
728x90
SMALL

- 오늘은 커피 매장들에 대한 데이터를 각 홈페이지에서 크롤링으로 수집 후, folium으로 버블 지도 및 단계 구분도로 시각화하여 여러 데이터와 비교 분석을 진행해보았습니다.
🧑🏼 외국인 방문객 데이터 시각화
🕰️ 연도에 따른 관광객 수 시계열
- 어제 마지막 부근에 통합했었던 외국인 방문객 데이터를 가지고 오늘은 간단한 시각화 작업을 진행해보았습니다!
- 먼저 기준년월에 따른 여러 국가의 관광객 수를 시계열 차트로 시각화했습니다.
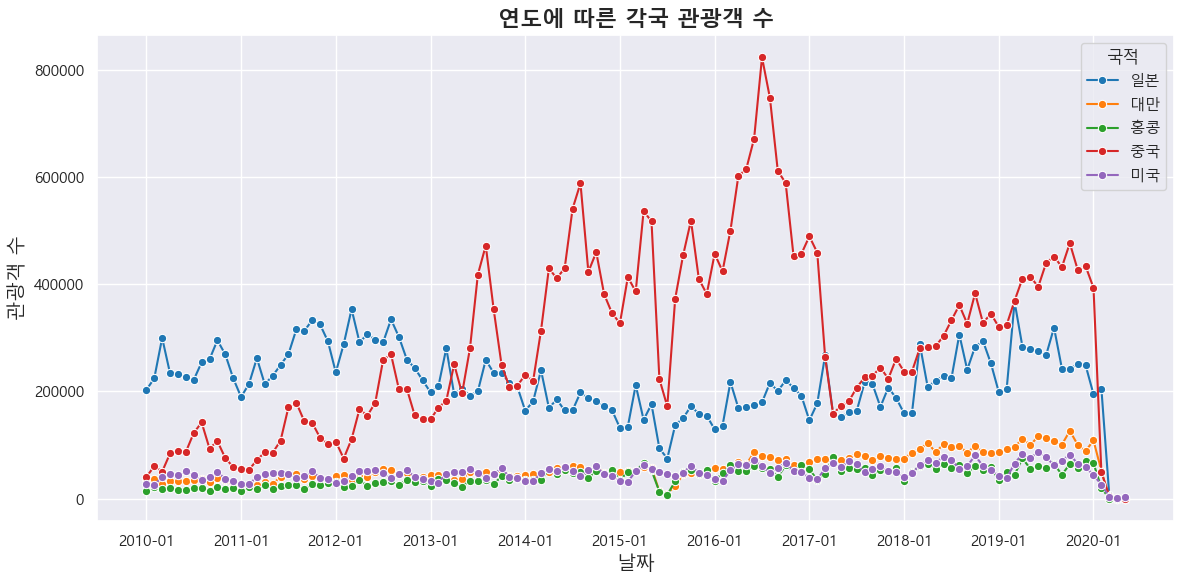
- 관광객 수가 가장 많은 나라 Top 5(중국, 일본, 대만, 미국, 홍콩)를 지정해서 시각화했고, 방문 목적은 '관광'으로만 추려서 진행했습니다.
🔥 관광객 히트맵
- 그리고 두 번째로는 중국인 관광객을 대상으로 히트맵을 그려보았습니다.
- 만들기 전에 우선 데이터에는 기준년월만 컬럼으로 설정되어 있었기에 slice() 함수를 이용해서 기준년월을 '연도'와 '월' 컬럼으로 구분지었습니다.
- 그리고 index는 '연도', columns는 '월', values는 '관광'으로 하여 pivot_table()을 생성한 뒤, 히트맵으로 쫙 그려봤습니다!
