
728x90
SMALL
1. TL;DR (어쩌면 굉장히 방대해질 글)
- 저희 팀은 KREAM과 같은 C2C 기반 리셀 플랫폼, UNBOX를 만들었습니다. 처음에는 전형적인 Monolithic /Layered 아키텍처로 구성된 플랫폼이었습니다. 당시엔 당연하게도 사용하는 유저가 저희밖에 없었기 때문에 이 구조로도 충분히 운영은 가능했습니다. 그런데 실제 국내 KREAM이나 해외 StockX와 같은 리셀 플랫폼들을 좀 더 깊게 파보다보니 생각이 달라졌습니다.
- 리서치해 본 결과, 리셀 플랫폼은 트래픽이 균일하게 들어오지 않았습니다. 한정판 신발이라든지 두쫀쿠(?) 같은 게 올라오면 특정 상품에 조회와 입찰이 짧은 시간에 몰리게 됩니다. 또한 해당 상품의 재고는 옵션(사이즈 270 등)당 1개라서 동시성 문제도 곧바로 거래 실패나 중복 체결로 이어지게 됩니다. 결국 "지금은 괜찮지~"과 "KREAM처럼 엄청 성장해도 괜찮은가?"는 완전 다른 문제였습니다.
- 그래서 저희는 이 플랫폼을 여러 개의 서비스로 쪼개보는 MSA 구조로 만들어가며, 여러 디자인 패턴을 익히고, 여러 기법들, 여러 기술들을 사용해 왔습니다.
- 그래서 저는 이 프로젝트를 정리하면서 MSA가 좋다고 소개하는 글이 아니라 아래와 같은 내용들을 적어보려고 합니다.
1. 각 과정에서 어떤 문제가 실제로 있었고,
2. 어떤 선택지를 놓고 고민했으며,
3. 왜 그 설계를 하게 되었고,
4. 어떤 실패가 있었고, 어떻게 트러블슈팅을 했는지,
5. 그래서 어떤 결과와 성능 개선이 있었는지
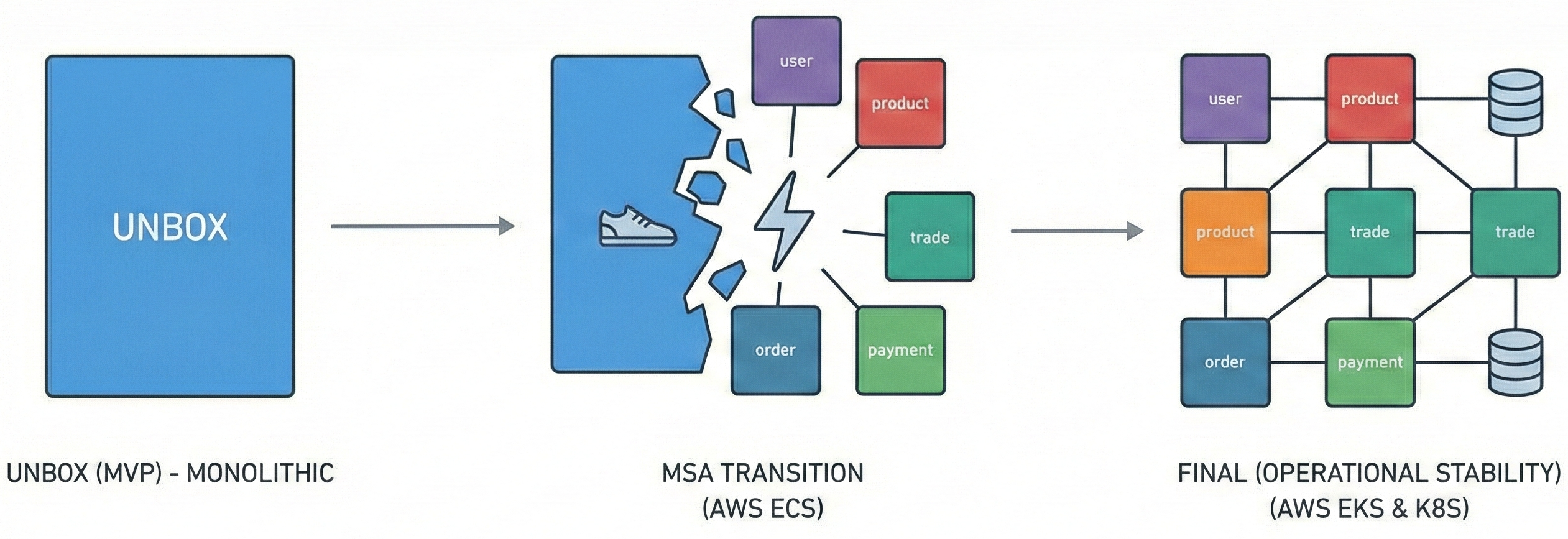
- 1차(MVP) → 2차(MSA 전환) → 최종(운영 안정화 단계)까지, 과정 전체를 작성해 볼 예정입니다. 그래서 조금은 길어질 수도 있겠다 싶은데 추후 글을 다 작성한 뒤, 글들도 MSA처럼 쪼개보도록 하겠습니다.
2. 왜 분리했을까?
- MSA는 Microservice 아키텍처입니다. 말 그대로 하나의 서비스를 작은, 마이크로한 서비스로 나눈다는 의미입니다. 그리고 이와 대비되는 Monolithic은 기능을 한 애플리케이션 안에 모아두는 방식입니다.
- UNBOX도 처음에는 Monolithic으로 시작했습니다. 그때는 MVP 단계였고, 사용자도 저희 팀뿐이었고, 기능 개발 속도도 빨라서 충분히 괜찮았습니다. 트랜잭션 같은 경우에도 한 DB 안에서 처리가 되기 때문에 흐름도 이해하기 쉽고, 디버깅도 단순하게 진행할 수 있었습니다.
