
728x90
SMALL

- 오늘은 파이썬과 MySQL을 둘 다 이용해서 야후 파이낸스 주식 데이터를 가지고 분석해보는 시간을 가져보았습니다.
- 참고로 중간중간 제작된 이미지는 https://www.napkin.ai/에서 생성한 이미지로, 앞으로도 유용하게 사용할 것 같습니다. 👍🏻
Napkin AI - The visual AI for business storytelling
Just type, copy-paste or generate your text and Napkin will instantly transform it into insightful visuals. Make your communication more effective with Napkin.
www.napkin.ai
🫙 크롤러로 데이터 수집 후 저장하기
- 분석하기 전에 분석할 데이터가 필요하기 때문에 야후 파이낸스에서 크롤러를 통해서 데이터를 가져올 예정입니다!
- 크롤러로 데이터를 가져오고 저장하는 순서는 간단하게 다음 그림처럼 표현할 수 있겠습니다.

🌱 DB 먼저 생성해주기
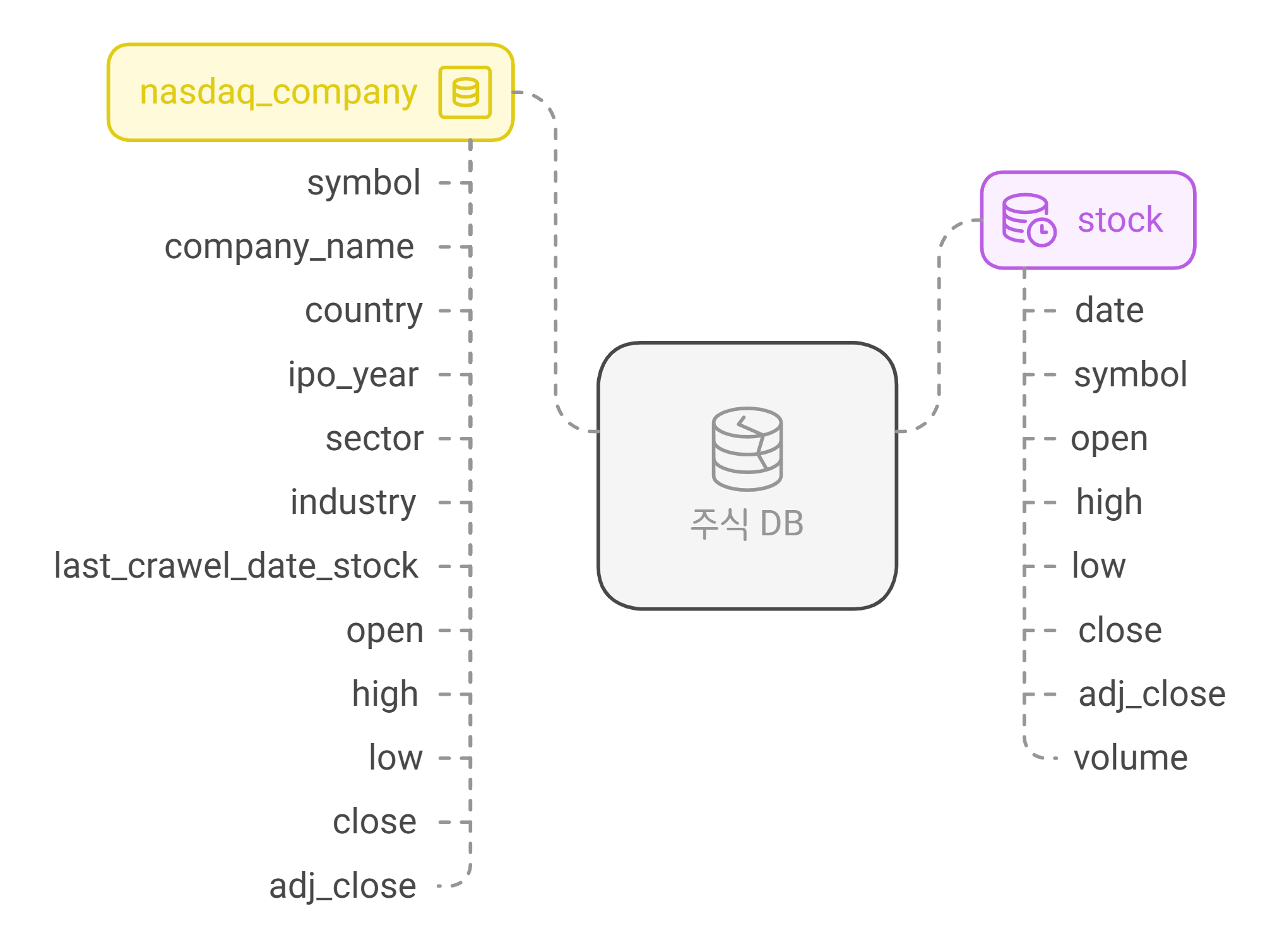
- 위 크롤링 작업들을 거치기 전에 DB 스키마와 기초적인 데이터를 넣어주기 위한 테이블을 생성해주었습니다.
