
728x90
SMALL
Abstract
A new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
Transformer 모델의 주요 특징
- 전적으로 attention mechanism에 기반한 새로운 network architecture
- 기존 모델들의 recurrence와 convolution layer를 완전히 대체
실험 결과 및 성능
- 두 가지 machine translation task에서 우수한 성능 입증
- 높은 parallelization 능력
- 기존 모델 대비 훨씬 짧은 training time 소요
구체적인 성과
- WMT 2014 English-to-German translation task에서 28.4 BLEU score 달성
- 기존 최고 성능(ensemble model 포함) 대비 2 BLEU 이상 향상
- WMT 2014 English-to-French translation task에서 41.8 BLEU score로 single-model state-of-the-art 기록 수립
- 8개 GPU로 3.5일 training, 기존 최고 모델들 대비 훨씬 적은 training cost
Introduction
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder.
기존 모델의 특징
구조적 주요 한계점
- Sequential nature으로 인한 parallelization의 어려움
- Long sequence에서의 performance 저하 문제 (긴 입력 sequence에서 정보 손실이나 왜곡이 발생하는 문제)
이들을 대체할 Transformer의 핵심
- Recurrence와 Convolution의 완전 배제
- 전적으로 attention mechanism에 기반한 새로운 구조 (입력 sequence의 모든 위치를 동시에 고려할 수 있음)
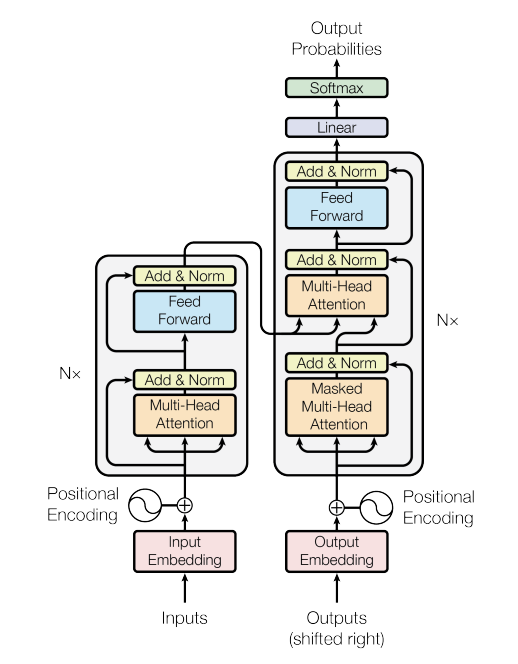
Background
기존 모델의 노력
- Extended Neural GPU, ByteNet, ConvS2S 등의 모델이 sequential computation 감소를 목표로 제안됨
- 이 모델들은 CNN을 기본 building block으로 사용하여 모든 입출력 위치의 hidden representation을 병렬로 계산
이 노력의 한계
- 두 임의의 입출력 위치 간 signal을 연관짓는 데 필요한 연산 수가 위치 간 거리에 따라 증가
- ConvS2S: 선형적 증가, ByteNet: 로그적 증가
- 이로 인해 장거리 의존성(long-range dependency) 학습의 어려움 발생
Self-attention의 활용
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
- Reading comprehension(독해), abstractive summarization(추상적인 요약), textual entailment(텍스트 함의) 등 다양한 task에 성공적으로 적용
End-to-end memory networks
- Sequence-aligned recurrence 대신 recurrent attention mechanism 사용
- 간단한 언어 질의응답 및 언어 모델링 task에서 우수한 성능 입증
Transformer의 독창성
- Self-attention만을 사용하여 입력과 출력의 representation을 계산하는 최초의 transduction model
- Sequence-aligned RNN(순환 신경망)이나 convolution(합성곱)을 사용하지 않음
Model Architecture
전체적인 구조
- Encoder-Decoder 구조 채택
- Encoder와 Decoder 모두 self-attention과 point-wise fully connected layer로 구성
Encoder-Decoder 상세 구조
- 각각 6개의 동일한 layer로 구성
- Encoder layer: multi-head self-attention + position-wise feed-forward network
- Decoder layer: masked multi-head self-attention + multi-head attention over encoder output + position-wise feed-forward network
- 각 sub-layer에 residual connection과 layer normalization 적용
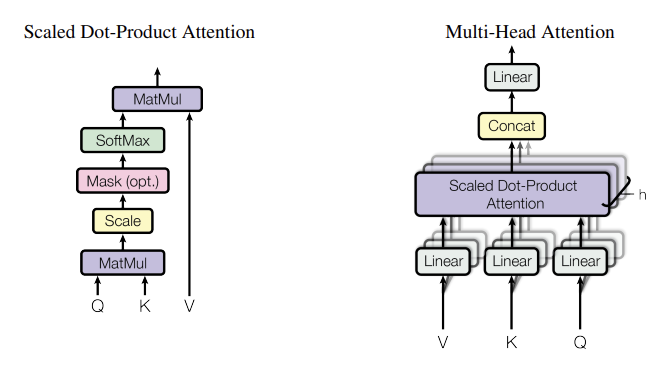
Attention
- Scaled Dot-Product Attention 사용