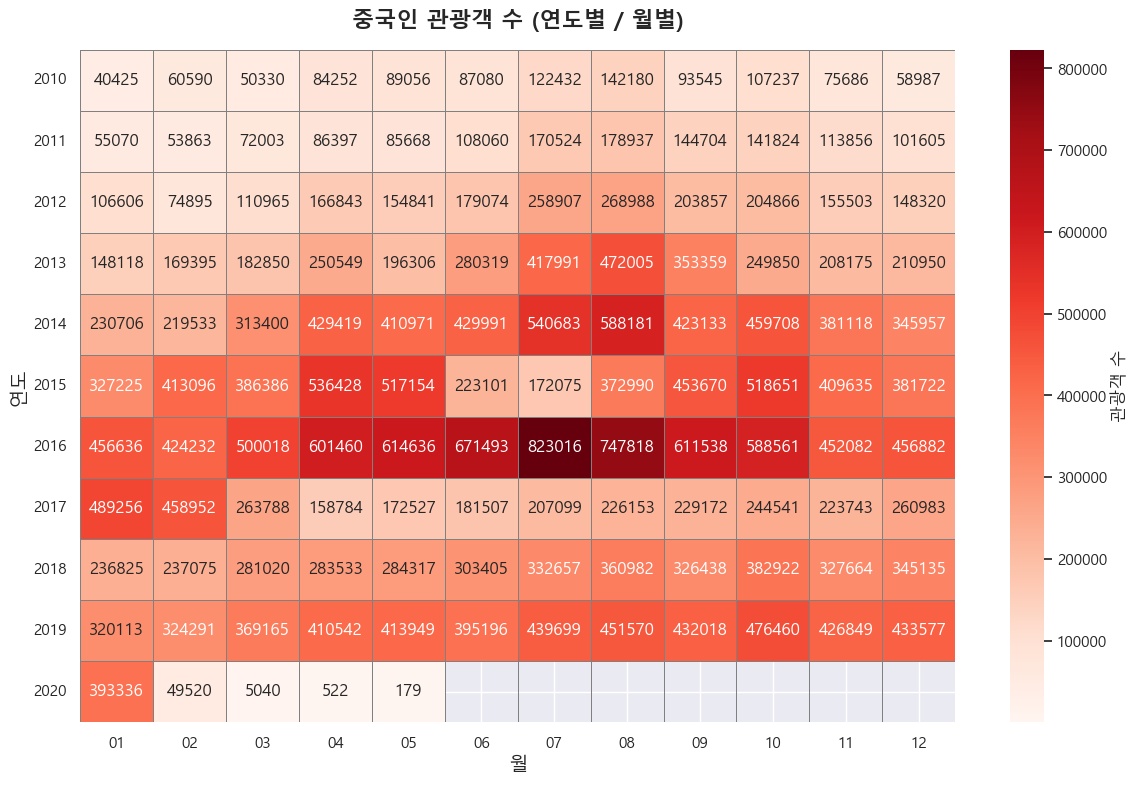
- 살펴보니 2016년, 특히 여름에 관광객 수가 몰렸었던 것을 확인할 수가 있네요. 🕶️
☕ 우리 동네에는 왜 스타벅스가 없지?
- 를 ! 주제로 삼아 서울에서 스타벅스가 어떤 입지 전략으로 매장 입지를 선택하는지 분석하고자 합니다.
- 아래의 두 가지 가설을 세워, 이 가설들이 맞는지 데이터 분석을 통해 확인해봅시닷!
- 가설 하나! 거주 인구가 많은 지역에 스타벅스 매장이 많이 입지해 있을 것 !
- 가설 둘! 직장인이 많은 지역에 스타벅스 매장이 많이 입지해 있을 것 !
✨ 데이터 수집
- 입지 전략을 분석하기 위해서 먼저, 서울시 내에 출범한 스타벅스들의 위치를 파악해야 했습니다. 그래서 저희는 스타벅스 홈페이지에서 매장들의 정보를 크롤링으로 수집하게 되었습니다.
- 또한, 위에서 세운 두 가지 가설을 검증하기 위한 인구 통계 데이터도 필요했는데, 이 데이터는 서울시 열린데이터 광장에서 가져올 수 있습니다.
- (실제로는 OPEN API로 인구 통계 데이터(거주인구 수, 직장인구 수)를 가져와야하는데, 정황상 강사님께서 다 제공해주셨습니다...!)
- '서울시 주민등록인구 (구별) 통계' 데이터, '서울시 사업체현황 (산업대분류별/동별) 통계' 데이터, 총 두 가지 데이터를 활용할 예정이고, 데이터를 가져올 때는 반드시 사용 목적을 학습 용도로 기입 후에 가져올 것 !