- 그런데 단점도 여기서 나타났습니다. Monolithic 구조에서는 모든 기능의 흐름을 같은 애플리케이션의 리소스로 처리합니다. 상품 조회에 사용자가 몰리면 DB 커넥션 대기(DB 커넥션 풀 고갈 등)와 지연 시간이 같이 늘고, 그 영향이 주문이나 결제까지 번질 수 있습니다. 사용자 입장에서는 결제에서 오류가 난 것처럼 보일 수도 있겠지만, 실제로는 상품 조회 문제에서부터 이어진 장애가 전파될 수도 있다는 것입니다. 그래서 저희 팀이 가장 먼저 끊고 싶었던 건 바로 이 장애 전파였습니다.
- 동시성 문제도 결정적인 이유였습니다. UNBOX는 옵션당 재고가 1개에 가까운 거래가 많아서, 같은 시점에 요청이 몰리면 중복 거래나 상태가 불일치하는 문제가 바로 발생할 수 있습니다. 이런 문제가 하나 터지면, 뒤에 있는 취소, 환불, 정산까지 줄줄이 영향을 주게 됩니다.
- 운영 관점에서도 비효율이 컸습니다. 실제로 부하가 큰 구간은 Product 조회인데, Monolithic에서는 Product 서비스만 늘릴 수 없고 전체를 같이 늘려야 합니다.
- 배포도 마찬가지였습니다. 결제 쪽 코드를 아주 살짝만 수정해도 전체 서비스의 재배포가 필요해서 변경의 영향 범위가 너무 넓었습니다. 서비스가 커질수록 배포는 느려지고, 한 번의 수정 비용도 점점 더 커지는 구조였습니다.
- 마지막으로 협업 방식에도 한계가 있었습니다. 모두가 같은 코드베이스에서 모든 도메인을 함께 수정하는 방식은 지금 같은 바이브 코딩 시대에서는 굉장히 빠르지만, 규모가 커질수록 책임의 경계가 흐려질 수 있습니다. 장애가 났을 때 어디가 시작점인지, 누가 끝까지 책임을 가지고 복구할지 명확하지 않으면 기술 부채와 Code Conflict만 더 늘어나는 구조가 될 수 있습니다.

- 그래서 저희는 UNBOX를 User, Product, Trade, Order, Payment의 5개 서비스로 분리했습니다. 장애가 전파되지 않도록 하고, 필요한 서비스만 확장하고, 변경점도 작은 단위로 배포할 수 있게 하기 위해서입니다. 이 3가지 목표로 저희는 MSA 전환을 시작하게 되었습니다.
- 굳이 MSA 말고도 다른 방법(모듈러 모놀리스, 혹은 그냥 EDA만 가져가는 방법)도 있겠지만, MSA 구조로 가져가게 되면 위 목표들을 슬기롭게 풀어갈 수 있겠다고 생각해 선택했습니다.
3. 어떻게 분리했을까?
3-1. 도메인 경계(DDD)
- UNBOX를 나눌 때 정한 첫 원칙은 "기능이 아니라, 같은 규칙을 공유하는 '도메인'으로 나누자"였습니다.
- 초반에는 저희도 "조회가 많으니 Product부터 떼자", "결제는 외부 서비스랑 물려있으니 Payment를 먼저 따로 빼자" 같은 식으로 설계했었습니다. 그런데 이렇게 자르면 당장은 빨라 보여도, 나중에 책임이 꼬인다는 문제가 있었습니다.
- 그래서 경계를 정할 때 기능보다도 먼저 이런 질문들로 경계를 구체화시켰습니다.
1. 상태 변경이 한 서비스 안에서 닫히는 형태로 구현할 수 있나?
2. 실패했을 때는 어떤 서비스가 보상 처리(롤백 등)를 해야 하나?
3. 서로 다른 도메인을 객체 참조 없이 ID 참조로 끊을 수 있나?
4. 한 서비스 내에서 써야 하는 같은 단어를 팀원마다 다른 뜻으로 쓰고 있지 않나?
- 이 질문으로 후보를 좁힌 뒤에 최종적으로 User / Product / Trade / Order / Payment 5개 경계로 정리하게 되었습니다.
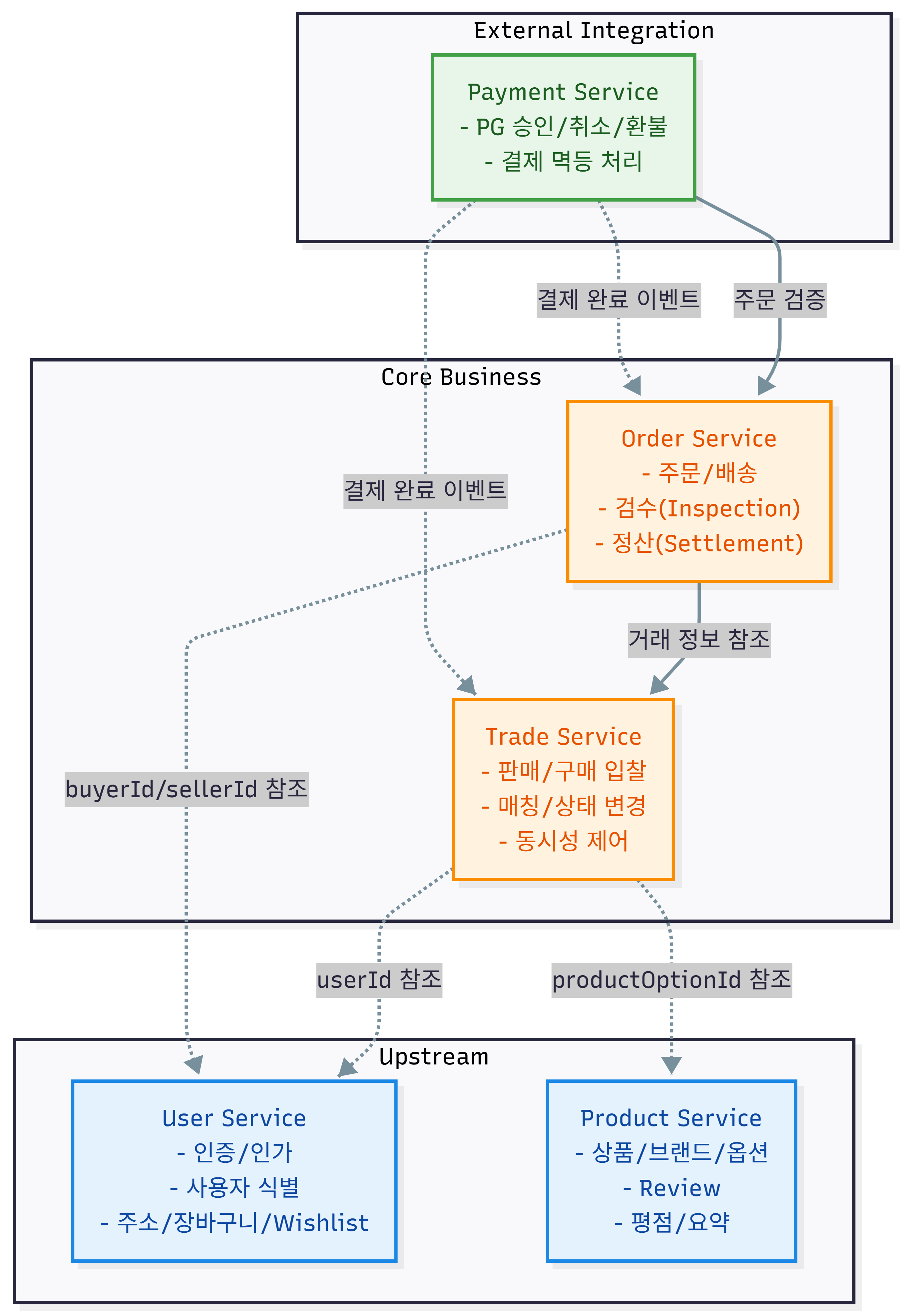
