
728x90
SMALL
- 학기 중(23.11.07 ~ 23.12.13) 진행된 Process Mining Project를 간단히 정리하고자 합니다.
1. Introduction
1.1 Research Question
- 일상 속 발생하는 처방 오류를 효과적으로 줄일 수 있는 방법이 있을까?
- 처방 오류를 줄이기 위해서 환자들도 약품에 관한 지식이 필요하지 않을까?
- 처방 오류의 특징을 어떻게 효과적으로 식별할 수 있을까?
1.2 Describe Dataset
- 데이터 출처 : https://physionet.org/content/mimiciv/2.2/#description
- 데이터 구조 : 프로젝트에 사용된 주요 컬럼들은 다음과 같습니다.
| subject_id | 환자의 고유 ID | chiefcomplaint | 입원 주요 원인 |
| activity | 환자의 활동 | name | 약품명 |
| timestamp | 활동 시작 시간 | gsn | 약품 성분 분류 코드 |
| icd_code | 질병 분류 코드 | med_rn | 약물 분배 분류 순서 |
| icd_title | 질병명 | etcdescription | 처방전 |
- MIMIC-IV 데이터는 중환자실 환자들을 대상으로 하는 데이터입니다.
- 이 중 제가 사용한 데이터로는 event log 데이터로, 각 환자의 입원에서부터 퇴원까지의 과정을 담은 데이터를 사용하였습니다.
1.3 Data Preprocessing
- 데이터가 대략 720만 건이기에 Colab 환경에서의 원활한 진행을 위해 원데이터의 1/4씩 분석을 진행하였고, 이후 통합 과정을 거쳤습니다.
- 사용되지 않는 feature들은 제거하였습니다. (stay_id, race, disposition 등)
- 'Medicine reconciliation' 활동에서만 처방전 feature가 존재했습니다. 이는 환자가 이전에 사용했던 약물이 어떤 처방전을 통해 제공되었는지를 나타내는 활동이기에 이 활동과 더불어 처방 과정인 'Medicine dispensations' 활동을 주로 분석하였습니다.
- 위 두 활동의 gsn feature를 비교하여 같은 것들 즉, 전에 사용되었던 약품이 처방된 경우만을 filtering하여 데이터를 구성하였습니다.
2. Analysis
2.1 Process
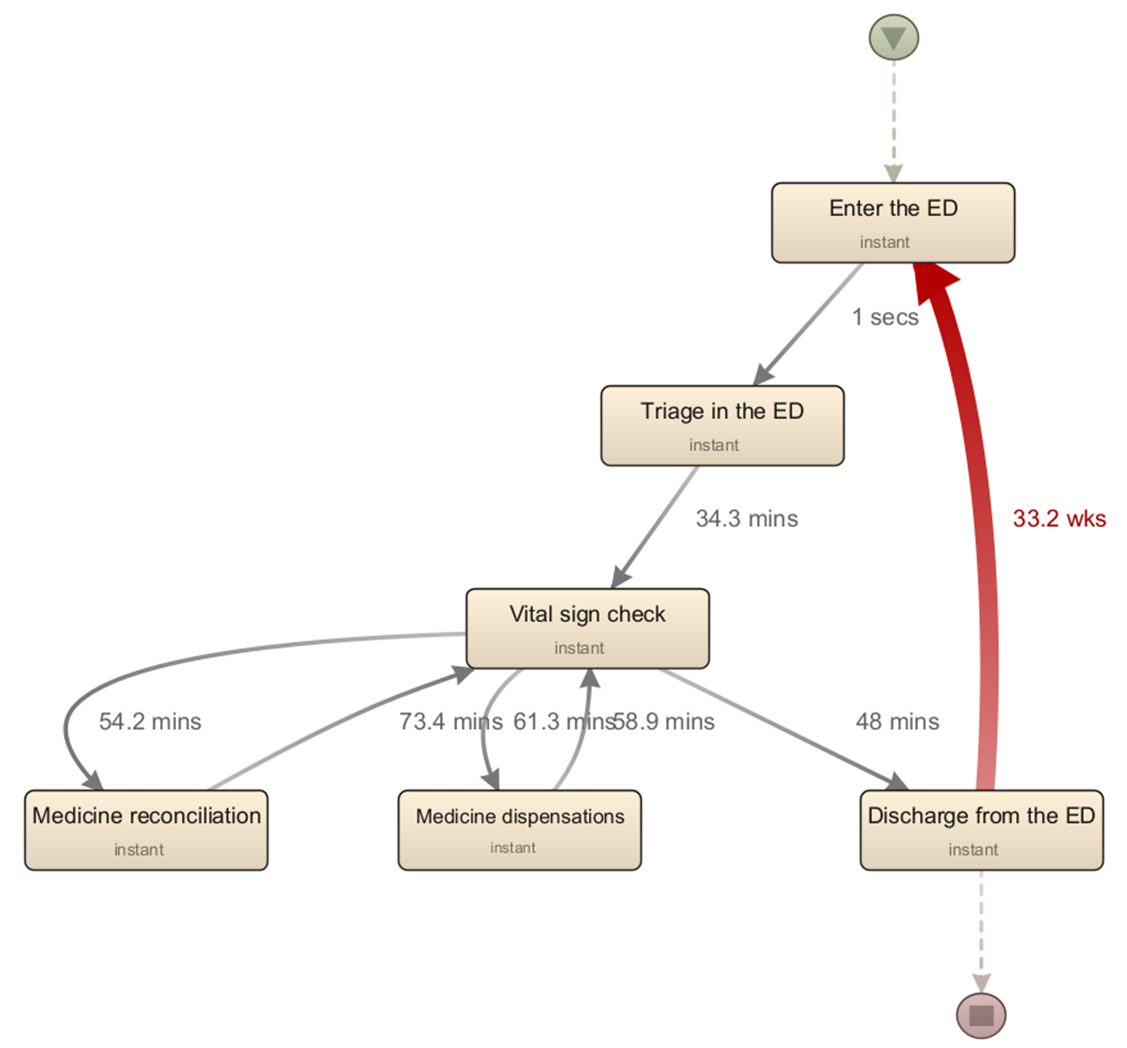
- 본격적인 분석에 앞서 프로세스 분석을 진행해본 결과, 처방 과정에서 다음 활동으로 넘어가기까지의 시간이 대략 60분(1시간) 정도 소요되는 것을 알 수 있었습니다.
- 분석에는 DISCO 분석 툴을 사용하였습니다.
2.2 Similarity
- icd_title과 etcdescription의 텍스트 데이터를 TF-IDF 벡터화시킨 후, 이 둘로 코사인 유사도를 측정해보았습니다.
- 즉, 병명과 처방전의 유사도를 분석하여 어떤 질병에 어떤 처방이 이루어졌는지, 이를 통해 어떤 약품이 쓰였는지를 분석하였습니다.
- 예를 들어 가장 높은 유사도를 보인 약품(Doxycycline Hyclate)은 일종의 항생제인데, 유사도가 높을수록 처방전의 정보가 해당 약품을 처방하는 데 있어 관련이 있을 것이라고 판단하였습니다.