🗞️ 크롤링으로 스타벅스 매장 목록 데이터 가져오기
- 어제 진행했듯 webdriver를 사용했습니다. 여기서 한 가지 추가 작업이 들어가게 되었는데,
- 웹페이지에서는 처음부터 서울 지역 매장이 보이지 않고 특정 버튼을 눌러야 정보를 확인할 수 있도록 구성되어 있었습니다.
- 그래서 find_element('css selector', seoul_btn).click() 함수를 이용해 버튼을 누른 후 크롤링을 시작했습니다.
- 각 매장 객체는 다음과 같이 이루어져 있었습니다.
<li class="quickResultLstCon" style="background:#fff"
data-lat="37.501087" data-long="127.043069"
data-index="0" data-name="역삼아레나빌딩"
data-code="3762" data-storecd="1509" data-hlytag="null">
<strong data-store="1509" data-yn="N"
data-name="역삼아레나빌딩" data-my_siren_order_store_yn="N">역삼아레나빌딩
</strong>
<p class="result_details">서울특별시 강남구 언주로 425 (역삼동)<br>1522-3232</p>
<i class="pin_general">리저브 매장 2번</i>
</li>- 따라서 select() 함수를 이용해 quickResultLstCon를 class명으로 가지는 li 태그를 모두 가져와 적절히 전처리하고, 하나의 데이터로 만들어주었습니다.
starbucks_soup_list = soup.select('li.quickResultLstCon')
starbucks_store = starbucks_soup_list[0]
# 스타벅스 매장 정보 샘플(역삼아레나빌딩점) 확인
name = starbucks_store.select('strong')[0].text.strip()
lat = starbucks_store['data-lat'].strip()
long = starbucks_store['data-long'].strip()
store_type = starbucks_store.select('i')[0]['class'][0][4:]
address = str(starbucks_store.select('p.result_details')[0]).split('<br/>')[0].split('>')[1]
tel = str(starbucks_store.select('p.result_details')[0]).split('<br/>')[1].split('<')[0]
print(f'찾으시는 매장은 {name}점이며,
\n위치는 위도 {lat}도, 경도 {long}도
\n즉, {address}에 위치해있습니다.
\n매장은 {store_type} 타입이며, 매장 번호는 {tel}입니다.')
# 출력값
# 찾으시는 매장은 역삼아레나빌딩점이며,
# 위치는 위도 37.501087도, 경도 127.043069도
# 즉, 서울특별시 강남구 언주로 425 (역삼동)에 위치해있습니다.
# 매장은 general 타입이며, 매장 번호는 1522-3232입니다.
🧹 공공데이터 정리
- 또한, 위에서 언급했던 서울시 주민등록인구 (구별) 통계 데이터에서는 시군구별 주민등록인구 데이터를 뽑아왔고,
- 서울시 사업체현황 (산업대분류별/동별) 통계 데이터에서는 시군구동별 사업체 현황을 추출해냈습니다.
✨ 데이터 전처리
- 데이터들에 기본적으로 '시군구명' 컬럼이 존재했기 때문에 크롤링했던 스타벅스 데이터에서도 주소 컬럼에서부터 시군구명을 추출해냈습니다.
- 그 후, 시군구별로 스타벅스 매장 수를 세기 위해서 pivot_table() 형태로 만든 다음, 모든 데이터를 '시군구명'을 기준으로 통합(merge)시켰습니다!
✨ 데이터 시각화
🎨 스타벅스 매장 분포
- 이제는 살짝 가물가물해졌지만, 첫 주에 배운 folium으로 스타벅스 매장의 분포를 시각화해보았습니다.
- 전에는 Marker() 클래스를 사용해서 해당 지점의 위치를 찍어봤었는데, 오늘은 CircleMarker()를 이용해 점으로 표현해보았습니다.
- for 문을 이용해서 데이터에서의 스타벅스 매장 위/경도 값을 CircleMarker()에게 넘겨주고, 매장 타입별로 색상도 다르게 하여 나타냈습니다.
for idx in seoul_starbucks.index:
lat = seoul_starbucks.loc[idx, '위도']
long = seoul_starbucks.loc[idx, '경도']
store_type = seoul_starbucks.loc[idx, '매장타입']
# 매장 타입별 색상 선택을 위한 조건문
fillColor = ''
if store_type == 'general':
fillColor = '#296044'
size = 3
elif store_type == 'reserve':
fillColor = '#243832'
size = 5
elif store_type == 'generalDT':
fillColor = '#fdd663'
size = 7
folium.CircleMarker(location=[lat, long], # 위치
fill=True, # 내부 색깔
fill_color=fillColor,
fill_opacity=1,
color='#F2F0EB', # 테두리 색깔
weight=1,
radius=size).add_to(starbucks_map2)- 이렇게 구현한 뒤, html 파일로 저장하고 해당 파일을 열어보게 되면 다음과 같이 브라우저 창에 보여지게 됩니다!