- 처음 후보에는 Review도 별도 경계로 올려놨습니다. 하지만 운영 관점에서 보면 리뷰는 상품과, 특히 상품 옵션과 강하게 붙어 있었고, 상품 조회를 최적화할 때에도 Product와 같이 가져가는 게 더 자연스러웠습니다. 그래서 2차에서는 Review를 Product 쪽에 포함시켰고, 필요하면 나중에 분리 가능한 후보로 남겨뒀습니다.
- 반대로 Inspection(검수)과 Settlement(정산)은 Order에 붙였습니다. 이 둘은 주문과 같이 움직이고, 그래서 상태 추적도 주문 쪽에 붙여야 쉽게 할 수 있을 거라 생각했기 때문입니다. 즉, 같은 규칙을 공유하는 기준으로 묶게 되었습니다.
3-1-1. 서비스의 책임
- 각 경계를 실제로 어떤 책임으로 구분했는지도 명확히 정해뒀습니다.
1. User 서비스는 인증/인가, 사용자 식별, 주소/장바구니/위시리스트 같은 개인 데이터의 뿌리를 담당한다.
2. Product 서비스는 상품/브랜드/옵션 같은 기준 데이터(마스터 데이터) 관리, 조회 중심 처리를 담당한다.
3. Trade 서비스는 판매/구매 입찰의 상태 변경과 매칭, 동시성 제어를 담당한다.
4. Order 서비스는 주문 생성 이후 배송/검수/정산의 운영과 이력을 관리한다.
5. Payment 서비스는 외부 PG 승인/취소/환불과 멱등 처리, 결제 실패 시 후속 처리를 담당한다.
- 이 책임을 나누는 것에서 저희가 가장 중요하게 본 기준은 "누가 이 기능을 쓰는가"가 아니라 "어떤 도메인을 다루는가"였습니다. UNBOX는 데이터 소유권과 상태를 변경하는 책임을 기준으로 경계를 정했고, 관리자와 일반 사용자의 구분은 도메인 분리가 아니라 인증/인가 정책으로 처리했습니다.
- 예를 들어 상품 등록, 상품 조회, 상품 수정은 호출 주체가 누구든 간에 모두 Product 도메인입니다. 관리자가 호출하든 사용자가 호출하든, 바뀌는 건 권한 체크지 도메인 자체가 아니었습니다. 그래서 보안은 서비스를 물리적으로 쪼개는 방식이 아니라 앞단의 인증/인가 Layer에서 처리했습니다.
- 예시로 정리하면 이렇습니다.
- POST /admin/products(관리자 상품 등록) → Product 도메인
- PATCH /admin/products/{id}(관리자 상품 수정) → Product 도메인
- GET /products/{id}(사용자 상품 조회) → Product 도메인
- POST /orders(주문 생성) → Order 도메인, 단 Product에서 productId 참조만 수행
- 즉, "Admin API니까 Admin 서비스로 분리"가 아니라, 상품을 다루는 거면 Product 서비스에서 책임을 지는 게 저희의 결론이었습니다. 패키지를 물리적으로 더 쪼갠다고 보안이 강해지지는 않는다는 것을 알게 되었고, 권한 제어는 Spring Security의 URL 패턴과 메서드의 권한으로 관리하는 게 더 정확했습니다.
3-1-2. Layered Architecture

- DDD에서의 대표적인 아키텍처는 크게 Layered, Clean, Hexagonal이 있습니다.
- UNBOX는 MSA로 서비스를 분리하면서도, 서비스 내부 구조는 모놀리식 때와 동일하게 Layered 아키텍처를 유지했습니다. 이유는 MSA 전환에서의 가장 큰 목표가 "서비스 경계와 통신을 안정적으로 분리하는 것"이었고, 내부 아키텍처까지 동시에 크게 바꾸면 문제 원인을 추적하기 어려워지기 때문이었습니다.
- MVP 단계부터 Layered를 사용해왔기 때문에 팀의 공통적인 이해가 이미 깔려있었고, 이 구조를 유지하면 분리 과정에서의 학습 비용과 리팩토링 리스크를 줄일 수 있었습니다. 특히 서비스를 동시에 여러 개 쪼개고, Feign/Kafka/배포까지 같이 고려해야 했던 2차 일정에서는 익숙한 내부 구조와 새로운 서비스 경계의 조합이 가장 현실적이었다고 생각합니다.
