코드에 제가 임의로 조금 더 옵션을 붙여 만든 코드입니다. 자세한 코드 설명은 추후에 본격적으로 데이터 분석에 들어갈 때 추가해두겠습니다.
- 최종적으로 시각화된 plot은 아래 이미지와 같습니다!

💡 월별 택시 이용 금액
- 10~12월의 월별 택시 지출액을 시각화하기 위한 프로그램의 흐름을 생각해보자면,
- 10~12월의 월별 택시비 지출액을 저장할 리스트(taxi)를 만들고 각 월별 택시 지출액의 초깃값을 0으로 저장합니다.
- 전체 이용 내역(data)을 돌며 아래 내용을 반복합니다.
- 각 이용 내역에서 매입 상태가 '전표매입'이고, 가맹점명에 '택시'가 있다면,
- 해당 건의 이용월과 이용 금액을 구하고,
- 이용 월에서 10을 뺀 후(인덱스에 접근하기 위해), taxi의 인덱스(idx)를 구한 뒤,
- 구한 인덱스의 값(taxi[idx])에 구한 이용 금액을 더해줍니다.
- 각 이용 내역에서 매입 상태가 '전표매입'이고, 가맹점명에 '택시'가 있다면,
- 마지막으로 월별 지출액 리스트(taxi)로 라인 그래프를 그립니다.
- 위와 같기 때문에 위 흐름의 2번 과정까지를 코드로 나타내면 다음과 같습니다.
taxi = [0, 0, 0]
for row in data:
if row[-1] == '전표매입' and '택시' in row[5]:
month = int(row[0].split('-')[1])
payment = int(row[-3])
idx = month - 10
taxi[idx] += payment
print(taxi)
# 출력 결과
# [8600, 83900, 52800]- 그리고 이를 시각화하기 위해 또다시 라이브러리의 힘을 빌리면...!
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(12, 7), dpi=100)
plt.rc('font', family='NanumGothic', size=12)
plt.title('10~12월 택시/배달음식 지출 현황', fontsize=16, fontweight='bold')
plt.plot(['10월', '11월','12월'], taxi, color='crimson', label='택시 지출액', marker='o')
plt.plot(['10월','11월','12월'], deli, color='indigo', label='배달음식 지출액', marker='s')
plt.ylabel('지출액', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.legend()
plt.tight_layout()
plt.show()- 다음과 같이 시각화할 수 있습니다! 해당 plot에는 배달 음식 지출까지도 시각화가 되어있는 상태입니다.

🔥 핫플레이스 데이터 분석
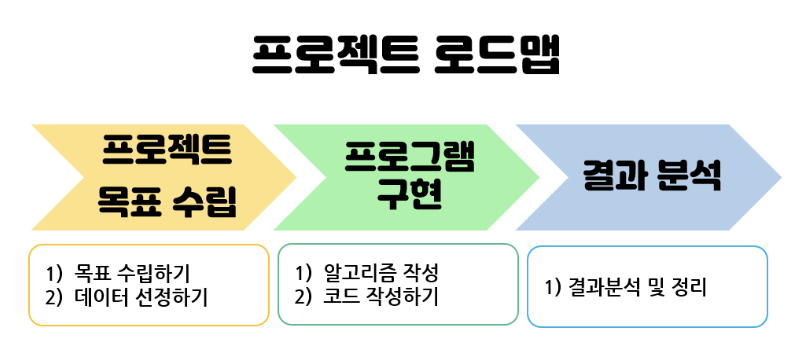
- 주어진 프로젝트 로드맵에 따라 간단한 프로젝트 실습을 진행했습니다.
- 프로젝트의 목표는 핫플레이스를 언제 가야 가장 덜 붐빌지를 찾아내는 것이었습니다.
- 오늘은 사용자로부터 행정동명을 입력받고, 대응되는 행정동 코드를 데이터에서부터 찾아내는 것과,
- 프로젝트의 하위 목표를 '핫플레이스가 있는 행정동의 시간대별 평균 인구 그래프를 그려 분석하는 것'으로 설정하는 것까지 진행하였습니다!
- 분석과 추가 하위 목표의 세부 코드는 내일 이어서 진행될 것 같습니다. :)
🤔 3일차 회고
- 오늘 수업에서는 파이썬 관련하여 정말 기초적인 부분과 데이터 분석 부분도 살짝(?) 다뤄보았습니다.
- 저는 사실 학교에서 대부분의 수업을 파이썬으로 진행하였고, 전공도 데이터사이언스인지라 수업이 지루할 수 있었는데, 강사님께서 정말 세부적인 부분까지 깊게 설명해주시는 덕에 시간 가는 줄 모르고 리마인드했던 것 같습니다.
- 데이터 시각화하는 부분에 있어서는 제가 코드를 조금씩 커스텀하는 방식으로 진행하였는데, 이 또한 제가 예전에 배우던 내용들이 새록새록 기억나면서 다시금 데이터를 다루는 것에 흥미를 가지게 하는 기분이 들었습니다.
- 내일은 오늘에 이어서 folium, tkinter 라이브러리 등을 이용한 실습 및 추가적인 데이터 분석에 대해 살펴볼 예정입니다.
728x90
LIST
'부트캠프 > LG U+' 카테고리의 다른 글
| 🤔 함수와 모듈 그리고 클래스 (15) | 2025.02.04 |
|---|---|
| 🤔 Python Programming Basics (w. Spyder) (2) | 2025.02.03 |
| 🤔 Jupyter, folium 그리고 tkinter (2) | 2025.01.24 |
| 🤔 보안 그룹과 EBS 그리고 ELB (10) | 2025.01.22 |
| 🤔 클라우드와 AWS 그리고 EC2 (2) | 2025.01.21 |