- 테이블은 총 2개인데, 하나는 nasdaq_company로 이 테이블에는 기업 정보, 그리고 두 번째 테이블인 stock에는 1일 주식 정보를 저장하려고 합니다.
🌐 파이썬 웹 크롤러로 데이터 저장하기!
- 이제 기본적인 세팅은 완료했으니 크롤러를 만들어보겠습니다!
- 저희는 yfinance 라이브러리를 호출해서 주식 API를 통해 데이터를 수집하고 가공해서 MySQL 서버로 데이터를 저장하는 역할을 부여해줬습니다.
- 그런데 이 yfinance는 결과값이 DataFrame 형태로 반환되지 않기 때문에 특정 변수에 저장을 해준 다음에 거기서 특정 데이터들을 뽑아내서 다시 저장해주어야 합니다.

💡 필요한 라이브러리 가져오기
- 야후 파이낸스에서 제공하는 주식 데이터를 가져오기 위한 yfinance, python과 sql을 연결해주는 pymysql, 마지막으로 날짜 데이터들을 조작하기 위한 datetime 라이브러리를 import 해주었습니다.
💡 MySQL 접속 정보 입력 후, 관련 함수 생성하기
- 접속 정보(호스트, 사용자명, 비밀번호, 데이터베이스 이름)를 미리 변수에 할당하고, pymysql.connect()로 연결을 생성해줍니다.
- 데이터를 수집하고 처리해서 저장하기 위해 관련 함수를 총 2개 생성하였습니다.
- 하나는 getStock() 함수인데, 이 함수는 특정 주식 심볼에 대해서 지정한 시작일과 종료일 사이의 데이터를 야후 파이낸스로부터 가져와서 데이터베이스에 저장하는 역할을 합니다. 함수 동작도 간단히 설명드리겠습니다.
- 먼저 MySQL 내, 해당 기간에 이미 저장된 데이터가 있으면 삭제해서 중복 저장을 방지합니다.
- yf.download()를 통해 야후 파이낸스에서 주식 데이터를 가져옵니다.
- DataFrame의 각 행(날짜별 데이터)을 순회(iterrows)하며, 날짜, 시작가, 최고가, 최저가, 종가, 거래량 등 필요한 정보를 추출 후 SQL INSERT 쿼리로 데이터베이스에 저장합니다.
- 마지막으로는 해당 주식의 최신 데이터를 기준으로 nasdaq_company 테이블의 마지막 크롤링 날짜 및 가격 정보를 업데이트해줍니다.
- 두 번째 함수는 getCompany() 함수입니다. 이 함수는 DB에 저장된 NASDAQ 상장 기업 정보를 바탕으로 각 기업의 주식 데이터를 최신 상태로 갱신해주는 역할을 합니다. 이 친구도 간단히 설명해보자면,
- 먼저 nasdaq_company 테이블에서 심볼, IPO 연도, 마지막 크롤링 날짜 등의 정보를 불러와줍니다.
- 그리고 만약 해당 기업에 대해 이전 크롤링 기록이 없다면(last_crawel_date_stock가 NULL인 경우) IPO 연도(아니면 기본값인 1970년)부터 데이터를 수집하도록 시작 날짜를 설정합니다.
- 각 기업별로 설정된 날짜 범위를 매개변수로 해서 getStock() 함수를 호출한 후에 최신 주식 데이터를 수집하고 DB에 저장합니다.
📉 저장된 데이터로 분석하기
🌱 간단하게 몇 가지만 추출해보자!