- Clean이나 Hexagonal 아키텍처는 장점이 분명하지만, 모든 서비스에 같은 수준으로 전면적으로 적용하면 오버 엔지니어링이 될 수 있다고 판단했습니다. UNBOX도 도메인 복잡도가 서비스마다 달랐습니다. Product와 User는 비교적 단순한 조회/관리 성격이 강했고, Trade/Order/Payment는 상태 변경과 외부 연동이 있어서 복잡도가 높았습니다. 그래서 "전체 일괄 적용" 대신, Layered를 기본으로 유지하고 필요한 지점에만 아키텍처 강도를 높였습니다.
# Order Service의 디렉토리 예시
unbox_order
├─ common
│ ├─ client
│ └─ config
├─ order
│ ├─ presentation
│ ├─ application
│ └─ domain
└─ settlement
├─ presentation
├─ application
└─ domain- 리셀 플랫폼 관점에서 보면, UNBOX에 당장 필요했던 건 "장애를 빨리 막고, 원인을 빨리 찾고, 안정적으로 배포하는 구조"였습니다. 그래서 내부 구조는 요청 흐름이 명확한 Layered로 유지하고, 서비스 경계와 통신 안정화(Feign, Kafka, 재시도, 타임아웃)에 집중하는 편이 더 맞았습니다. Layered는 presentation → application → domain의 흐름이 단순해서, 장애 시 어느 레이어에서 문제가 났는지 추적이 빠르고, 팀원이 바뀌어도 프로젝트 이해가 쉽다는 장점이 있었습니다.
- 또한 UNBOX처럼 도메인별 복잡도가 다른 플랫폼에서는 "모든 서비스의 동일 아키텍처"가 오히려 비효율이 될 수 있습니다. Product/User는 조회/관리 중심이라 과한 추상화보다는 명확한 계층의 분리가 더 실용적이었고, Trade/Order/Payment는 상태 변경과 외부 연동이 많아 더 강한 경계의 관리가 필요했습니다. 그래서 내부는 Layered를 기본으로 두고, 복잡한 지점에서만 멱등, 보상, 이벤트, 어댑터 패턴을 추가하는 방식이 운영상 더 안정적이었습니다.
- Clean/Hexagonal을 안 쓰는 게 맞다기보다, 현업에서는 전면적인 적용이 어려운 이유가 있다고 생각합니다. 포트/어댑터/인터페이스가 빠르게 늘어나고, 단순한 도메인까지 같은 정도로 추상화하면 코드량과 학습 비용이 커질 수 있습니다. 작은 팀이나 촉박한 일정에서는 이 비용이 기능 개발 속도를 떨어뜨리고, 디버깅 때도 호출 경로가 길어져 원인 파악이 느려질 수 있습니다. 그래서 실무에서는 결제/정산처럼 외부 의존성과 변경 가능성이 큰 영역에만 선택적으로 적용하는 경우가 많고, UNBOX도 그런 현실적인 전략을 선택하게 되었습니다.
3-1-3. 유비쿼터스 언어

- DDD에서 많이 얘기하는 유비쿼터스 언어(UL)도 정리하게 되었습니다. 이 작업을 초반에 하지 않으면 서비스가 늘어날수록 API Contract가 쉽게 깨지고, 같은 용어를 서로 다른 뜻으로 쓰게 될 수도 있습니다.
- 이렇게 정리해두고 나니 추후 장애를 분석할 때 이 장애는 어느 부분에서 났고, 이 상태는 어느 서비스 것인지가 바로 보였기 때문에 상태 추적과 소통에 굉장히 유리했습니다.
- 서비스 간 의존 방향도 처음부터 고정했습니다. 이를 DDD에서는 Upstream/Downstream이라고 보통 얘기하는데, 쉽게 말하면 데이터를 주는 쪽과 받는 쪽이라고 보시면 됩니다. 그래서
- User, Product는 기준 데이터를 제공하는 쪽
- Trade, Order는 그 기준 데이터를 소비하는 쪽
- Payment는 외부 PG의 복잡성을 내부에서 가져가고 결과만 전달하는 쪽으로 설계해뒀습니다.
3-1-4. 코드에서의 분리
- 마지막으로 설계 문서뿐만 아니라 코드에서도 이 분리 규칙을 적용해보려고 많은 노력을 기울였습니다.
- 객체 참조 대신 ID 참조 - @ManyToOne User처럼 서비스끼리 직접 물고 있던 관계를 buyerId, sellerId, productOptionId 같은 ID 참조 형식으로 바꿨습니다.
- 다른 도메인의 Repository 직접 호출 금지 - 필요한 데이터는 Client 인터페이스와 전용 DTO로만 받게 했습니다.
- 공통 사항은 최소한만 공유 - 응답 포맷, 에러 코드, 이벤트처럼 정말 공통인 것만 공유하고, 도메인별 규칙은 공유 모듈로 올리지 않고, 각 서비스 내부에 유지시켰습니다.

- 특히 서비스 분리를 준비하면서 저희가 가져간 건 ID 참조와 스냅샷 전략이었습니다. 생성 시점에는 Product/User를 클라이언트로 호출해서 유효성을 검증하고, 주문에 필요한 값(상품명, 옵션명, 가격, 이미지 등)은 그 시점 값으로 스냅샷 저장했습니다. 조회 시점에는 다른 서비스를 다시 호출하지 않고 스냅샷만 사용했습니다.
- 주문은 과거 시점의 기록이기 때문에, 원본 상품이 바뀌거나 삭제되어도 주문 내역은 당시 정보가 유지되어야 합니다.
- 예를 들어 350만 원에 결제한 주문이 한 달 뒤 상품 가격이 330만 원으로 내려갔다고 해서 주문 내역까지 330만 원으로 보이면 안 됩니다.
- 스냅샷 없이 조회마다 Product를 호출하면 과거의 데이터가 흔들리고, Product의 장애가 Order의 조회 장애로 번지는 문제도 생깁니다.
- 다만 모든 도메인에 똑같이 적용하지는 않았습니다. 주문은 스냅샷이 맞지만, 장바구니는 구매 전 단계라 최신성이 더 중요합니다. 그래서 장바구니는 최신 조회(배치/Bulk 조회를 하거나 이벤트로 동기화하자 !) 관점으로 설계 우선순위를 따로 잡았습니다.