- Multi-Head Attention으로 여러 개의 attention을 병렬로 수행 (여러 관점에서 정보 추출 가능)
- encoder self-attention, decoder self-attention, encoder-decoder attention의 세 가지 용도로 사용
Position-wise Feed-Forward Networks
- 각 위치에 독립적으로 적용되는 fully connected feed-forward network
- 두 개의 선형 변환과 ReLU 활성화 함수로 구성
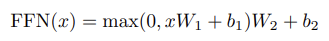
Embeddings and Softmax
- 입력과 출력 token을 d_model 차원의 벡터로 변환하는 learned embeddings 사용
- Decoder 출력을 다음 token 확률로 변환하는 learned linear transformation과 softmax function 사용
- 세 개의 embedding layer에서 weight 공유 (효율성 증가)
Positional Encoding
- 모델에 sequence 순서 정보를 주입하기 위해 사용 (Transformer는 순환 구조가 없어서 위치 정보를 별도로 제공해야 함)
- sin과 cos 함수를 이용한 고정된 positional encoding 사용

Why Self-Attention
- Self-Attention vs. Recurrent / Convolutional

계산 복잡도
- Self-Attention은 Sequence 길이(n)가 표현 차원(d)보다 작을 때 Recurrent보다 빠른 계산 속도를 가짐
- 대부분의 최신 기계 번역 모델에서 해당되는 조건
Parallelization
- Self-attention과 convolutional은 높은 병렬 처리 효율성을 가짐
- Recurrent는 순차적 처리로 인한 parallelization 한계
Long-range dependency path length
- Self-attention은 일정한 path length로 인해 장거리 의존성 학습에 용이
- Recurrent와 convolutional layer는 상대적으로 긴 경로 길이를 가짐
Side benefit
- 개별 attention head의 다양한 작업 학습 능력
- 문장의 구문 및 의미 구조와 관련된 동작 표현
- 모델 동작의 시각화 및 이해 용이
Attention Visualizations

- 5번째 layer의 encoder self-attention에서 'making'과 관련된 단어들 간의 관계
- 여러 attention head가 'making...more difficult' 구문의 long-range dependency을 포착
Training
Training 데이터와 Batch 구성
- WMT 2014 English-German 데이터셋 사용: 약 4백만 문장 쌍
- 인코딩 방식: byte-pair encoding (BPE)
- 공유 source-target 어휘: 약 37,000 token
- English-French 번역을 위한 더 큰 WMT 2014 데이터셋: 36M 문장
- Wordpiece 분할을 사용한 32,000 word 크기의 어휘
- Batch는 약 25,000개의 source token과 25,000개의 target token을 포함하는 문장 쌍 세트
Hardware & Schedule
- 기본 모델의 학습 단계당 소요 시간: 약 0.4초
- 기본 모델의 총 학습 시간: 12시간
- 큰 모델의 학습 단계당 소요 시간: 약 1초
- 큰 모델의 총 학습 시간: 3.5일
Optimizer
- Adam 사용