- 데이터를 가져왔으니 간단한 주제들을 통해서 쿼리문을 작성하고 관련 데이터를 추출해보았습니다.
💡 52주 동안의 주가 분석
- 먼저 첫 번째 주제는 특정 일을 기준으로 지난 52주 동안의 주가 데이터를 분석하는 것이었습니다.
- 각 종목별로 52주 동안의 종가 중 최저가와 최고가를 계산한 후에, 그 차액과 최저가 대비 상승 비율(%)을 구해줍니다.
- 이 주제로 지난 1년간 특정 종목이 어느 정도의 가격 변동을 보였는지 쉽게 파악할 수 있었습니다.
SELECT
symbol,
CAST(MIN(close) AS DECIMAL(18, 2)) AS w52_min,
CAST(MAX(close) AS DECIMAL(18, 2)) AS w52_max,
CAST(MAX(close) - MIN(close) AS DECIMAL(18, 2)) AS `w52_diff_price($)`,
CAST((MAX(close) - MIN(close)) / MIN(close) * 100 AS DECIMAL(18, 2)) AS `w52_diff_ratio(%)`
FROM stock
WHERE date >= DATE_ADD('2023-10-04', INTERVAL -52 week) AND date <= '2025-03-04'
GROUP BY symbol;
💡 1일 간의 시작가와 종가를 비교하기 위한 정보 조회
- 두 번째는 특정한 하루의 데이터를 바탕으로 종목별 시초가와 종가를 비교하는 분석입니다.
- 시초가와 종가의 차이와 그 차이를 퍼센트로 나타낸 값, 그리고 당일 거래 중의 최저가와 최고가 및 이들 사이의 차이를 금액과 비율로 추출해냈습니다.
SELECT
date,
symbol,
CAST(open AS DECIMAL(18, 2)) AS open,
CAST(close AS DECIMAL(18, 2)) AS close,
CAST((open - close) AS DECIMAL(18, 2)) AS `diff_price($)`,
CAST(((close - open) / open * 100) AS DECIMAL(18, 2)) AS `diff_ratio(%)`,
'|' AS '---',
CAST(low AS DECIMAL(18, 2)) AS low,
CAST(high AS DECIMAL(18, 2)) AS high,
CAST((high - low) AS DECIMAL(18, 2)) AS `diff_high_price($)`,
CAST(((high - low) / low * 100) AS DECIMAL(18, 2)) AS `diff_high_ratio(%)`
FROM stock
WHERE date = '2025-03-04';
💡 10% 이상 가격이 오른 종목 조회
- 세 번째 주제는 특정 일의 시초가 대비 10% 이상 가격이 오른 종목들을 선별해서 보여주는 작업이었습니다.
- 상승률이 10% 이상인 종목들만 필터링한 후, 상승 비율이 큰 순서대로 정렬해서 어떤 종목이 크게 상승했는지 쉽게 확인할 수 있게 해주었습니다.
SELECT
date,
symbol,
CAST(open AS DECIMAL(18, 2)) AS open,
CAST(close AS DECIMAL(18, 2)) AS close,
CAST((open - close) AS DECIMAL(18, 2)) AS `diff_price($)`,
CAST(((close - open) / open * 100) AS DECIMAL(18, 2)) AS `diff_ratio(%)`,
'|' AS '---',
CAST(low AS DECIMAL(18, 2)) AS low,
CAST(high AS DECIMAL(18, 2)) AS high,
CAST((high - low) AS DECIMAL(18, 2)) AS `diff_high_price($)`,
CAST(((high - low) / low * 100) AS DECIMAL(18, 2)) AS `diff_high_ratio(%)`
FROM stock
WHERE
date = '2025-02-04' AND
CAST(((close - open) / open * 100) AS DECIMAL(18, 2)) >= 10
ORDER BY CAST(((close - open) / open * 100) AS DECIMAL(18, 2)) DESC;
💡 전일 대비 증감과 증감률 조회
- 마지막 간단 주제로는 전일 대비 주가의 변화를 분석하는 것이었습니다.
- 같은 주식 테이블을 두 번 사용해서 SELF JOIN을 수행하고, 전날과 당일의 종가를 비교해서, 각 종목별로 전일 대비 가격 차이가 얼마이며, 그 차이가 퍼센트로는 어느 정도인지를 확인할 수 있었습니다.