3-2. 순차적인 분리
- 저희는 처음에 물리적인 분리 전에 논리적인 분리부터 끝내고자 했습니다. 처음부터 서비스를 한 번에 찢어버리면, 장애가 났을 때 원인이 설계 문제인지, 통신 문제인지, 배포 설정 문제인지 분간이 안 된다고 판단했습니다. 그래서 저희 팀은 아래 순서로 분리를 진행했습니다.
1. 서비스 간 호출 계약(Feign) 먼저 고정
2. 공통 모듈(unbox_common) 정리
3. 서비스를 물리적/순차적으로 분리
4. 이벤트 흐름 검증(EventListener)
5. Kafka 전환 + 재처리 시스템(DLT 등) 구축
3-2-1. 왜 Feign 먼저?
- 저희는 서비스를 실제로 나누기 전에, 먼저 서비스 간 API 스펙부터 맞췄습니다.
- 쉽게 말해 "어떤 URL로, 어떤 값들을 보내고, 어떤 응답을 받는지"를 먼저 통일하게 되었습니다. 이걸 먼저 안 하고 물리적으로 서비스부터 쪼개면 디버깅이 어려워진다는 문제가 있었습니다. 그래서 먼저 동기 호출이 필요한 구간을 확정한 뒤에, RestTemplate, WebClient, OpenFeign을 비교해서 OpenFeign을 선택했고, 그 후 모놀리식 코드를 Feign 형태로 바꿨습니다.
- 특히 주문 생성 시 유저/상품 유효성 확인, 입찰 선점(LIVE → RESERVED) 같은 즉시 상태 변경, 결제 전 주문/금액 검증 같은 구간은 동기 통신 방식으로 고정하게 되었습니다. 이 흐름들은 "지금 이 요청이 성공인지 실패인지"가 바로 확정돼야 다음 단계로 넘어갈 수 있기 때문입니다.
- 이 단계에서 내부 API 경로(/internal/...)를 통일하고, 요청/응답 DTO도 호출하는 쪽 기준으로 다시 정리했습니다. 예를 들어 Trade 쪽 선점 API는 아래처럼 Feign 인터페이스로 먼저 고정했습니다.
// Order Service - Feign 인터페이스 (동기 호출)
@FeignClient(name = "unbox-trade", url = "${trade-service.url}", path = "/trade")
public interface TradeClient {
@PostMapping("/internal/bids/selling/{sellingBidId}/reserve")
void reserveSellingBid(@PathVariable UUID sellingBidId,
@RequestParam("updatedBy") String updatedBy);
}- 여기서 url을 설정값으로 분리한 이유는 환경 차이 때문입니다. 로컬에서는 localhost를 쓰고, Dev 환경에서는 ECS Service Connect 내부 DNS를 써야 해서(trade.unbox.local), 주소를 하드코딩하지 않고, 환경변수(TRADE_SERVICE_URL)로 주입하는 방식으로 맞췄습니다.
- 그리고 주문 생성 로직에서는 이 인터페이스를 호출해서, 검증과 선점을 바로 동기 처리했습니다.
// Order Service - 주문 생성 시 즉시 검증하고 입찰 선점하기
@Transactional
public UUID createOrder(OrderCreateRequestDto requestDto, Long buyerId) {
// CASE 1: 판매 입찰 기반 주문
if (requestDto.getSellingBidId() != null) {
bidIdForRollback = requestDto.getSellingBidId();
// 1) 구매자 조회
UserInfoForOrderResponse buyer =
userClient.getUserInfoForOrder(buyerId);
// 2) 판매 입찰 정보 조회
SellingBidForOrderResponse sellingBidInfo =
tradeClient.getSellingBidForOrder(requestDto.getSellingBidId());
...
// 5) 판매 입찰 선점 (LIVE → RESERVED)
tradeClient.reserveSellingBid(
sellingBidInfo.getSellingBidId(),
"ORDER_SERVICE"
);
...
order = orderRepository.save(order);
return order.getId();
}- 결과적으로 서비스를 실제로 분리할 때는 비즈니스 로직을 바꿀 필요없이 연결 지점만 바꾸면 되게 만들어서, 분리할 때의 리스크도 크게 줄일 수 있었습니다.
3-2-2. OpenFeign
- 앞서 동기 호출이 필요한 구간을 정리하면서, 이미 HTTP 통신 라이브러리는 RestTemplate, WebClient, OpenFeign 세 가지로 좁혀둔 상태였습니다. 여기서 제가 초점을 둔 건 지금 분리 작업을 하면서, 팀 전체가 같은 방식으로 빨리 맞춰 갈 수 있느냐였습니다.
- RestTemplate은 Spring 내장 클래스이기 때문에 처음에 붙이기는 쉽지만, 서비스가 늘어나면 URL 문자열 조합, 헤더 전달, 에러 처리 코드가 서비스마다 반복되는 문제가 있습니다. 실제로 코드가 금방 흩어지고, 수정할 때 빠지는 지점이 생기기 쉬웠습니다.
- WebClient도 검토하긴 했지만, 당시 저희가 급한 건 리액티브 최적화가 아니라 주문/입찰/결제 검증처럼 바로 성공/실패를 확정해야 하는 흐름을 안정적으로 붙이는 일이었습니다. 그 시점에는 복잡도 대비 이점이 크지 않았습니다.
- 그래서 OpenFeign을 선택하게 되었습니다. 이유는 호출 형태를 인터페이스로 고정할 수 있었고, /internal/... 경로를 서비스별로 통일하기 쉬웠습니다. 또 타임아웃, 서킷브레이커, 에러 디코딩 같은 공통 설정을 한 번에 맞출 수 있었습니다. 운영 환경 차이도 TRADE_SERVICE_URL 같은 환경변수로 처리해서, 로컬(localhost)과 Dev(ECS Service Connect 내부 DNS) 전환을 코드 수정 없이 가져갈 수 있었습니다.