🎨 시군구별 스타벅스 매장 수(버블 지도)
- 이번 시각화에는 조금 색다른 게 추가가 되었습니다. 바로 .geojson 파일인데, 이 파일에는 서울시 시군구별로 행정 경계 지도 데이터가 수치형으로 들어가 있습니다.
- 이를 시각화하기 위해 먼저 json 모듈이 필요합니다. json.load() 함수를 이용해서 파일을 읽어내면, 데이터가 딕셔너리 자료형으로 반환되게 됩니다.
- 그리고 folium 모듈 내 GeoJson()만 있으면, 이 .geojson 파일로 시군구별 경계를 시각화할 수 있게 됩니다.
seoul_geo = json.load(open(file_path, encoding='utf-8'))
folium.GeoJson(seoul_geo, style_function=style_function).add_to(bubble)- 그 다음 시군구별 평균 매장 수를 계산한 후, 각 시군구의 매장 수에 따라 CircleMarker의 색상과 크기를 조정하였습니다.
- 평균보다 매장 수가 많은 구는 어두운 색상으로, 적은 구는 약간 밝은 색상으로 표시되어 구별할 수 있게 하였습니다.
- 결과적으로 다음과 같은 화면이 생성되었습니다.

🎨 시군구별 스타벅스 매장 수(단계 구분도)
- 이번에는 위와 살짝 다르게 지도 위에 직접 그 매장 수를 색상으로 나타내보고자 합니다. 이를 위해서는 단계 구분도라는 것이 필요합니다.
- Choropleth(단계 구분도) 지도는 각 지역의 통계치를 색상으로 표현하는 지도입니다. 데이터 값이 클수록 색이 짙어지는 방식으로, 구별 통계치를 직관적으로 비교 가능합니다.
- 이 단계 구분도는 folium.Choropleth() 함수를 사용해 시각화할 수 있고, 시군구별로 매장 분포의 차이를 파악할 수 있게 했습니다.
folium.Choropleth(geo_data=seoul_geo,
data=seoul_stat,
columns=['시군구명', '매장수'],
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.5,
key_on='properties.SIG_KOR_NM').add_to(choropleth)- 그렇게 되면 위 버블 지도와는 살짝 다르게 표현된 웹 페이지가 생성되는 것을 확인할 수 있습니다.