2.3 Case
- 위 유사도를 가지고 처방 오류의 가능성을 지닌 케이스들을 분석해보았습니다.
- 유사도가 낮은 경우, 질병과 관련 없는 약품을 처방했다고 가정하여 이를 오류의 가능성이 있다고 판단하였습니다.
- 표준 유사도를 정해 이 유사도 미만인 케이스에 대하여 분석을 진행하였고, 이는 다음과 같습니다.

- 결과적으로, 뇌전증에 사용되는 항경련제(Gabapentin)를 처방할 때의 케이스가 눈에 띄었고, 그 이후로도 다양한 약품들에서 오류의 가능성이 발견되었습니다.
2.4 Case Comparison
- 이 중 몇 가지 약품들만을 선별하여 오류라고 판정된 케이스들과 오류를 제외한 나머지 케이스들을 비교해보았습니다.
- 예를 들어 오류로 판정된 케이스가 대략 50건인 항염증제의 경우, 처방하고 퇴원하는 과정에 있어서 평균적으로 걸리는 시간의 차이가 있었음을 알 수 있었습니다.
- 이외 약품들에서도 이러한 시간적인 차이가 근소하게 확인되었으나, 시간을 제외한 외부적인 요인들을 다 파악할 수는 없었습니다.

3. Limitation / Consequence
3.1 Limitation
- activity마다 주어지는 feature들이 다르기 때문에 데이터를 전처리하는 과정에서 시간 소요가 상당했습니다.
- 약품마다 어떤 성분이 포함되어 있는지에 대한 세밀한 추가 데이터가 필요해보입니다.
- 가정에 의한 진행이 대다수였기에, 도메인 전문가의 의견에 따라 수정해야할 부분이 다수 존재합니다.
3.2 Consequence
- 일부 약품에서 처방 오류라고 판정된 케이스들이 발견되었습니다. 오류가 발생된 원인으로 처방 과정에 걸리는 시간도 있겠지만, 처방 과정에 있어 다양한 외부적 요인이 발생하기 때문에 이는 전문가의 추가적인 의견이 필요한 상태입니다.
- 성분을 통한 처방 오류의 접근은 좋았으나, 약품 성분 데이터가 빈약했습니다. 추가적인 데이터가 결합된다면 과용량 처방에 대한 방지나, 중환자들이 아닌 일반 환자들에게도 적용시킬 수 있을 것 같습니다.
728x90
LIST