- 정리하면 OpenFeign은 분리 작업을 빠르게 맞추기 가장 현실적인 선택이었습니다. 초기 장애 처리 방식에서 생긴 문제와, 이걸 어떻게 안정화했는지는 다음 절에서 설명하겠습니다.
3-2-3. Resilience 패턴
- 저희가 먼저 동기 호출 구간을 정리한 이유는 MSA로 쪼개게 되면 기능 자체보다 실패를 어떻게 다룰지가 더 빨리 문제로 터지기 때문입니다. 실제로 운영되는 서비스에서는, 그리고 특히 MSA 구조에서는 성공보다 실패를 어떻게 다루는지가 더 중요한 것 같습니다.
- 특히 UNBOX는 검증하는 동기 호출이 꽤 있어서, 장애가 나도 중복 처리 없이 빠르게 실패하고 원인을 구분할 수 있어야 했습니다.
- 동기 호출에서는 재시도(Retry) 전략을 따로 두지는 않았습니다. 이유는 reserveSellingBid처럼 상태를 바꾸는 API에 재시도를 걸면 중복 처리 위험이 커지기 때문이라고 판단했기 때문입니다.
- 그래서 저희는 Timeout + Circuit Breaker + Fallback 조합으로 보호하고, 재시도는 빼는 쪽을 선택했습니다. 대신 재처리가 필요한 부분은 Kafka Consumer나 Outbox 릴레이 같은 비동기 구간에서 처리하도록 역할을 나눴습니다.
- 이 전략으로 설계하던 중, 팀원들 사이에서 타임아웃 체인 문제가 나올 수도 있지 않냐는 피드백을 받았습니다. Trade → Payment를 동기로 호출하는데 Trade 서비스의 타임아웃이 더 짧으면, 실제 결제는 성공했는데 Trade는 실패로 처리하는 상황이 생길 수 있다는 지적이었습니다. 이건 장애보다 더 위험한 데이터 불일치라서 우선순위를 높여 바로 수정하게 되었습니다.
- 그래서 호출하는 쪽 타임아웃이 호출받는 쪽보다 길어야 한다는 원칙을 지켜서 타임아웃 전략을 수정했습니다. 기본값은 connect 1초 / read 3초로 두고, User/Product는 read 5초, PG 연동이 포함된 Payment는 read 10초로 분리했습니다. 그리고 이 원칙을 맞추기 어려운 흐름은 동기 호출을 줄이고 이벤트 기반으로 넘겼습니다.
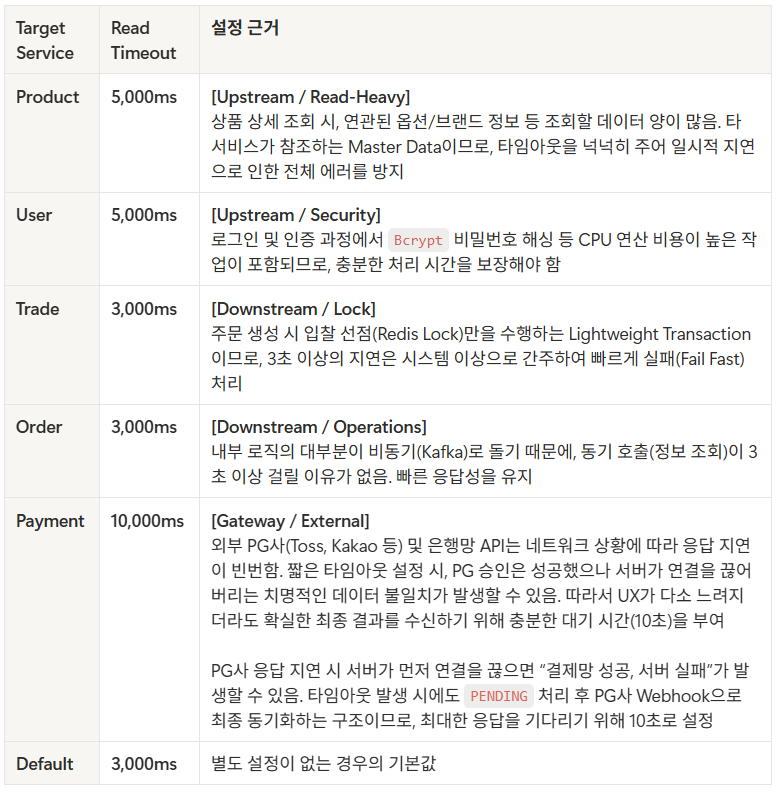
- 특히 Payment는 타임아웃이 나도 바로 확정 실패로 닫지 않고 PENDING으로 두고, PG Webhook으로 최종 상태를 동기화하는 흐름까지 같이 설계했습니다.
- 서킷 브레이커도 이렇게 세세하게 설계했습니다.
resilience4j:
circuitbreaker:
configs:
default:
slidingWindowType: COUNT_BASED
slidingWindowSize: 10
minimumNumberOfCalls: 5
failureRateThreshold: 50
slowCallDurationThreshold: 3s
waitDurationInOpenState: 10s
ignoreExceptions:
- com.example.unbox_common.error.exception.CustomException- slidingWindowSize=10, minimumNumberOfCalls=5는 표본이 너무 적을 때 오탐으로 서킷이 열리는 걸 줄이기 위한 값입니다.
- failureRateThreshold=50은 절반 이상 실패하면 비정상으로 보겠다는 기준이고, slowCallDurationThreshold=3s + slowCallRateThreshold=80은 가끔 느림이 아니라 대부분 느림일 때만 서킷을 열기 위한 설정입니다.
- 그리고 waitDurationInOpenState=10s, permittedNumberOfCallsInHalfOpenState=3은 복구 확인을 너무 성급하게 하지 않기 위한 값입니다.
- 마지막으로 CustomException을 제외한 이유는 도메인 에러 때문에 서킷이 열리지 않게 하기 위해서였습니다.
// 초기 방식
@Override
public void reserveSellingBid(UUID sellingBidId, String updatedBy) {
throw new CustomException(ErrorCode.SERVICE_UNAVAILABLE);
}- Fallback 처리도 초반과 달리 지금은 예외를 나눠 처리하게 되었습니다. 초기에 Fallback을 단순하게 설정했을 때는, 원인을 보지도 않고 무조건 SERVICE_UNAVAILABLE(503)을 던졌습니다. 그래서 원래는 이미 선점된 입찰과 같이 비즈니스 오류(400이나 409)여도 호출한 쪽에서는 전부 503으로 보였습니다.