- 그리고 나서 이 단계 구분도들을 비교해보면서 저희가 세운 가설이 맞는지 검증을 해보는 시간을 가져보았습니다!
💭 거주 인구가 많으면 스타벅스 매장이 많을까?
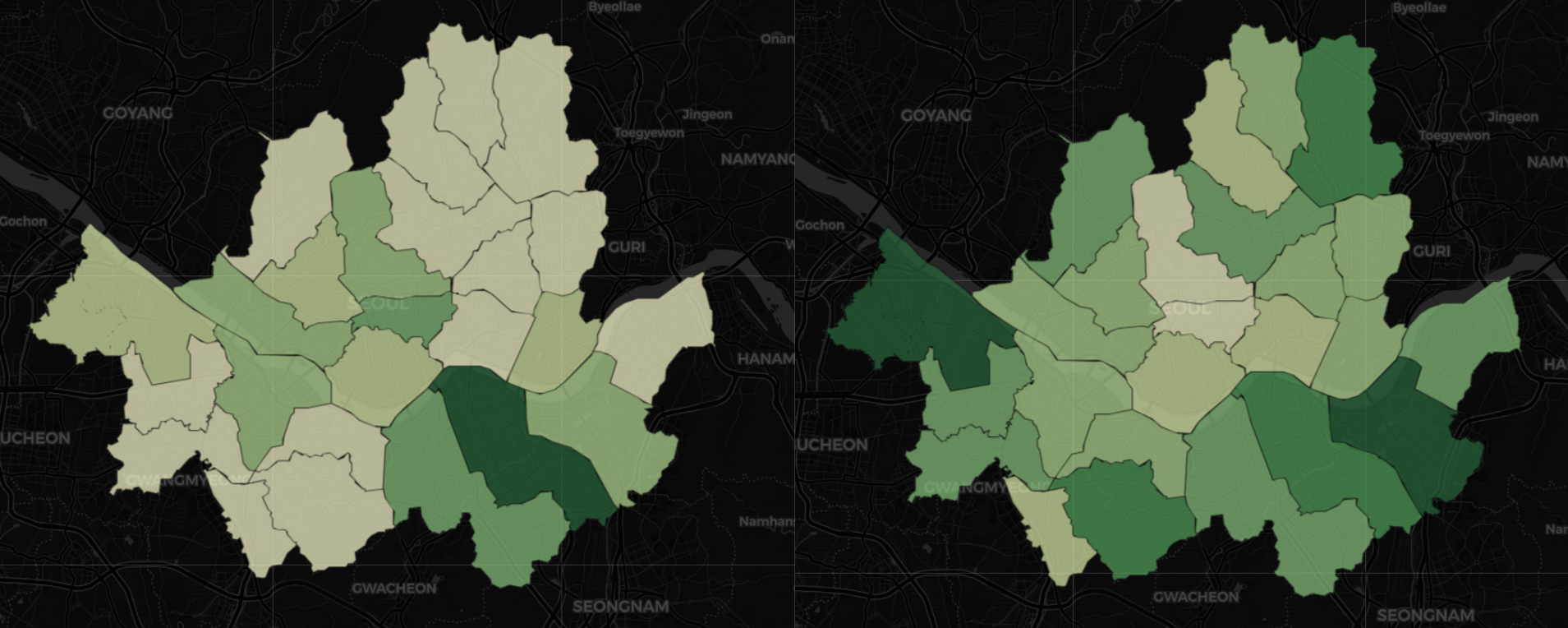
- 확인해보시면, 매장 수와 거주 인구는 상관이 없어보입니다. 물론 강남 지역은 유사성이 살짝 보이긴 하지만, 강서나 강북은 연관이 없어보이네요.
💭 그럼 직장인이 많으면 스타벅스 매장이 많을까?

- 이 가설은 그래도 얼추 맞는 듯 보였습니다. 물론 수업 때에는 강사님 데이터와 저희 데이터의 차이가 있는 것인지, 시각화의 차이가 있었지만, 제 데이터로 봤을 때 이 가설은 조금 맞는 것 같아보입니다.
☕ 이번에는 메가 커피!
- 위 스타벅스 데이터 분석 과정은 강사님과 함께였지만... 메가 커피 데이터 크롤링부터 시각화 후 비교까지는 배우는 저희들의 몫이었습니다.
- 이번에도 가설을 몇 가지 세웠는데,
- 한국인들이 많은 지역 or 외국인이 많은 지역에 메가 커피 매장이 많이 입지해 있을 것이다! 라는 것과
- 특정 업종에 따라 메가 커피 매장의 입지율도 높을 것이다! 는 가설이었습니다.
- 시각화는 앞선 스타벅스 분석 과정과 유사해서 데이터 수집 과정만 한 번 쭉 읊어보겠습니다.
✨ 데이터 수집
- 우선 메가 커피 매장 찾기 URL은 정말이지... 구조가 복잡했습니다.
- Selenium으로 element까지 접근하는 건 어찌저찌 하겠는데, click()으로 이벤트가 적용되지 않는데 이 이벤트가 발생해야 내부 데이터를 가져올 수 있는 구조였습니다.
- 즉, 어떤 지점을 누르게 되면 해당 매장의 세부 정보가 동적으로 생성이 되는데, 이 접근하는 방식을 Selenium으로 하기가 매우 어려웠습니다.
- 한참을 헤매다 결국 검색창에 '서울'을 입력해 그 정보들을 모조리 싹 긁어와 데이터를 만들어냈습니다.
- (강사님께서는 어떻게 하셨는지 넘 궁금하다 낼 꼭 꼼꼼히 들어봐야지)
🧹 공공데이터 정리
- 또, 스타벅스 분석 때처럼 서울시 주민등록인구 (구별) 통계 데이터에서는 시군구별 한국인/외국인 수 데이터를 뽑아왔고,
- 서울시 사업체현황 (산업대분류별/동별) 통계 데이터에서는 시군구동별 및 업종별(상위 5개) 종사자 수 데이터를 추출해냈습니다.