SELECT
a.symbol as symbol,
a.date as `전날`,
CAST(a.close AS DECIMAL(18, 2)) AS `전날 종가`,
'|' AS '---',
b.date as `오늘`,
CAST(b.close AS DECIMAL(18, 2)) AS `오늘 종가`,
'|' AS '---',
CAST((b.close - a.close) AS DECIMAL(18, 2)) AS `diff_price($)`,
CAST(((b.close - a.close) / b.close * 100) AS DECIMAL(18, 2)) AS `diff_ratio(%)`
FROM stock AS A
INNER JOIN stock AS B ON
a.symbol = b.symbol AND
a.date = DATE_ADD(b.date, INTERVAL -1 DAY)
WHERE a.date = '2025-03-03';
📈 주가가 연속적으로 상승한 종목도 볼 수 있을까?
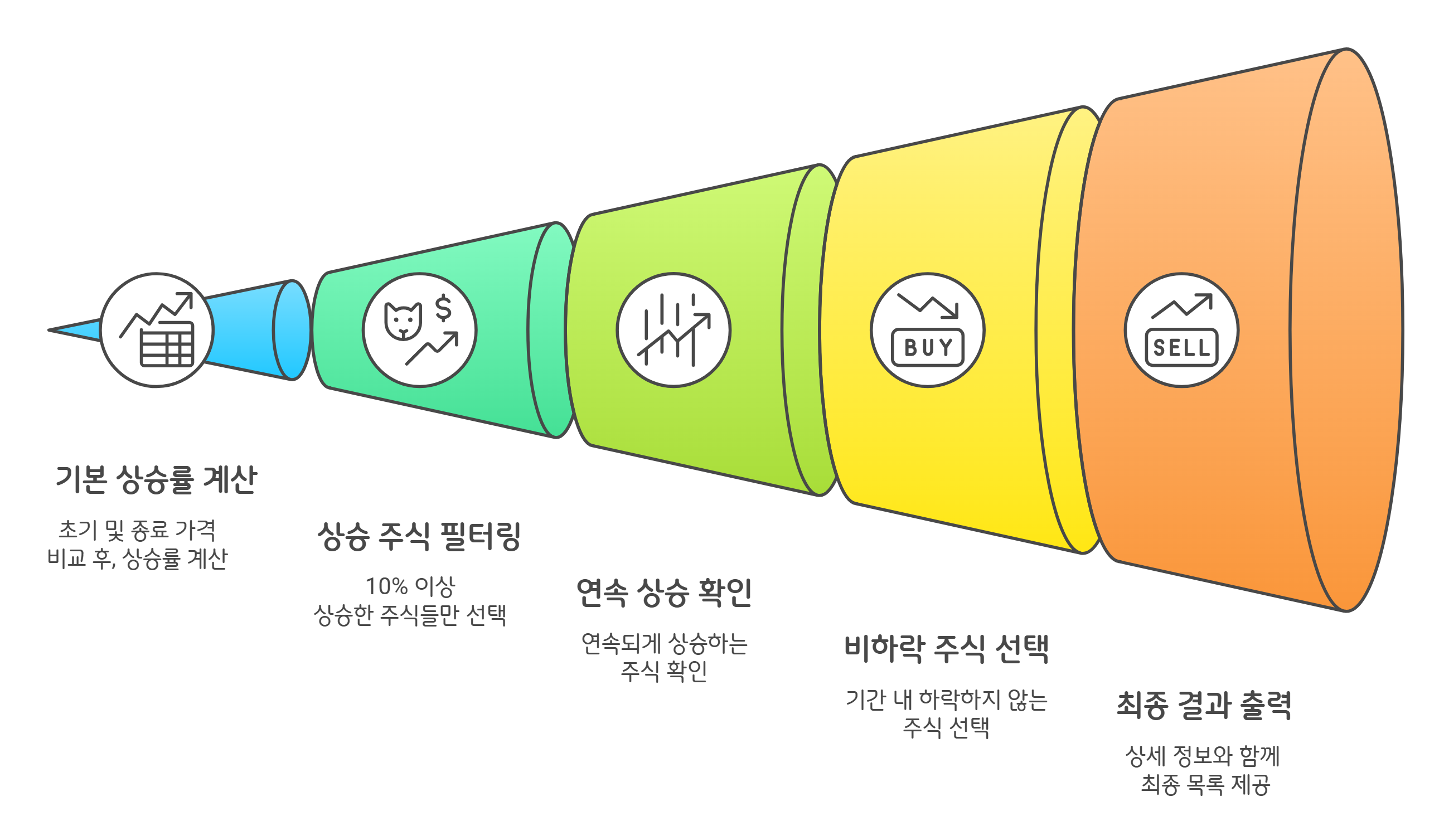
- 마지막 주제는 여태까지의 주제들을 거의 하나로 통합한 주제이기 때문에, SQL로도 해보고 파이썬으로도 변환해서 구현해보았습니다.