- 이걸 구분하기 위해 FallbackFactory를 도입하게 되었습니다.
1. FeignClientException이면 비즈니스 예외 그대로 전파
2. CallNotPermittedException(서킷 오픈)이면 503
3. 그 외 네트워크/타임아웃도 503
private void handleFallback(String methodName, Object param, Throwable cause) {
if (cause instanceof FeignClientException feignEx) {
throw feignEx; // 비즈니스 예외는 유지
}
if (cause instanceof CallNotPermittedException) {
throw new CustomException(ErrorCode.SERVICE_UNAVAILABLE); // 장애 상황은 503
}
throw new CustomException(ErrorCode.SERVICE_UNAVAILABLE);
}- 그다음 GlobalFeignErrorDecoder로 응답 파싱 형식도 통일했습니다.
- 상대 서비스가 던져준 에러 JSON(status, message, data)을 읽어서 FeignClientException으로 바꿔주기 때문에, 호출 서비스에서 에러 형태가 일정해질 수 있었습니다.
- 결과적으로 도메인 전용 오류는 도메인 오류로 남고, 실제 장애(서킷 오픈/타임아웃)만 503으로 처리되게 정리됐습니다. 디버깅도 빨라졌고, 프론트에 전달되는 에러의 의미도 훨씬 정확해졌습니다.
3-2-4. 공통 모듈(unbox_common)
- 동기 호출 구조를 먼저 튼튼하게 하고, 제가 바로 손본 건 공통 모듈의 정리였습니다.
- 여기서 제가 좀 헷갈렸던 건, '멀티 레포'였습니다. 처음에는 GitHub 상에서의 레포를 서비스별로 쪼개는 건 줄 알았습니다. 그래서 공통으로 필요한 코드는 따로 레포를 생성해 이를 JitPack이라는 툴로 배포(라이브러리 형태)했고, 각 서비스가 가져오는 구조로 진행했습니다. 실제로 분리 자체는 잘 진행되었습니다.
- 문제는 개발 속도였습니다. 공통 코드가 바뀔 때마다 버전이 바뀌어서 올라가고, 배포가 될 때까지 기다리고, 또 각 서비스의 build.gradle에서 버전 갱신하고, 다시 테스트해야 했습니다. 프로젝트에서 이 사이클이 반복되다보니 개발보다 동기화하는 비용이 더 크게 느껴졌습니다. 특히 로컬 Docker 환경에서 통합 테스트를 돌릴 때, 공통 모듈이 작게라도 수정되면, 연쇄적으로 다시 빌드해야 해서 개발 병목이 확실히 느껴졌습니다.
- 그래서 조금 더 멀티 레포에 대해 공부해 본 결과, "프로젝트를 Git으로 쪼개는 것"이 아니라 "프로젝트는 하나로 두고 모듈로 나누는 것"이 지금 상황에선 낫겠다고 판단했습니다. 즉, 단일 레포의 멀티모듈로 전환했고, 각 서비스가 unbox_common을 프로젝트 의존으로 직접 참조하게 바꿨습니다.
// unbox_common의 build.gradle
dependencies {
// JPA
api 'org.springframework.boot:spring-boot-starter-data-jpa'
// Spring Security
api 'org.springframework.boot:spring-boot-starter-security'
// Validation
api 'org.springframework.boot:spring-boot-starter-validation'
// Web
api 'org.springframework.boot:spring-boot-starter-web'
...
}- 여기서 또 하나 배운 점이 implementation과 api의 차이였습니다. unbox_common의 build.gradle을 보면 java-library 플러그인 위에서 공통 의존성을 api로 열어두고 있습니다. 이렇게 하면 각 서비스 모듈에서 공통 의존성을 다시 선언하지 않아도 잘 전달돼서, 서비스 쪽 build.gradle이 단순해지고 초기 분리 속도가 빨라질 수 있습니다.
- 대신 단점도 분명했습니다. api를 많이 열어두면 공통 모듈이 무거워지고 의존성도 넓게 전파됩니다. 결국 unbox_common을 자주 건드릴수록 여러 서비스가 같이 다시 빌드되고, Docker 이미지 재생성 시간도 길어졌습니다. 저희가 로컬 통합 테스트에서 계속 느낀 병목이 바로 이 지점이었습니다.
- 그래서 공통 모듈에 넣는 코드의 기준을 고정하게 되었습니다.
- JWT/보안, 공통 응답/에러 포맷, Feign의 에러 디코더, 이벤트 DTO 같은 "계약/기반" 성격의 코드는 공통 모듈에 넣고,
- 주문 상태 전이, 입찰 선점 규칙, 도메인별 규칙 같은 것들은 넣지 않고, 각 서비스에 들어가도록 했습니다.
- 그리고 서비스별 타임아웃/서킷 같은 운영 설정도 common으로 묶지 않고 각 서비스에서 관리하도록 분리했습니다.
3-2-5. 서비스의 순차적인 분리
- 이제 본격적으로 서비스를 나누기 시작했습니다 !! 저희는 서비스를 한 번에 찢지 않고 순서대로 분리했습니다. 실제 분리 순서는 Product → Trade → Order → Payment → User 순이었습니다.

- 먼저 Product를 1순위로 잡은 건 기준 데이터의 성격이 가장 명확했기 때문입니다. Product는 다른 서비스를 거의 참조하지 않는 Upstream이고, 반대로 Trade/Order/Wishlist가 참조하는 공통 키(optionId, productId)를 제공하는 쪽이라서, 여기부터 떼면 나머지 서비스를 "객체 참조"에서 "ID 참조"로 변경하기가 쉬웠습니다. 실제로 Product를 떼는 과정에서 서비스끼리의 DB Join 의존도를 많이 걷어냈고, 이후 분리 난이도를 낮출 수 있었습니다.