✨ 데이터 시각화
- 스타벅스처럼 단계 구분도로 나타낸 메가 커피 매장 수입니다.
- 분포만 살펴봐도 전지역에 고르게 퍼져있고, 특히 강남 지역에 많이 분포되어 있었습니다!
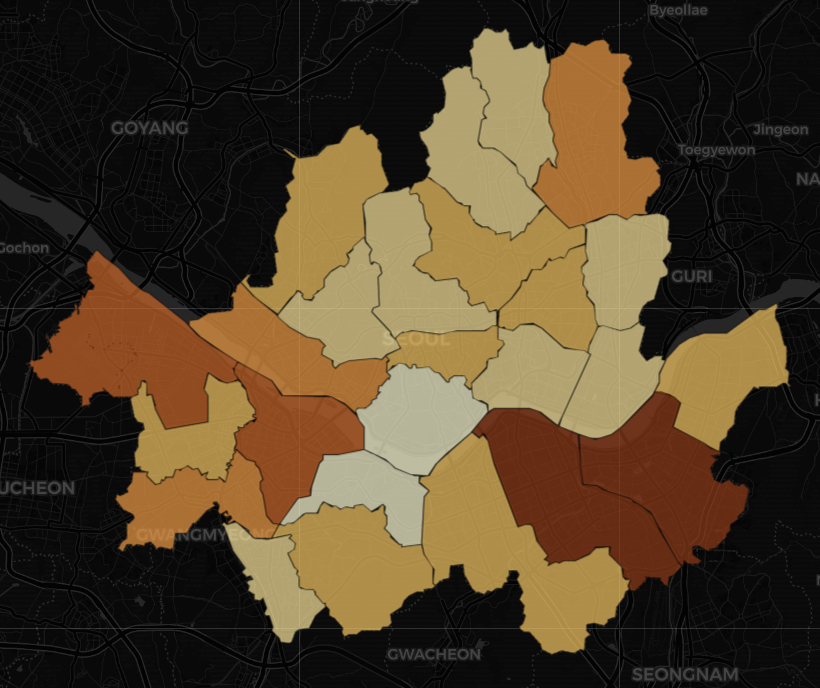
- 한국인, 외국인, 그리고 업종별로도 단계 구분도 html을 생성해 비교해봤는데, 여기에 첨부하긴 단계 구분도만 너무 많아지는 듯 하여
- 내일 추가적으로 시각화를 하게 되면 내일 포스팅에 추가적으로 올려보도록 하겠습니다! (가설은 한국인 기준으로만 봤을 때는 대충 맞는 것 같아요!)
🤔 17일차 회고
- 오늘 하루가 정말 깁니다... 뜻밖의 고난이도 과제를 던져주고 가셔서 남아서 조금 하다보니 하루가 다 지나있었습니다.
- Selenium으로 계속 시도해보다가 정 안 되면 포기해야겠다 싶었는데, 옆에서 다른 방법으로 조언해 준 동기 덕분에 시간 내 잘 마무리하고 집에도 무사히 올 수 있어서 감사하네요 :)
- 오늘 과제에 대한 풀이를 내일 해주실지는 모르겠지만, 내일 수업은 더더욱이 열심히 들어야겠습니다!! 🔥
- 아직 20일차도 되지 않았는데 이 정도 수준의 프로젝트까지 진행될 정도여서 배우는 것에 정말 큰 보람을 느끼고 있습니다.
- 내일은 '다나와' 데이터 분석이 있을 예정입니다. 열심히 또 달려보겠습니다. 🏃🏻♂️
728x90
LIST
'Projects > LG U+' 카테고리의 다른 글
| [Data Analysis] 한국복지패널 데이터 (14) | 2025.03.09 |
|---|---|
| [Data Analysis] 야후 파이낸스 주식 데이터 (4) | 2025.03.05 |
| [Data Analysis] 미국 항공기 운항 데이터 (4) | 2025.03.02 |
| [Data Analysis] 다나와 & 미세먼지 & 행복 지수 데이터 (2) | 2025.02.20 |
| [Data Analysis] Netflix 데이터 (2) | 2025.02.14 |