- 그래서 마지막 주제에 대한 설명은 SQL 위주로 하되, 코드는 파이썬으로 첨부하겠습니다.
💡 기간별로 시작과 종료 가격 비교
- 전에 분석했던 과정을 임시 테이블들로 만들고 최종 주제에 대해 조인하여 결과를 출력하는 형식으로 진행했습니다.
- 먼저 시작 날짜와 종료 날짜의 종가를 각각 조회해서 각 종목별 가격 차이와 상승률을 계산 후, 임시 테이블(temp1)에 저장했습니다.
def analyze_rising(df_stock, df_nasdaq, start_date, end_date):
start_date = pd.to_datetime(start_date)
end_date = pd.to_datetime(end_date)
# temp1: 시작일과 종료일의 종가 비교
df_start = df_stock[df_stock['date'] == start_date][['symbol', 'close']].copy()
df_start.rename(columns={'close': 'a_close'}, inplace=True)
df_end = df_stock[df_stock['date'] == end_date][['symbol', 'close']].copy()
df_end.rename(columns={'close': 'b_close'}, inplace=True)
temp1 = pd.merge(df_start, df_end, on='symbol')
temp1['close_diff'] = (temp1['b_close'] - temp1['a_close']).round(2)
temp1['ratio_diff'] = ((temp1['b_close'] - temp1['a_close']) / temp1['a_close'] * 100).round(2)
temp1['a_close'] = temp1['a_close'].round(2)
temp1['b_close'] = temp1['b_close'].round(2)
filter_symbols = temp1[temp1['ratio_diff'] >= 10]['symbol'].unique()
💡 일별 데이터 추출 및 순위 부여
- temp1에서 10% 이상 상승한 종목을 대상으로, 시작 날짜부터 종료 날짜까지의 일별 주가 데이터를 가져옵니다.
- 각 종목 내에서 날짜 순서대로 ROW_NUMBER() 함수를 사용해서 번호를 부여합니다.
- 참고로, MySQL 임시 테이블은 동시에 여러 번 참조할 수 없으므로, 동일한 결과를 가지는 두 개의 임시 테이블(temp2와 temp2_1)로 저장 후, SELF JOIN하듯 이용했습니다.
# temp2 / temp2_1: 해당 종목들의 start_date ~ end_date 기간 내 데이터 추출 및 row 번호 부여
condition = (
(df_stock['date'] >= start_date) &
(df_stock['date'] <= end_date) &
(df_stock['symbol'].isin(filter_symbols))
)
temp2 = df_stock[condition].copy()
temp2.sort_values(['symbol', 'date'], inplace=True)
temp2['num'] = temp2.groupby('symbol').cumcount() + 1
# SQL처럼 복사본을 생성할 필요는 없음
# temp2_1 = temp2.copy()
💡 연속 상승 여부 확인
- temp2와 temp2_1을 조인해서 동일 종목에 대해 연속된 두 날의 데이터를 비교했습니다.
- 이때, 전일 대비 상승 여부(증감률이 양수인지)를 계산해서 저장하고, 임시 테이블(temp3)에 기록했습니다.
# temp3: 전일 대비 상승 여부 (groupby 후, shift)
temp3 = temp2.copy()
# 각 symbol별로 이전 날짜의 date와 close
temp3['a_date'] = temp3.groupby('symbol')['date'].shift(1)
temp3['a_close'] = temp3.groupby('symbol')['close'].shift(1)
# 현재 행의 date와 close (b_date, b_close)
temp3['b_date'] = temp3['date']
temp3['b_close'] = temp3['close']
# 첫 번째 row per symbol는 비교 불가하므로 제거
temp3 = temp3.dropna(subset=['a_date'])
temp3['close_diff'] = (temp3['b_close'] - temp3['a_close']).round(2)
temp3['ratio_diff'] = ((temp3['b_close'] - temp3['a_close']) / temp3['a_close'] * 100).round(2)
💡 하락 없는 종목 선별
- temp3에서 만약 어느 날이라도 주가가 하락한 종목은 별도로 temp3_1에 저장합니다.