- 처음 warmup steps 동안 학습률을 선형적으로 증가시킨 후 단계 수의 역제곱근에 비례하여 감소
Regularization
Residual Dropout
- 각 sub-layer의 출력에 dropout 적용
- Sub-layer의 출력이 sub-layer 입력과 더해지고 정규화되기 전 적용
- Encoder와 decoder stack의 embedding과 positional encoding의 합에도 dropout 적용
Label Smoothing
- 모델이 특정 클래스에 과도하게 확신을 갖는 것을 방지하는 기법
- 정답 레이블에 약간의 노이즈를 추가하여 모델의 과신을 줄임
- Perplexity는 악화되지만, 정확도와 BLEU는 향상
Layer Normalization
- 각 sub-layer의 입력에 적용 (residual connection과 함께 사용)
Results
Machine Translation
- 기존 최고 성능 대비 2.0 BLEU 이상의 성능 향상
- 기존에 발표된 모든 단일 모델들의 성능 상회
- 이전 state-of-the-art 모델 대비 1/4 이하의 학습 비용으로 목표 달성
Model Variations
- Attention head 수와 attention key / value 차원 변화에 따른 성능 변화 관찰
- 모델 크기 변화에 따른 성능 변화 분석
- Dropout의 효과 검증
- 학습된 positional embedding과 고정된 사인파 함수 기반 인코딩의 성능 비교
English Constituency Parsing
- Wall Street Journal (WSJ) 데이터의 Penn Treebank 부분(약 40K 학습 문장) 사용
- 반지도 학습 설정으로도 실험 수행 (약 17M 문장의 대규모 corpus 활용)
- 4층 구조의 Transformer 모델 사용
- WSJ 데이터만 사용한 경우와 반지도 학습을 적용한 경우 모두에서 우수한 성능 달성
- 특히 반지도 학습 설정에서 92.7의 F1 score 달성
Conclusion
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
향후 연구 방향
- 다른 task로의 Transformer 적용 계획
- 텍스트 이외의 입출력 modality로의 확장 가능성 탐구
- 대규모 입력과 출력을 효율적으로 처리하기 위한 local, restricted attention mechanism 연구
- 생성 과정의 순차성 감소 목표
Index
Abstract
- Attention mechanism: 입력의 각 부분에 중요도를 부여하는 기법
- BLEU: Bilingual Evaluation Understudy, 기계 번역의 품질을 평가하는 지표. 0~100 사이의 값으로 높을수록 좋음
- Ensemble model: 여러 model을 조합하여 성능을 높이는 기법
- State-of-the-art: 최고 성능, 최신 기술
Introduction
- RNN: 순차적 데이터를 처리하는 신경망
- CNN: 주로 이미지 처리에 사용되는 신경망
- Encoder: 입력 sequence를 고정 크기의 representation으로 변환
- Decoder: 위 representation을 바탕으로 출력 생성
- Sequential nature: 이전 단계 결과에 의존하여 계산이 진행되는 특성
Background
- Hidden representation: 신경망 내부에서 입력 데이터를 표현하는 방식
- Long-range dependency: sequence 내에서 멀리 떨어진 요소들 간의 관계
- Self-attention: 단일 sequence 내 다른 위치들을 연관짓는 attention mechanism
Model Architecture
- Masked self-attention : 미래 정보를 보지 못하게 하는 self-attention mechanism
- Residual connection: 입력을 출력에 더해 기울기 소실 문제 완화
- Layer normalization: 각 입력을 정규화하여 학습 안정화
- ReLU: Rectified Linear Unit, 비선형성을 추가하는 activation function
- Embedding: 이산적인 토큰을 연속적인 벡터 공간으로 mapping
- Softmax: 출력을 확률 분포로 변환하는 함수
Training
- BPE: 자주 등장하는 문자 sequence를 하나의 token으로 병합하는 방식
- Adam: Adaptive Moment Estimation, 학습률을 자동으로 조정하는 최적화 알고리즘
- Dropout: 과적합 방지를 위해 학습 중 일부 뉴런을 무작위로 비활성화하는 기법
- Perplexity: 언어 모델의 성능을 측정하는 지표, 낮을수록 일반적으로 좋음
Results
- 반지도 학습: 레이블이 있는 데이터와 레이블이 없는 데이터를 모두 활용하는 학습 방법
- F1 score: 정밀도와 재현율의 조화 평균, 0-100 사이의 값, 높을수록 좋음
Conclusion
- Modality : 데이터의 형태나 감각적 특성, 예: 이미지, 음성 등
728x90
LIST
'Paper Review > ML' 카테고리의 다른 글
| [Time Series] Are Transformers Effective for Time Series Forecasting? (0) | 2024.07.26 |
|---|