- 두 번째는 Trade였습니다. 리셀 도메인에서 가장 먼저 터지는 건 입찰/체결 구간의 동시성 문제라서, Trade를 독립 서비스로 분리해 락과 상태 전이를 따로 다루는 게 우선이라고 판단했습니다. 이 단계에서 프로젝트 구조를 위에서 얘기했던 모노레포로 정리하면서 settings 충돌, 모듈 인식 오류 같은 인프라 트러블슈팅도 같이 했고, 결과적으로 Trade는 Product를 ID 기반으로만 참조하도록 경계를 맞출 수 있었습니다.
- 세 번째는 Order였습니다. 주문 생성 시점에 User/Trade를 직접 참조하고 있던 결합을 끊어야 했고, 주문-검수-정산 파이프라인도 따로 결합시키는 게 필요했습니다. 그래서 엔티티 직접 참조를 ID 참조로 바꾸고, 내부 API와 DTO를 서비스별로 다시 나눴습니다. 이 작업이 끝나고 나서야 Payment가 Order를 안정적으로 검증할 수 있는 기반이 갖춰졌습니다.
- 네 번째는 Payment였습니다. Payment는 외부 PG 연동 특성상 장애 전파를 끊는 게 핵심이라 분리 자체는 중요했지만, Order/Trade 경계가 먼저 정리되어 있어야 결제 성공/실패 후 후속 상태 전파를 안전하게 붙일 수 있었습니다. 그래서 실행 순서에서는 Payment를 Order 뒤로 배치했고, 이때 멱등성 키, 트랜잭션 분리, 이벤트 발행 안정성 같은 결제에 특화된 문제를 집중적으로 정리했습니다.
- 마지막은 User였습니다. 당시에는 인증/인가가 모든 서비스를 가로지르다 보니 변경의 영향 범위가 너무 커서, 거래 흐름을 먼저 안정화한 뒤에 User를 떼는 쪽을 택했습니다. (사실 User는 나머지 서비스가 다 떨어지고 남은 잔재들을 정리하는 과정만 거쳤습니다.) 대신 User가 늦게 분리되니 통합 테스트에서 인증 흐름이 매끄럽지 않았고, 서비스별 단위 테스트는 가능해도 실제 E2E는 계속 우회하거나 수동으로 검증하는 비중이 커졌습니다.
- 그래서 서비스를 순차적으로 분리하는 건 중요하지만, 인증이나 식별 과정처럼 전 서비스 공통으로 깔리는 기반은 너무 늦게 떼면 테스트 비용이 증가한다는 것을 알게 되었습니다. 다음에 이런 작업을 한다면 User 전체를 먼저 떼는 건 아니더라도, 최소한 인증/토큰 검증이라도 초반에 독립시켜 두고, 나머지를 순차적으로 분리하는 방식이 더 현실적이라고 판단했습니다.
3-2-6. 분리 후 비동기 구조 정리
- 서비스를 순서대로 분리하고 나서 저흰 바로 Kafka를 붙이지는 않았습니다. 먼저 "이벤트를 어디서 발행하고, 누가 받아서 어떤 상태를 바꾸는지"부터 팀 안에서 맞추는 게 우선이었습니다. 이 단계에서 쓴 방식이 ApplicationEventPublisher + @EventListener였습니다.
- 이 조합은 브로커 없이도 이벤트 Pub/Sub 구조를 바로 만들 수 있어서, 인프라 세팅보다 도메인 흐름을 검증하는 데 집중할 수 있기 때문입니다. 즉, 이벤트 이름이 맞는지, payload에 어떤 필드가 필요한지, 발행 시점이 맞는지 같은 부분을 빠르게 맞춰볼 수 있었습니다.
- 저희는 처음부터 모든 흐름을 바꾸지 않고, 기존 동기 호출 중에서 사이드 이펙트 성격이 강한 것부터 2개 정도만 먼저 옮겨 검증했습니다.
- 첫 번째는 주문 취소 흐름이었습니다. 기존에는 주문 취소 시 Trade 쪽 상태 복구를 동기로 붙여 처리했는데, 이를 OrderCancelledEvent로 분리해 비동기 처리로 바꿨습니다.
- 두 번째는 환불 요청 흐름이었습니다. OrderRefundRequestedEvent를 기준으로 Payment/Trade 후속 처리가 이어지도록 바꿔서, "누가 시작점이고 누가 후속 처리자인지"를 분명히 했습니다.
- 이 과정에서 이벤트 스키마도 같이 정리했습니다. 실제로 orderId, sellingBidId, buyingBidId, paymentId, reason처럼 후속 서비스가 꼭 필요로 하는 최소 필드만 남기고, 서비스 내부 객체를 그대로 넘기는 방식은 버렸습니다. 이 정리가 나중에 Kafka 토픽 설계(order-events, payment-events)로 바로 이어지게 되었습니다. (이 과정이 정말 어려웠던 것으로 기억됩니다...)
- 또 한 가지 중요한 점은 발행 타이밍이었습니다. DB 작업이 끝나기 전에 이벤트를 먼저 쏘면, 롤백 시점에 유령 이벤트가 생길 수 있어서 발행 시점을 커밋 이후로 맞추는 원칙을 잡았습니다. 이 원칙 덕분에 MSA 전환 이후에도 상태 불일치들을 줄일 수 있었습니다.
- 물론 이렇게 했어도 한계는 존재했습니다. 인메모리의 이벤트는 프로세스가 죽으면 유실될 수 있고, 여러 인스턴스로 늘었을 때 이벤트 전달을 보장하는 것이나 재처리가 어렵습니다.
- 그래서 여기까지는 '분리 후 이벤트 흐름을 먼저 검증했다'까지를 마무리하고, Kafka 브로커 기반 전달 과정과 재처리(DLT 포함)는 다음 글의 Kafka 전환 과정에서 이어서 작성하겠습니다.
글이 굉장히 길어지는 것 같아 여기선 서비스를 나누는 과정까지만 다루고, 그 다음 글에서부터 Kafka 전환 과정에 대해 상세히 적어보도록 하겠습니다 ! 긴 글 봐주셔서 감사합니다 😉
728x90
LIST