- 그 후에 temp3의 결과 중 temp3_1에 포함되지 않은 종목만을 temp4에 저장하여, 전체 기간 동안 한 번도 하락하지 않은 종목만 남깁니다.
# temp3_1: 한 번이라도 하락한 종목 목록
down_symbols = temp3[temp3['ratio_diff'] < 0]['symbol'].unique()
# temp4: 하락 없이 연속 상승한 데이터만 선택
temp4 = temp3[~temp3['symbol'].isin(down_symbols)].copy()
temp4['a_close'] = temp4['a_close'].round(2)
temp4['b_close'] = temp4['b_close'].round(2)
temp4['close_diff'] = temp4['close_diff'].round(2)
temp4['ratio_diff'] = temp4['ratio_diff'].round(2)
# temp1, temp2, temp4에서 공통으로 나타난 종목 선택
temp2_symbols = set(temp2['symbol'].unique())
temp4_symbols = set(temp4['symbol'].unique())
# 공통 교집합 계산
final_symbols = temp2_symbols.intersection(temp4_symbols)
final_temp1 = temp1[temp1['symbol'].isin(final_symbols)].copy()
💡 최종 결과 출력 및 추가 정보 조인
- 이제 완성된 temp1, temp2(또는 temp4) 등의 임시 테이블과 nasdaq_company 테이블을 조인하여, 최종적으로 연속 상승한 종목의 상세 정보를 출력합니다.
- 최종 결과는 회사명, 업종 등의 추가 정보들과 함께 시작일과 종료일의 가격, 가격 차이, 상승률 등을 보여줄 수도 있고, 이 추출된 데이터들은 상승 비율 기준으로 내림차순 정렬됩니다.
# nasdaq_company와 symbol 기준으로 병합
df_final = pd.merge(final_temp1, df_nasdaq, on='symbol', how='inner')
df_final = df_final.sort_values('ratio_diff', ascending=False)
df_final.rename(columns={
'a_close': 'a_close',
'b_close': 'b_close',
'close_diff': 'diff_price',
'ratio_diff': 'diff_ratio'
}, inplace=True)
df_final = df_final[['symbol', 'company_name',
'industry', 'a_close', 'b_close',
'diff_price', 'diff_ratio']]
return df_final
🤔 26일차 회고
- 간만에 시각화에 힘들이지 않는 분석을 진행해보았습니다. (하지만 머리는 아픈...)
- 파이썬에서는 참 쉬웠던 전처리들이 SQL에서는 꽤나 복잡하다는 것을 직접 손으로 느껴보며(?), 오늘 쿼리를 짜는 과정을 잘 익혀두면 앞으로 어떤 데이터가 와도 처리해낼 수 있을 것만 같습니다.
- 비록 크롤러를 직접 만들어서 데이터를 긁어온 것은 아니지만, yfinance의 반환값이 DataFrame이 아니라는 것 등에 대한 yfinance의 세부 사항들을 잘 익힐 수 있는 시간이었습니다.
- 드디어 내일부터 찐찐찐! 으로 자연어 처리에 입성하게 됩니다. 깊게 다뤄주신다고 하니 더더욱 기대되고 그만큼 모든 코드들을 제 것으로 만들어버리고 싶습니닷 🧑🏻💻
728x90
LIST
'Projects > LG U+' 카테고리의 다른 글
| [Data Analysis] 심부전 데이터 (8) | 2025.03.09 |
|---|---|
| [Data Analysis] 한국복지패널 데이터 (14) | 2025.03.09 |
| [Data Analysis] 미국 항공기 운항 데이터 (4) | 2025.03.02 |
| [Data Analysis] 다나와 & 미세먼지 & 행복 지수 데이터 (2) | 2025.02.20 |
| [Data Analysis] Starbucks & Mega Coffee 데이터 (4) | 2025.02.19 |